Clear Sky Science · es
Realineamiento de la atención en modelos de lenguaje multimodal mediante guía de capas intermedias
Por qué importan los lectores de imágenes más inteligentes
Cuando le preguntamos a los sistemas de IA actuales sobre imágenes —por ejemplo «¿De qué color es la cinta?» o «¿Qué dice esta señal de la calle?»— esperamos que examinen la imagen con cuidado. En la práctica, muchos modelos multimodales, que combinan visión y lenguaje, se apoyan más en lo que “saben” por el texto que en lo que realmente ven. Esto puede llevarles a describir con confianza objetos que no están presentes o a leer mal detalles finos como texto pequeño. Este artículo presenta una manera de reconducir con suavidad a esos modelos hacia la propia imagen, ayudándoles a centrar la atención en los detalles visuales correctos sin tener que reentrenarlos desde cero.
Cuando las palabras ahogan lo que ven los ojos
Los modelos multimodales de gran tamaño modernos (MLLMs) combinan un potente motor de texto con un módulo de visión, lo que les permite describir escenas, responder preguntas sobre gráficos o documentos y fusionar conocimientos generales con lo que aparece en una imagen. Sin embargo, estos modelos son propensos a «alucinaciones»: pueden afirmar que hay un perro en una foto que solo contiene un gato, o equivocarse sobre el color, el número o la posición de los objetos. Estudios previos sugirieron que estos errores surgen porque la parte lingüística del modelo domina el razonamiento, apoyándose en patrones familiares aprendidos de la lectura más que en los píxeles concretos ante sí.
Un foco oculto en el interior del modelo
