Clear Sky Science · zh
通过中间层引导在多模态大语言模型中重新对齐注意力
为何更聪明的图像阅读器很重要
当我们向今天的人工智能系统询问有关图片的问题——例如“缎带是什么颜色?”或“这块街牌写的是什么?”——我们期望它们能认真观察图像。实际上,许多将视觉与语言结合的多模态 AI 模型往往更依赖于它们从文本中“知道”的内容,而不是实际看到的影像。这会导致它们自信地描述不存在的物体或误读诸如小字体等细节。本文提出了一种方法,能够温和地将这些模型重新引导回图像本身,帮助它们关注正确的视觉细节,而无需从头重新训练。
当语言淹没了眼见之物
现代多模态大语言模型(MLLMs)将强大的文本引擎与视觉模块配对,能够描述场景、回答关于图表或文档的问题,并将世界知识与图像内容结合起来。然而,这些模型容易产生“幻觉”:它们可能在只有一只猫的图片中声称有一只狗,或猜错颜色、数量或物体位置。早期研究表明,这些错误产生的原因在于语言部分主导了推理,依赖于其阅读中习得的常见模式,而不是面前的具体像素。
模型中间层的隐性聚焦
作者逐层检查这些模型,观察模型在形成答案时注意力究竟落在哪里。令人惊讶的是,他们发现模型往往确实知道该在图像中看哪里——尤其是在其中间层。例如,即便模型错误地说缎带是白色而非红色,其内部的注意力仍可能准确聚焦在真实的缎带区域。不过,随着信息流向更深层,这种视觉聚焦会变得模糊并逐渐被语言习惯和对场景的普遍预期所掩盖。问题因此并非完全看不见,而是在传递过程中丢失了细节。
一个重新对齐注意力的插件
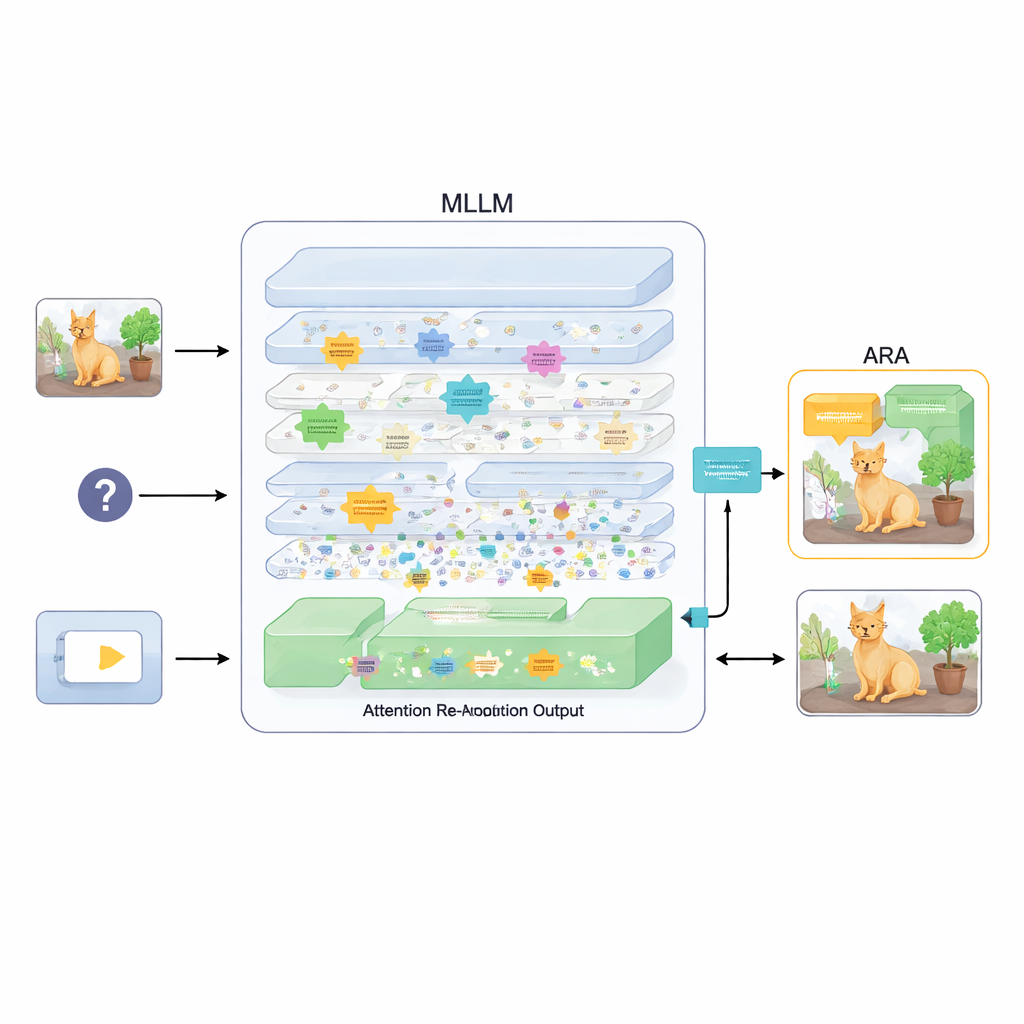
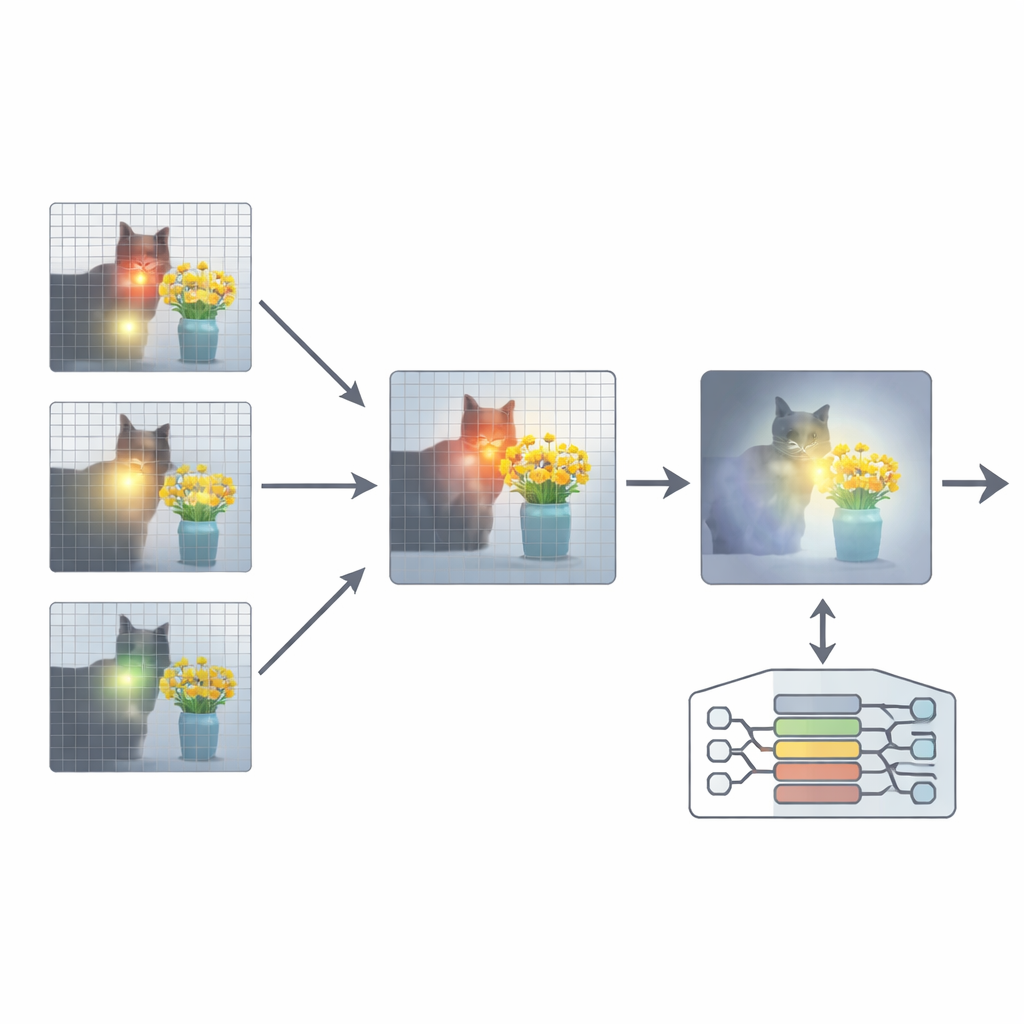
