Clear Sky Science · de
Aufmerksamkeits-Neuausrichtung in multimodalen großen Sprachmodellen über Zwischenlagen‑Guidance
Warum klügere Bildleser wichtig sind
Wenn wir heutige KI-Systeme zu Bildern befragen – etwa „Welche Farbe hat das Band?“ oder „Was steht auf diesem Verkehrsschild?“ – erwarten wir, dass sie das Bild genau betrachten. Tatsächlich verlassen sich viele multimodale KI‑Modelle, die Sehen und Sprache kombinieren, jedoch häufiger auf das, was sie aus Texten „wissen“, statt auf das, was sie tatsächlich sehen. Das kann dazu führen, dass sie selbstsicher Objekte beschreiben, die nicht vorhanden sind, oder feine Details wie kleine Schrift falsch lesen. Dieses Paper stellt eine Methode vor, diese Modelle behutsam wieder stärker auf das Bild zu lenken, sodass sie sich auf die richtigen visuellen Details konzentrieren, ohne vollständig neu trainiert werden zu müssen.
Wenn Worte das Sehen übertönen
Moderne multimodale große Sprachmodelle (MLLMs) kombinieren eine leistungsfähige Textkomponente mit einem visuellen Modul, sodass sie Szenen beschreiben, Fragen zu Diagrammen oder Dokumenten beantworten und Weltwissen mit dem Bildinhalt verknüpfen können. Dennoch neigen diese Modelle zu sogenannten „Halluzinationen“: Sie behaupten etwa, in einem Bild sei ein Hund, obwohl nur eine Katze zu sehen ist, oder sie erraten falsch Farbe, Zahl oder Lage von Objekten. Frühere Untersuchungen legen nahe, dass diese Fehler dadurch entstehen, dass der Sprachanteil das Denken dominiert und sich stärker auf vertraute Muster aus dem Gelesenen stützt, statt auf die konkreten Pixel vor ihnen.
Verborgene Fokussierung in den mittleren Lagen des Modells
