Clear Sky Science · it
Riallineamento dell’attenzione nei modelli linguistici multimodali tramite guida agli strati intermedi
Perché sono importanti lettori d’immagini più intelligenti
Quando chiediamo ai sistemi di IA di oggi domande sulle immagini — per esempio “Di che colore è il nastro?” o “Cosa dice questo cartello stradale?” — ci aspettiamo che osservino attentamente l’immagine. In realtà, molti modelli multimodali, che combinano visione e linguaggio, tendono spesso a fare più affidamento su ciò che “sanno” dal testo che su ciò che vedono realmente. Questo può portarli a descrivere con sicurezza oggetti che non ci sono o a leggere male dettagli fini come piccoli testi. Questo articolo propone un modo per orientare delicatamente tali modelli verso l’immagine stessa, aiutandoli a concentrarsi sui dettagli visivi corretti senza doverli riaddestrare da zero.
Quando le parole annebbiano ciò che gli occhi vedono
I moderni grandi modelli linguistici multimodali (MLLM) accoppiano un potente motore testuale con un modulo visivo, permettendo loro di descrivere scene, rispondere a domande su grafici o documenti e combinare conoscenza del mondo con quanto è presente in un’immagine. Tuttavia, questi modelli sono soggetti a “allucinazioni”: possono affermare che in un’immagine c’è un cane quando c’è solo un gatto, o indovinare il colore, il numero o la posizione degli oggetti in modo errato. Studi precedenti suggerivano che questi errori derivino dal fatto che la componente linguistica del modello domina il ragionamento, facendo affidamento su schemi familiari appresi dalla lettura piuttosto che sui pixel specifici davanti a sé.
Focalizzazione nascosta a metà modello
