Clear Sky Science · he
מודל רשת עצבית עמוקה מבוסס עומק מדומה לגילוי עצמים
מדוע חשוב ללמד מצלמות על עומק
מצלמות מודרניות ואפליקציות לטלפון משתפרות בזיהוי אנשים, כלי רכב ועצמים אחרים, אך ברובן מסתמכות על תמונות צבע שטוחות. המאמר שואל שאלה פשוטה ובעלת השפעה גדולה: מה אם נוכל לתת למצלמות רגילות תחושת עומק, סוג של הרגשה תלת־ממדית משוערת, מבלי להוסיף חיישנים נוספים או חומרה יקרה? על ידי זיהוי עומק מדומה מתמונה בודדת והזנתו למערכות ה-AI הקיימות, המחברים מראים כי גילוי העצמים יכול להפוך לדיוק משמעותי יותר בסצנות יומיומיות.
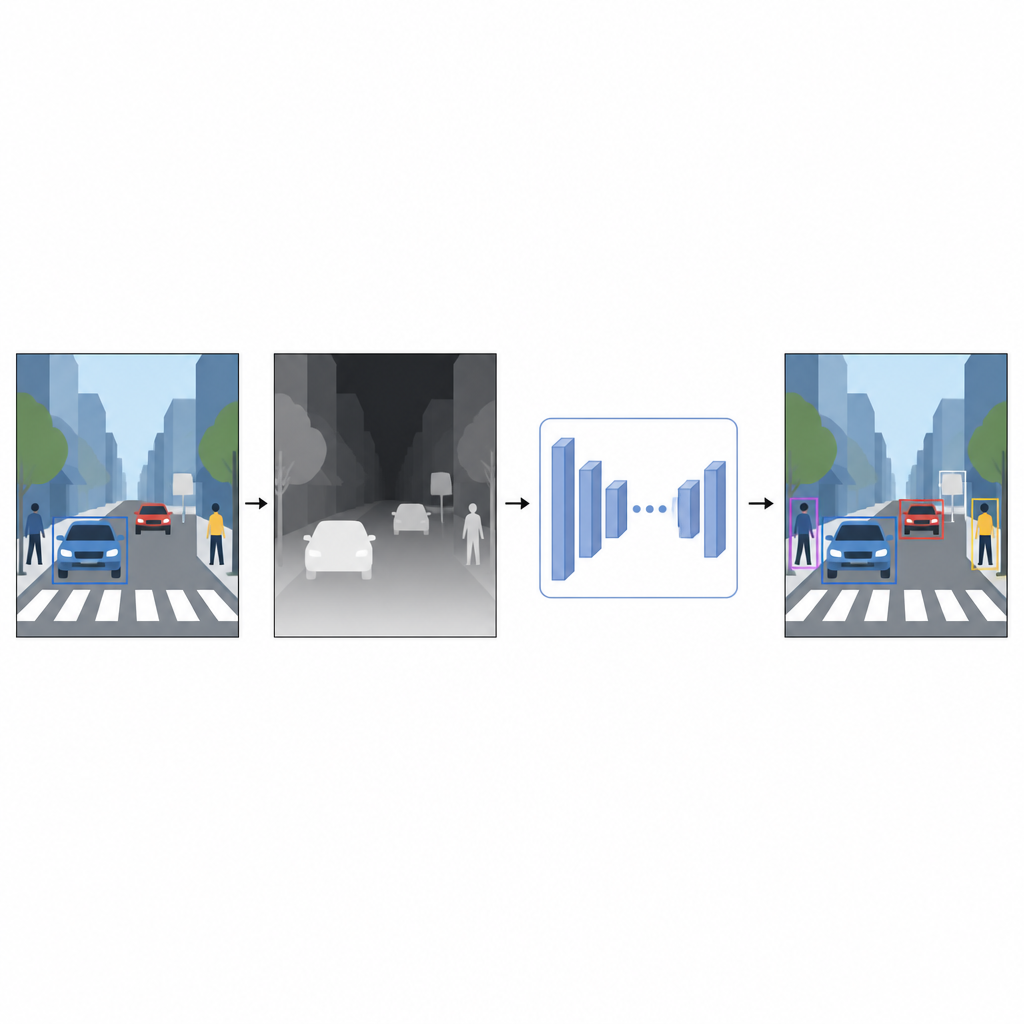
מתמונות שטוחות לתחושת מרחק
תמונות יומיומיות מקליטות צבע ומרקם אך לא מרחק. עבור מחשב, מכונית אדומה בוהקת וקיר אדום עלולים להיראות דומים ומבלבלים כאשר הם חופפים בתמונה דו־ממדית. מידע על עומק, אפילו משוער, מסייע להפריד קדמי מרקע ולחדד גבולות עצמים. במקום להסתמך על מכשירים מיוחדים כמו סורקי לייזר או מערכי מצלמות סטריאו, המחברים משתמשים בטכניקה שנקראת אמידת עומק מונוקולרית. מודל בינה מלאכותית נפרד מקבל תמונת צבע בודדת ומנבא מפה צפופה של עומק — דוגמת ערכת גוונים שעבור כל פיקסל מציעה עד כמה הנקודה בסצנה קרובה או רחוקה.