Die Autoren blicken in diese Modelle hinein, Schicht für Schicht, um herauszufinden, wohin die Aufmerksamkeit wirklich gelenkt wird, während das Modell eine Antwort formt. Überraschenderweise stellen sie fest, dass das Modell häufig durchaus weiß, wohin es im Bild schauen sollte – insbesondere in seinen Zwischenlagen. Zum Beispiel kann das Modell, obwohl es fälschlich sagt, ein Band sei weiß statt rot, intern dennoch eine scharf fokussierte Aufmerksamkeit auf die tatsächliche Bandregion richten. Wenn die Information in tiefere Schichten fließt, verwischt dieser visuelle Fokus jedoch und wird nach und nach von sprachlichen Gewohnheiten und allgemeinen Szeneerwartungen überlagert. Das Problem ist demnach weniger Blindheit als vielmehr ein schrittweises Verlieren von Details.
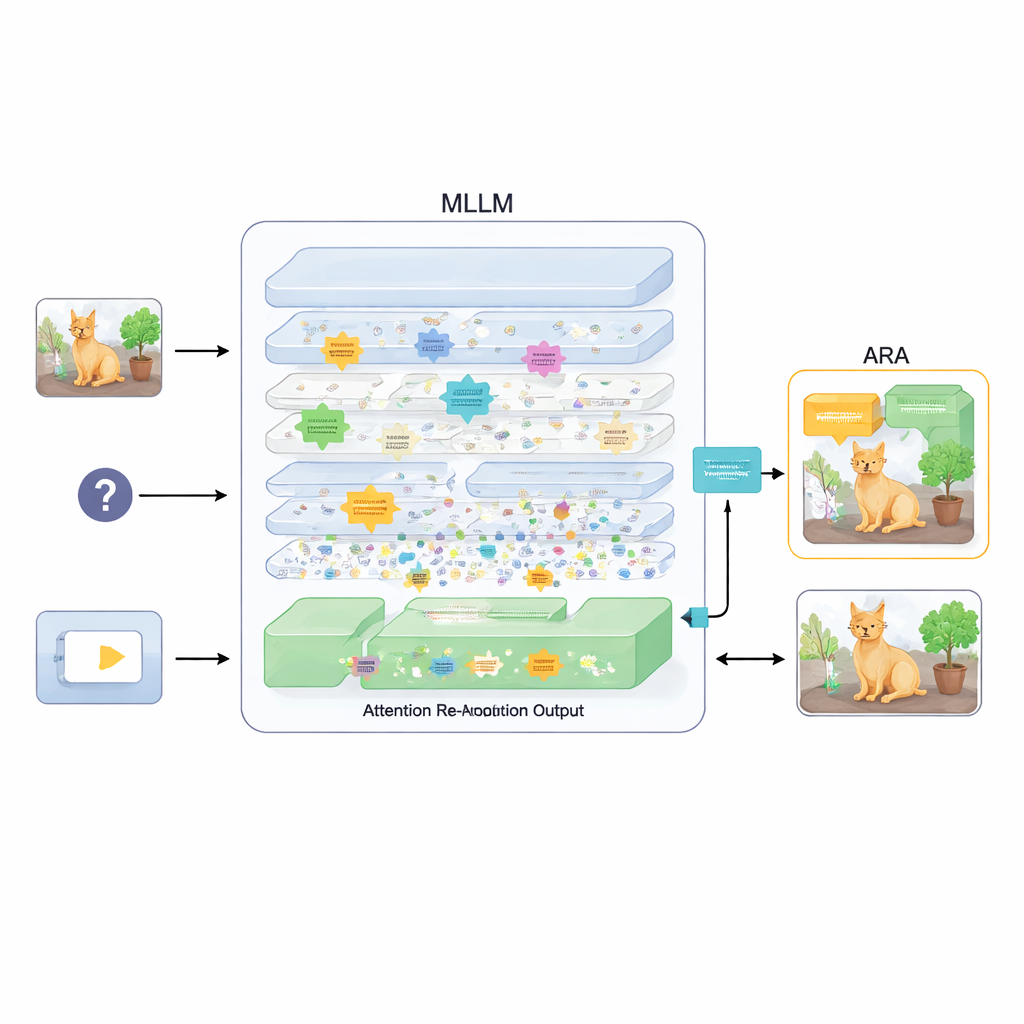
Ein Plug‑in, das die Aufmerksamkeit neu ausrichtet
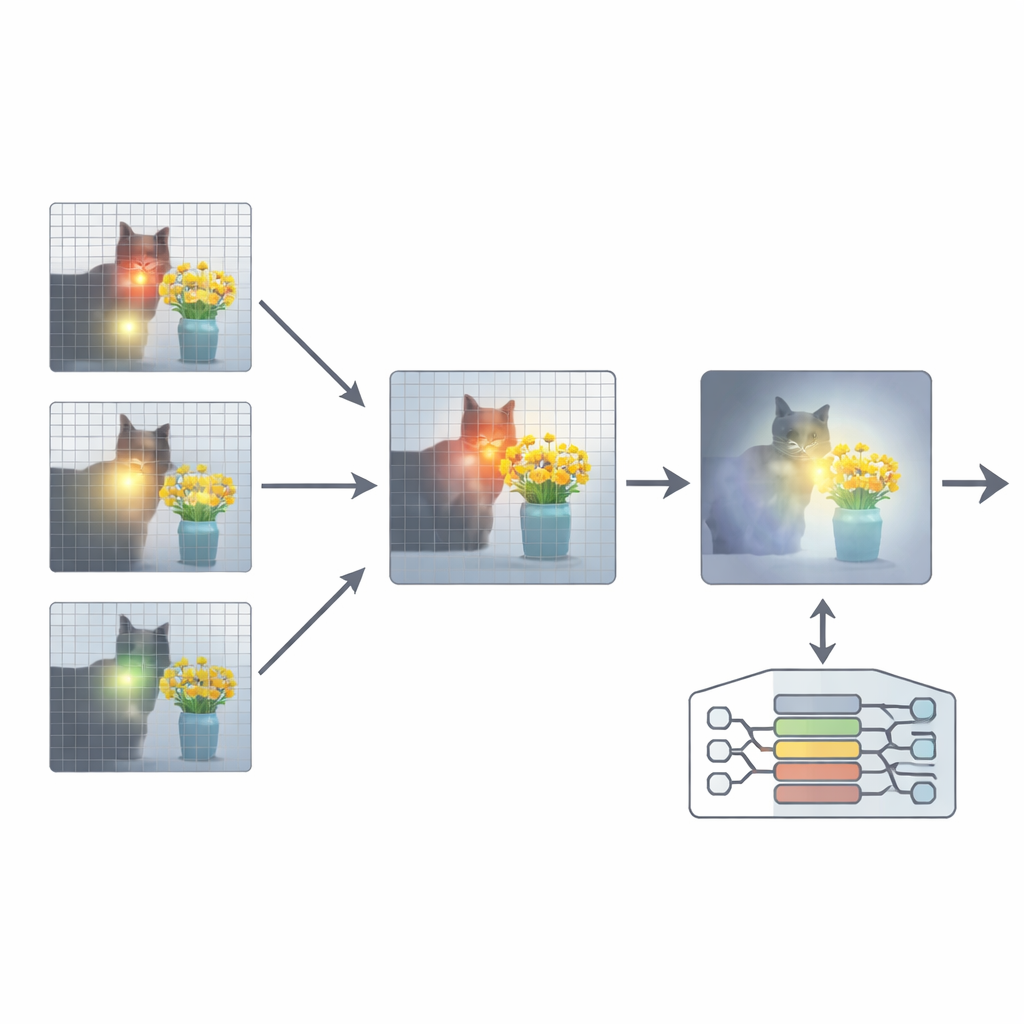
Zur Lösung schlagen die Autoren ein Add‑on namens Attention Re‑Alignment (ARA) vor. Anstatt die Modellparameter zu verändern oder das Modell neu zu trainieren, nutzt ARA die eigenen Aufmerksamkeitskarten des Modells in den mittleren Lagen. Zuerst identifiziert es jene „bildzentrierten“ Attention‑Heads – Teile des Modells, die zuverlässig Regionen fokussieren, die zur Frage des Nutzers passen, und nicht nur auf visuell Auffälliges reagieren. Anschließend bewertet es jede Schicht danach, wie scharf und selbstbewusst sie fokussiert, und wählt für jede Frage die besten Schichten aus. Aus diesen ausgewählten Lagen fusioniert ARA deren Aufmerksamkeitskarten zu einem einzigen, klaren Bild darüber, wo das Modell nach eigener Einschätzung die relevanten visuellen Hinweise sieht.
Das Modell sehen lassen, was zählt