Los autores inspeccionan estos modelos capa por capa para ver a dónde va realmente la atención mientras el modelo forma una respuesta. Sorprendentemente, encuentran que el modelo a menudo sí sabe dónde mirar en la imagen —especialmente en sus capas intermedias. Por ejemplo, aun cuando afirma erróneamente que una cinta es blanca en lugar de roja, su atención interna puede seguir concentrándose de forma nítida en la región real de la cinta. Sin embargo, a medida que la información fluye hacia capas más profundas, ese foco visual se difumina y queda gradualmente eclipsado por hábitos lingüísticos y expectativas generales de la escena. El problema, por tanto, es menos una ceguera que una pérdida de detalles en el trayecto.
Un complemento que realinea la atención
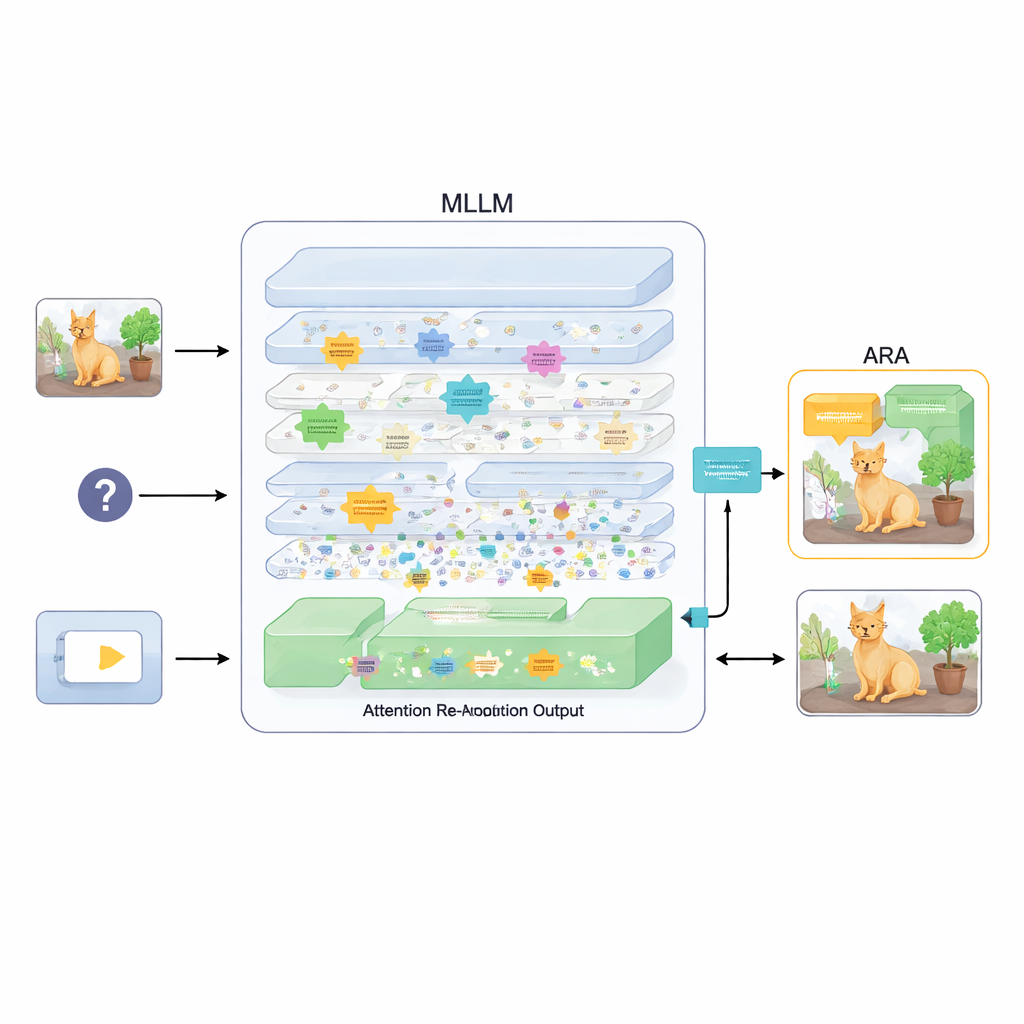
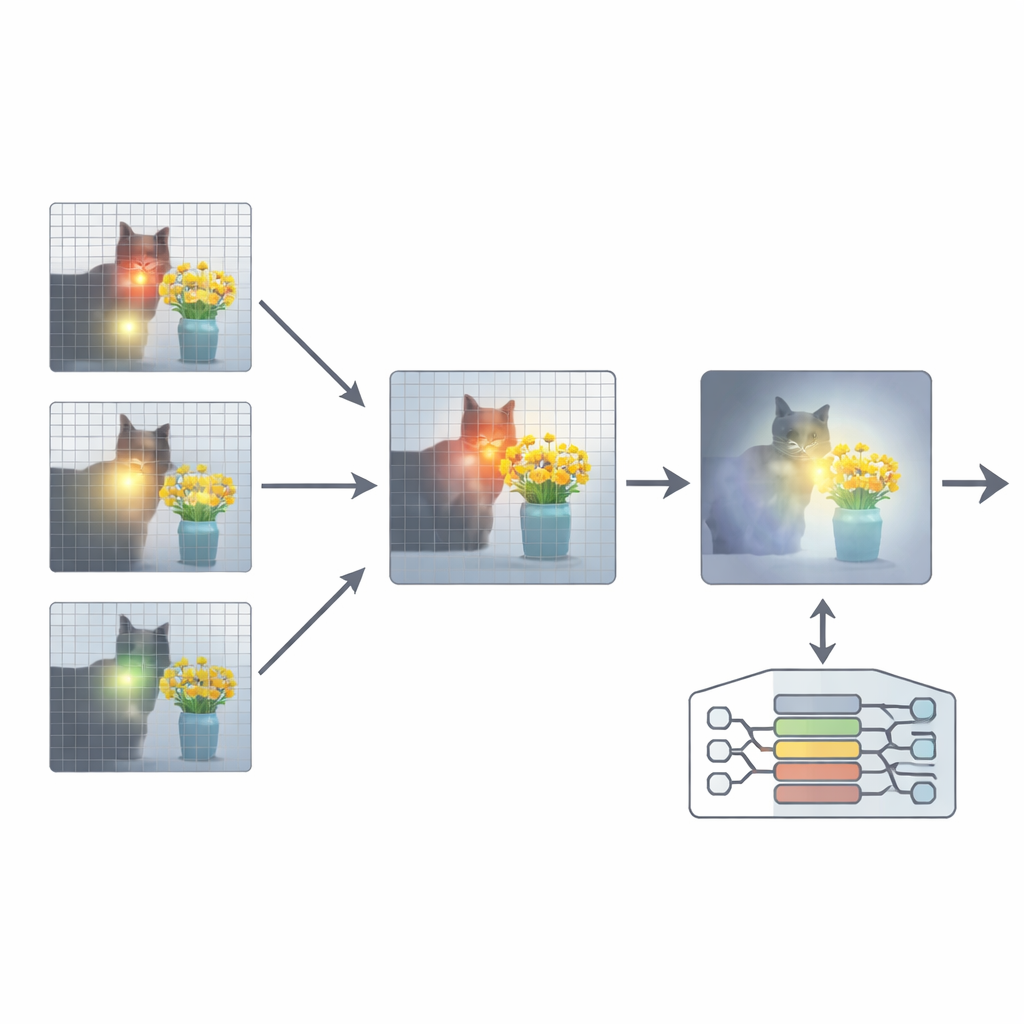
Para resolver esto, el artículo propone un añadido llamado Realineamiento de la Atención (ARA). En lugar de cambiar los parámetros del modelo o reentrenarlo, ARA aprovecha los propios mapas de atención del modelo en las capas intermedias. Primero identifica esas cabezas «centradas en la imagen» —partes del modelo que se concentran de forma fiable en regiones vinculadas a la pregunta del usuario, no solo en lo más llamativo visualmente. Luego puntúa cada capa según la nitidez y la confianza de su foco, y selecciona las mejores capas para cada pregunta. A partir de estas capas elegidas, ARA fusiona sus mapas de atención en una única imagen limpia de dónde el modelo cree realmente que se encuentra la evidencia visual importante.
Permitir que el modelo vea solo lo que importa
ARA convierte esta atención fusionada en una máscara simple sobre la imagen: las áreas que interesan mucho al modelo permanecen visibles, mientras que las regiones menos relevantes se atenúan o se bloquean. Esta imagen enmascarada se vuelve a introducir en el modelo durante la generación de la