חיישן עומק וירטואלי עשוי תוכנה
ליצירת מפות העומק המדומות, המחקר משתמש ברשת אמידת עומק מהמתקדמות ביותר המאומנת בשני שלבים. תחילה היא לומדת מקבוצות גדולות של סצנות סינתטיות, שבהן קל לקבל עומק מדויק. לאחר מכן היא מחדדת את כישוריה על תמונות אמיתיות שסומנו באופן אוטומטי באמצעות מודל מורה חזק. אסטרטגיית אימון זו מאפשרת לרשת העומק להתמודד עם מצבים מאתגרים, כולל תאורה חלשה, פריטים שקופים כמו זכוכית ומבנים דקים כגון עמודים או רגלי כיסאות. מפות העומק המדומות המתקבלות מספקות רמזים חלקים ברמת פיקסל על צורת הסצנה שמעשירים את תמונת הצבע המקורית.
שתי תצפיות מקבילות שעובדות יחד
לאחר שלכל תמונה יש גרסת צבע וגרסת עומק מדומה, המחברים מזינים אותן לרשת גילוי עם שני מסלולים מקבילים. מסלול אחד מעבד את תמונת הצבע הרגילה, בעוד המסלול השני מעבד את מפת העומק, כשהם משתמשים בסוג דומה של שלד רשת עצבית בשני המסלולים. במספר שכבות ביניים, מפת התכונות משני המסלולים נשזרות ומעודנות עוד. המיזוג בשלב האמצעי מאפשר למודל לשמר מה שמייחד את רמזי הצבע ואת רמזי העומק, ובו־זמנית ללמוד כיצד הם משתלבים. התכונות המאוחדות עוברות לאחר מכן לראש גילוי סטנדרטי שמוציא תיבות ותוויות עבור העצמים בסצנה.
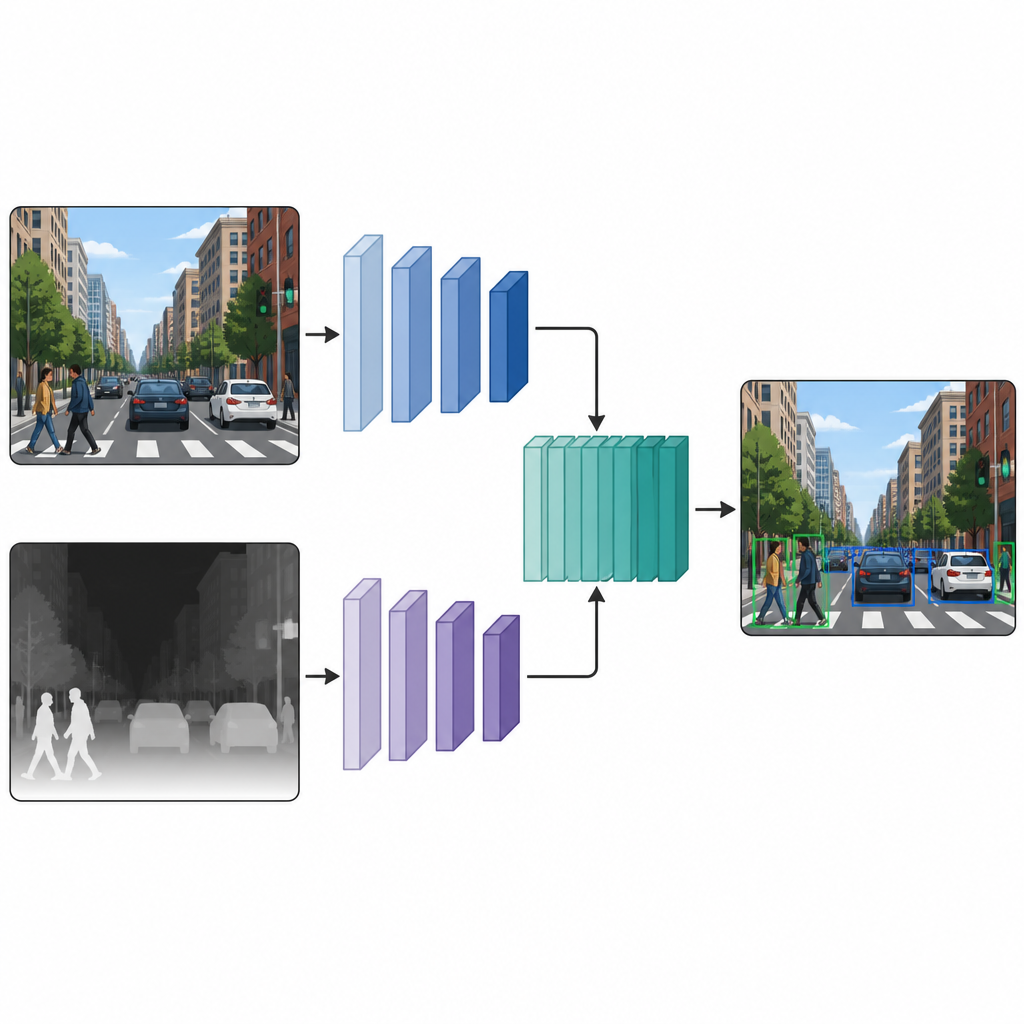
מה הניסויים מגלים בסצנות אמיתיות