Gli autori esplorano il modello dall’interno, strato per strato, per vedere dove va davvero l’attenzione mentre il modello elabora una risposta. Con sorpresa, scoprono che il modello spesso sa dove guardare nell’immagine — in particolare nei suoi strati intermedi. Per esempio, anche quando afferma sbagliando che un nastro è bianco anziché rosso, la sua attenzione interna può ancora essere concentrata nettamente sulla regione del nastro reale. Man mano che l’informazione scorre verso strati più profondi, però, questa focalizzazione visiva si sfoca e viene gradualmente sovrastata da abitudini linguistiche e aspettative generali sulla scena. Il problema, dunque, non è tanto una cecità quanto la perdita di vista dei dettagli lungo il percorso.
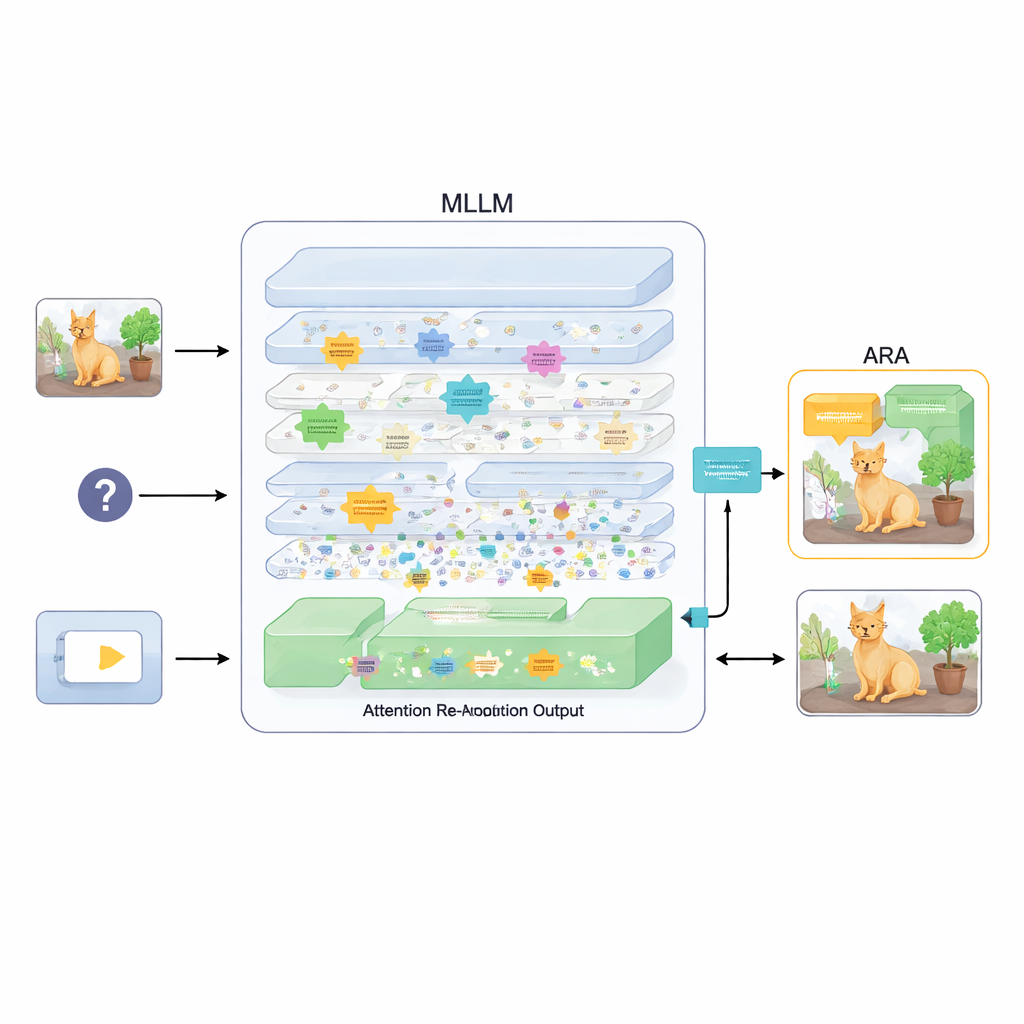
Un plug-in che riallinea l’attenzione
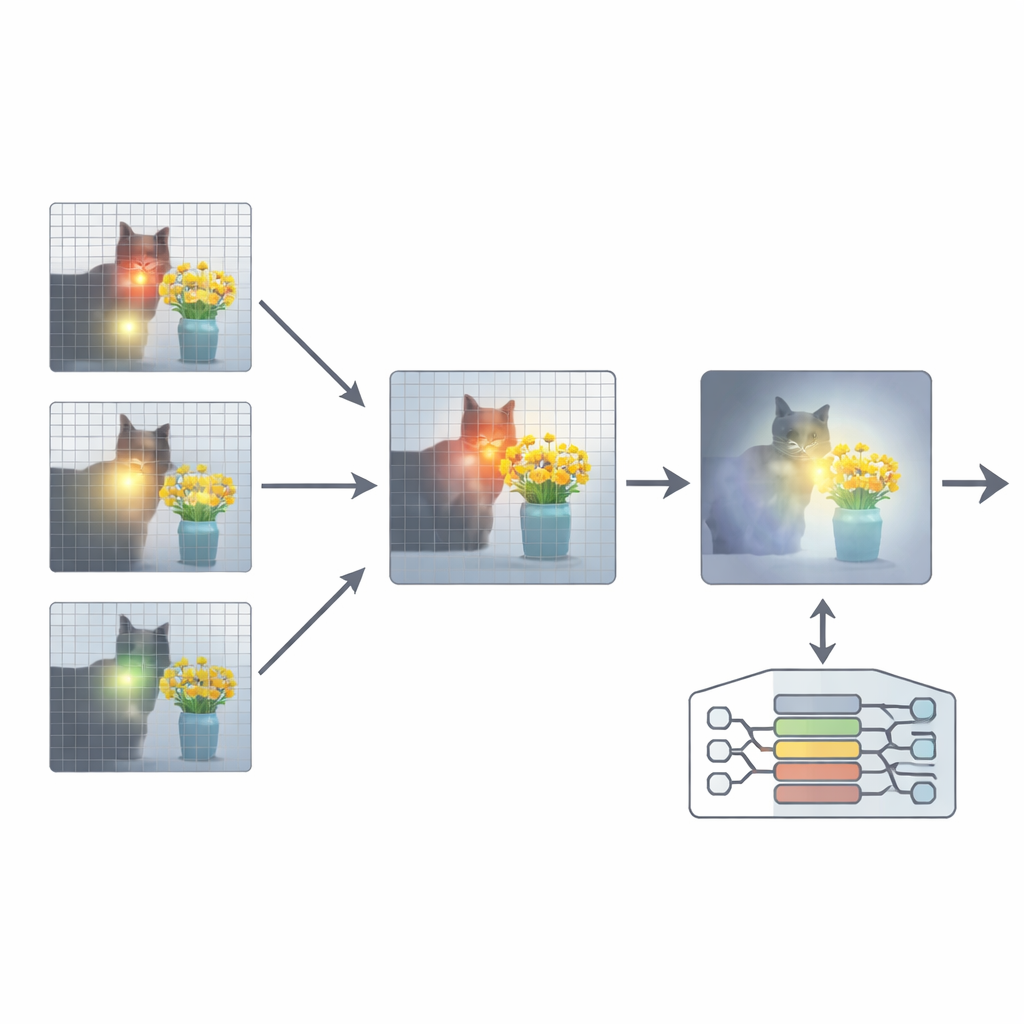
Per risolvere questo, l’articolo propone un componente aggiuntivo chiamato Attention Re-Alignment (ARA). Anziché modificare i parametri del modello o riaddestrarlo, ARA sfrutta le mappe di attenzione del modello negli strati intermedi. Identifica innanzitutto le teste “centrate sull’immagine” — parti del modello che si concentrano in modo affidabile su regioni legate alla domanda dell’utente, non solo su ciò che è visivamente più appariscente. Poi valuta ogni strato in base a quanto nitidamente e con quanta confidenza si focalizza, e seleziona i migliori pochi strati per ciascuna domanda. Da questi strati scelti, ARA fonde le loro mappe di attenzione in un’unica immagine pulita di dove il modello ritiene realmente si trovi l’evidenza visiva importante.
Lasciare che il modello veda solo ciò che conta