respuesta, forzándolo suavemente a fundamentar su respuesta en las regiones resaltadas. El enmascarado es adaptable, de modo que captura tanto detalles locales precisos (como un letrero pequeño o una palabra en un documento) como el contexto más amplio cuando es necesario. Mediante experimentos cuidadosos en varios puntos de referencia —desde la lectura de textos en imágenes y documentos hasta preguntas generales y pruebas diseñadas específicamente para exponer alucinaciones— los autores muestran que ARA mejora de forma consistente la exactitud y reduce el contenido inventado, y funciona en distintos MLLM populares sin necesidad de entrenamiento adicional.
Visión más nítida, mismo cerebro
En términos cotidianos, este trabajo ofrece a los modelos imagen–lenguaje existentes unas mejores gafas más que un cerebro nuevo. Al recuperar y reforzar el foco de nivel medio del propio modelo sobre las partes correctas de una imagen, ARA le ayuda a describir y razonar sobre los detalles visuales con mayor fidelidad. El enfoque no otorga mágicamente un conocimiento más profundo de sentido común o enciclopédico; en cambio, aborda un cuello de botella práctico: asegurarse de que el modelo realmente base sus respuestas en lo que tiene delante. Dado que estos sistemas se utilizan cada vez más en escenarios como la lectura de documentos, el análisis de escenas del mundo real o la asistencia en decisiones críticas para la seguridad, métodos como ARA que mantienen sus relatos anclados a la imagen pueden hacer que las herramientas de IA sean más confiables y útiles para los usuarios cotidianos.
Cita: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Palabras clave: IA multimodal, respuesta visual a preguntas, mecanismos de atención, reducción de alucinaciones, modelos de visión y lenguaje