Clear Sky Science · nl
Pseudo-dieptegebaseerd diepe neurale netwerkmodel voor objectdetectie
Waarom het belangrijk is camera's diepte te leren
Moderne camera's en telefoonapps worden steeds beter in het herkennen van mensen, auto’s en andere objecten, maar ze kijken meestal alleen naar platte kleurbeelden. Dit artikel stelt een eenvoudige vraag met grote gevolgen: wat als we gewone camera's een gevoel voor diepte kunnen geven, een ruwe 3D-ervaring, zonder extra sensoren of dure hardware? Door vanuit een enkele foto een gefingeerde diepteweergave te maken en die aan bestaande AI-systemen te leveren, laten de auteurs zien dat objectdetectie in alledaagse scènes merkbaar nauwkeuriger kan worden.
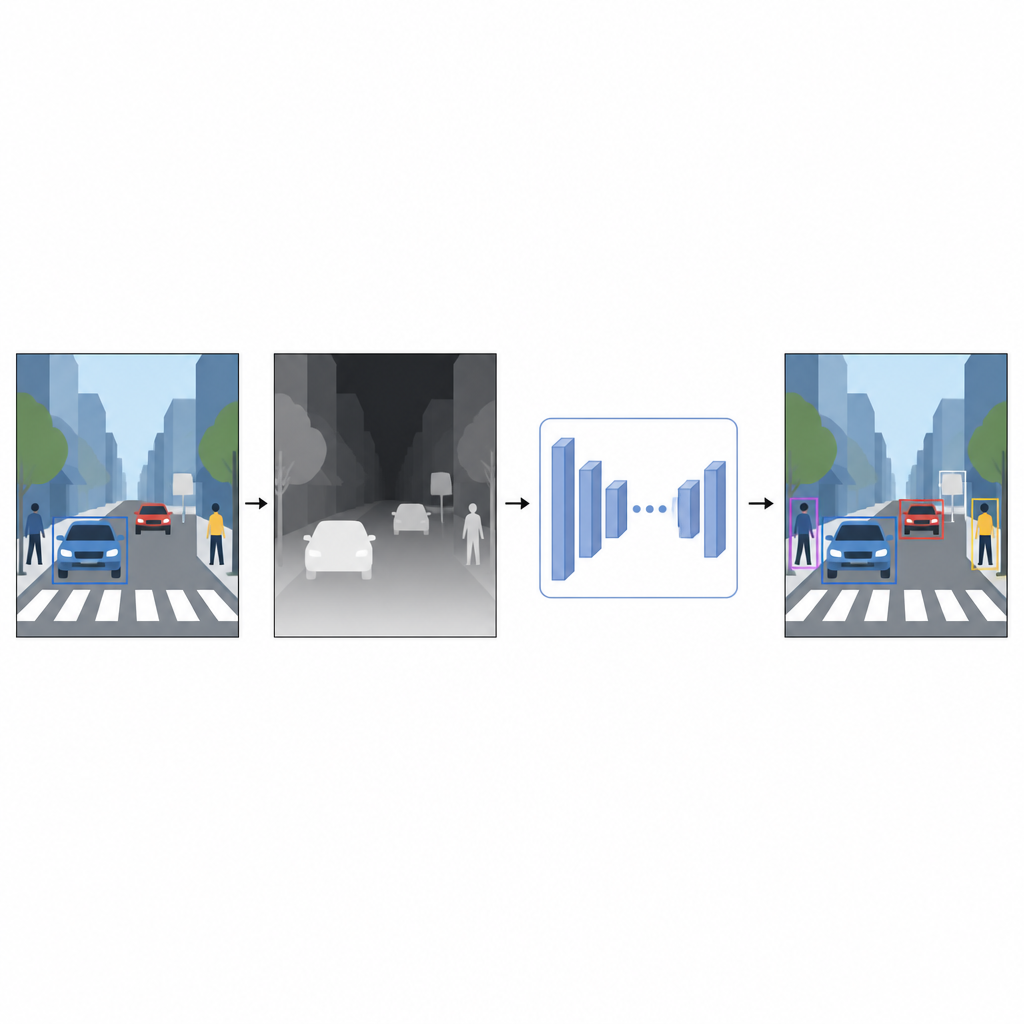
Van platte plaatjes naar een gevoel van afstand
Alledaagse foto’s leggen kleur en textuur vast maar niet hoe ver dingen weg zijn. Voor een computer kunnen een felrode auto en een rode muur verwarrend vergelijkbaar lijken wanneer ze in een 2D-afbeelding overlappen. Diepte-informatie, zelfs als die ruw is, helpt voorgrond van achtergrond te scheiden en objectgrenzen te verduidelijken. In plaats van te vertrouwen op speciale apparatuur zoals laserscanners of stereocamerarigs, gebruiken de auteurs een techniek die monoculaire diepteinschatting heet. Een apart AI-model neemt één kleurbeeld en voorspelt een dichtheidsdieptekaart, een grijs patroon waarin elke pixel aangeeft hoe dichtbij of ver dat punt in de scène zou kunnen zijn.