ARA trasforma quindi questa attenzione fusa in una maschera semplice sull’immagine: le aree a cui il modello dà molta importanza rimangono visibili, mentre le regioni meno rilevanti vengono attenuate o oscurate. Quest’immagine mascherata viene reinserita nel modello durante la generazione della risposta, spingendolo delicatamente a radicare la sua risposta nelle regioni evidenziate. La mascheratura è adattiva, quindi cattura sia dettagli locali precisi (come un piccolo cartello o una parola in un documento) sia il contesto più ampio quando necessario. Attraverso esperimenti accurati su diversi benchmark — che vanno dalla lettura di testi in immagini e documenti alle domande generali e a test studiati appositamente per mettere in luce le allucinazioni — gli autori mostrano che ARA migliora costantemente l’accuratezza e riduce i contenuti inventati, funzionando su diversi MLLM popolari senza addestramento aggiuntivo.
Visione più nitida, stesso cervello
In termini pratici, questo lavoro fornisce ai modelli immagine–linguaggio esistenti un paio di occhiali migliore invece di un nuovo cervello. Recuperando e rafforzando il focus a medio livello del modello sulle parti giuste di un’immagine, ARA lo aiuta a descrivere e ragionare sui dettagli visivi in modo più fedele. L’approccio non conferisce magicamente una maggiore conoscenza di buon senso o enciclopedica; affronta invece un collo di bottiglia pratico: assicurarsi che il modello basi davvero le proprie risposte su ciò che è davanti a lui. Poiché questi sistemi sono sempre più impiegati in contesti come la lettura di documenti, l’analisi di scene reali o l’assistenza in decisioni critiche per la sicurezza, metodi come ARA che mantengono le narrazioni ancorate all’immagine possono rendere gli strumenti di IA più affidabili e degni di fiducia per gli utenti quotidiani.
Citazione: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Parole chiave: IA multimodale, domande visive, meccanismi di attenzione, riduzione delle allucinazioni, modelli visione-linguaggio