הצוות בוחן את הגישה שלהם על שתי אוספות תמונות ידועות. האחת, בשם COCO, מכילה תמונות יומיומיות צפופות של אנשים, בעלי חיים ועצמים. השנייה, M3FD, מתמקדת בסצנות כביש שבהן משתמשים גם במצלמות ויזואליות וגם באינפרה־אדום. על פני כמה מודלים פופולריים לגילוי, כולל גרסאות קלות של YOLO ומגלה מבוסס טרנספורמר, הוספת תכונות עומק מדומות משפרת באופן עקבי את הדיוק. ב־COCO הציון המרכזי של גילויים נכונים משתפר בעד שמונה נקודות אחוז, בעוד ש־M3FD מציגה עליות צנועות אך יציבות. דוגמאות ויזואליות מראות קווי מתאר ברורים יותר של עצמים, פחות עמודי תאורה חסרים בסצנות לילה ויכולת טובה יותר להפריד אנשים מרקע צפוף, במיוחד בתאורה חלשה.
ראייה ברורה יותר בלי חומרה נוספת
המסר המרכזי לקוראים הוא כי נתינת תחושת מרחק משוערת ל־AI, אפילו מתמונה בודדת, יכולה לחדד את הבנתו את העולם. על ידי יצירת מפות עומק בתוכנה ושילובן עם תמונות הצבע בתוך הרשת העצבית, השיטה עוזרת לגלאים למצוא עצמים באופן אמין יותר בלי להוסיף חיישנים חדשים או לשנות את המצלמה. הגישה ניתנת לשילוב בהרבה מודלים קיימים כתוספת פשוטה, בהחלפת עלייה מתונה בחישוב בתמורה לביצועים משופרים בסצנות מורכבות מהחיים האמיתיים.
ציטוט: Li, SQ., Feng, W., Liu, B. et al. Pseudo-depth-based deep neural network model for object detection. Sci Rep 16, 15120 (2026). https://doi.org/10.1038/s41598-026-45310-w
מילות מפתח: גילוי עצמים, אמידת עומק, ראייה ממוחשבת, עומק מדומה, תמונות RGB