Een virtuele dieptesensor van software
Om deze pseudo-dieptenkaarten te genereren gebruikt de studie een geavanceerd diepte-inschattingsnetwerk dat in twee fasen wordt getraind. Eerst leert het van grote verzamelingen synthetische scènes, waarin perfecte diepte gemakkelijk te verkrijgen is. Daarna verfijnt het zijn vaardigheden op echte beelden die automatisch zijn gelabeld met behulp van een sterk teacher-model. Deze trainingsstrategie stelt het dieptenetwerk in staat lastige situaties aan te kunnen, inclusief weinig licht, transparante objecten zoals glas en dunne structuren zoals palen of stoelpootjes. De resulterende pseudo-dieptenkaarten bieden vloeiende, pixelniveau-hints over de vorm van de scène die het originele kleurbeeld aanvullen.
Twee parallelle weergaven die samenwerken
Zodra elke afbeelding zowel een kleurversie als een pseudo-diepteversie heeft, voeren de auteurs ze in een detectienetwerk met twee takken. De ene tak verwerkt het gebruikelijke kleurbeeld, terwijl de andere tak de dieptekaart verwerkt, waarbij in beide paden hetzelfde type neurale netwerk-backbone wordt gebruikt. Op verschillende tussenliggende lagen worden de featuremaps van de twee takken aan elkaar gekoppeld en verder verfijnd. Deze fusie in het middenstadium stelt het model in staat te behouden wat specifiek is aan kleur- en dieptecues, terwijl het ook leert hoe ze op elkaar inwerken. De samengevoegde features gaan vervolgens naar een standaard detectiekop die vakjes en labels voor de objecten in de scène produceert.
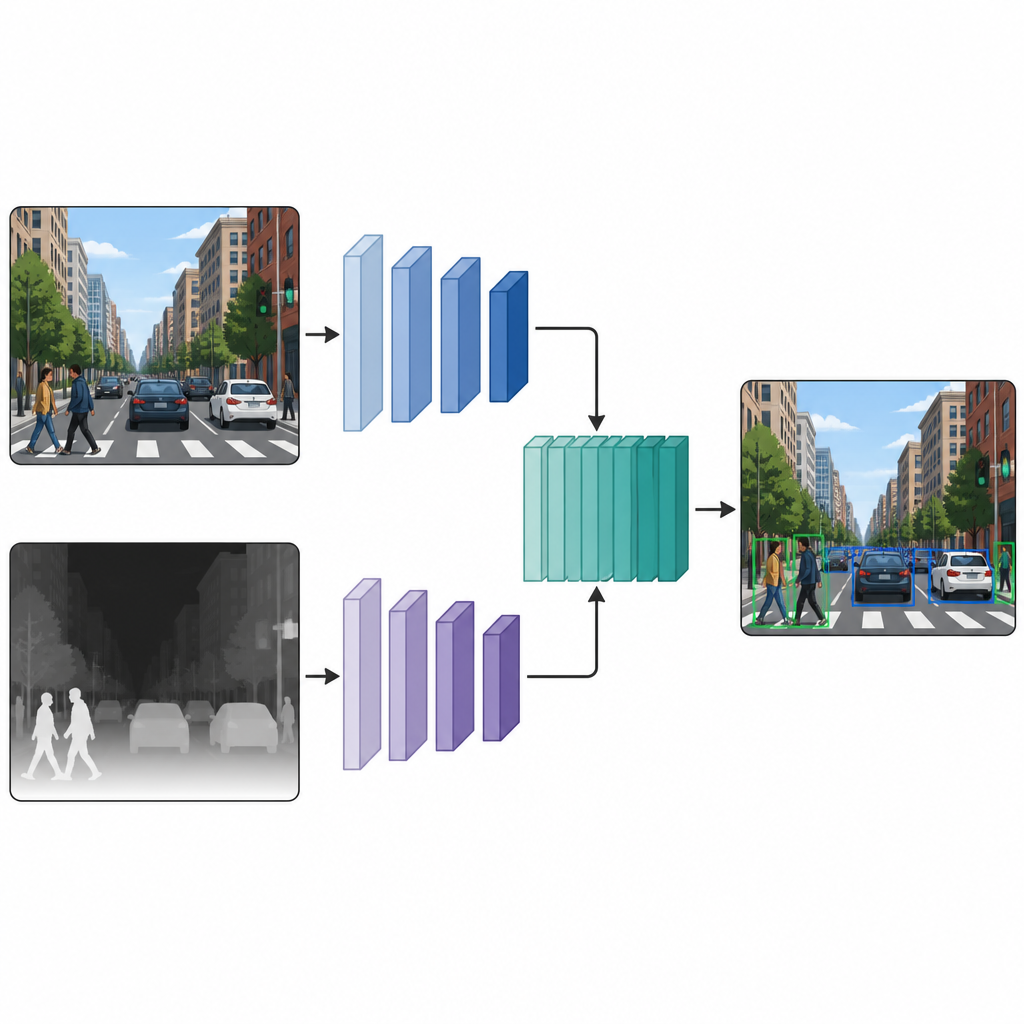
Wat de experimenten in echte scènes onthullen