为了解决这一问题,论文提出了一个名为注意力再对齐(Attention Re-Alignment,ARA)的附加组件。ARA 并不改变模型参数或重新训练模型,而是利用模型在中间层的注意力图。它首先识别那些“以图像为中心”的头——即那些可靠地将注意力集中在与用户问题相关区域,而不仅仅是视觉上最显著位置的部分。接着,它基于注意力的集中程度和置信度对每一层进行评分,并针对每个问题选择最合适的几层。然后从这些被选中的层中融合其注意力图,形成一幅清晰的图示,显示模型真正认为重要视觉证据所在的位置。
只让模型看到重要之处
ARA 接着将这幅融合的注意力图转换为图像上的简单掩码:模型高度关注的区域保持可见,而不太相关的区域被变暗或遮挡。这个带掩码的图像在生成答案时被反馈回模型,温和地迫使模型将其回答建立在被高亮的区域上。掩码是自适应的,因此既能捕捉精确的局部细节(例如小牌子或文档中的单词),也能在需要时保留更广的上下文。通过在多个基准任务上的精心实验——涵盖图像与文档中的文本识别、通用问答以及专门设计用于暴露幻觉的问题集——作者展示了 ARA 在不需额外训练的情况下,能一贯提高准确率并减少虚构内容,而且可适用于多种流行的 MLLM。
更清晰的视野,同样的“大脑”
通俗地说,这项工作为现有的图像—语言模型配上一副更合适的眼镜,而不是替换它们的大脑。通过恢复并强化模型在中间层对图像正确部位的关注,ARA 帮助模型更忠实地描述和推理视觉细节。该方法并不会神奇地赋予模型更深的常识或百科式知识;而是解决了一个实际的瓶颈:确保模型真正根据眼前所见给出答案。随着这些系统越来越多地被用于阅读文档、分析真实场景或辅助安全关键决策,像 ARA 这样的技术能让 AI 工具在日常使用中变得更可信、更可靠。
引用: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
关键词: 多模态人工智能, 视觉问答, 注意力机制, 幻觉减少, 视觉语言模型