ARA wandelt diese fusionierte Aufmerksamkeit dann in eine einfache Maske über dem Bild um: Bereiche, die dem Modell wichtig sind, bleiben sichtbar, weniger relevante Regionen werden gedimmt oder ausgeblendet. Dieses gemaskte Bild wird während der Antwortgenerierung erneut dem Modell zugeführt und zwingt es sanft dazu, seine Antwort in den hervorgehobenen Bereichen zu verankern. Die Maskierung ist adaptiv, sodass sie sowohl präzise lokale Details (etwa ein kleines Schild oder ein Wort in einem Dokument) als auch bei Bedarf den weiteren Kontext erfasst. Durch sorgfältige Experimente auf mehreren Benchmarks – von der Texterkennung in Bildern und Dokumenten bis zu allgemeinen Frage‑Antwort‑Aufgaben und Tests, die speziell auf Halluzinationen abzielen – zeigen die Autoren, dass ARA die Genauigkeit beständig verbessert und erfundene Inhalte reduziert, und dass es ohne zusätzliches Training über verschiedene populäre MLLMs hinweg funktioniert.
Scharfer Blick, gleiches Gehirn
Alltagsnah gesprochen verleiht diese Arbeit bestehenden Bild‑Sprach‑Modellen eher eine bessere Brille als ein neues Gehirn. Indem ARA den mittleren Fokus des Modells auf die richtigen Bildregionen wiederherstellt und stärkt, hilft es dem Modell, visuelle Details treuer zu beschreiben und zu begründen. Der Ansatz verleiht dem Modell nicht plötzlich tiefere Alltagslogik oder enzyklopädisches Wissen; er adressiert stattdessen einen praktischen Engpass: sicherzustellen, dass die Antworten wirklich auf dem vorliegenden Bild basieren. Da solche Systeme zunehmend in Bereichen eingesetzt werden, etwa beim Lesen von Dokumenten, bei der Analyse realer Szenen oder bei sicherheitskritischen Unterstützungsaufgaben, können Methoden wie ARA, die die Erzählungen an das Bild binden, KI‑Werkzeuge für den Alltag vertrauenswürdiger und zuverlässiger machen.
Zitation: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Schlüsselwörter: multimodale KI, visuelle Fragebeantwortung, Aufmerksamkeitsmechanismen, Reduktion von Halluzinationen, Vision-Language-Modelle