Het team test hun aanpak op twee bekende beeldverzamelingen. De ene, COCO genoemd, bevat drukbezette alledaagse foto’s van mensen, dieren en objecten. De andere, M3FD, richt zich op wegscènes waarin zowel zichtbare als infraroodcamera’s worden gebruikt. Over meerdere populaire detectiemodellen, waaronder lichte versies van YOLO en een op transformers gebaseerd detector, verhoogt het toevoegen van pseudo-dieptekenmerken consequent de nauwkeurigheid. Op COCO verbetert de hoofdscores voor correcte detecties met maximaal acht procentpunten, terwijl M3FD meer bescheiden maar stabiele winst ziet. Visuele voorbeelden tonen duidelijkere objectcontouren, minder gemiste straatlantaarns in nachtscènes en betere scheiding van mensen van drukke achtergronden, vooral bij matig licht.
Duidelijker zicht zonder extra hardware
Voor lezers is de kernboodschap dat het geven van een ruw afstandsgevoel aan een AI, zelfs wanneer die maar één foto heeft, zijn wereldbegrip scherper kan maken. Door dieptenkaarten in software te creëren en ze samen met gewone kleurbeelden in het neurale netwerk te combineren, helpt deze methode detectoren objecten betrouwbaarder te vinden zonder nieuwe sensoren toe te voegen of de camera te veranderen. De aanpak kan als eenvoudige toevoeging op veel bestaande modellen worden aangesloten en ruilt een matige toename in rekenwerk in voor merkbaar betere prestaties in complexe, echte werelddoorgangen.
Bronvermelding: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
Trefwoorden: objectdetectie, diepteinschatting, computervisie, pseudo-diepte, RGB-afbeeldingen