Clear Sky Science · ja
中間層ガイダンスによるマルチモーダル大規模言語モデルのアテンション再調整
なぜ画像をより賢く「読む」ことが重要か
「リボンの色は何ですか?」や「この道路標識は何と書いてありますか?」といった画像に関する問いをAIに投げると、私たちはAIが画像を注意深く見て答えることを期待します。ところが実際には、視覚と言語を組み合わせた多くのマルチモーダルAIモデルは、目に見える情報よりもテキストから得た“知識”に頼りがちです。その結果、実際には存在しない物体を自信満々に描写したり、小さな文字の読み違いをしたりすることがあります。本論文は、こうしたモデルを一から再学習させるのではなく、画像自体へと穏やかに注意を戻す方法を提案します。
言葉が目に見えるものをかき消すとき
現代のマルチモーダル大規模言語モデル(MLLM)は強力なテキスト処理部と視覚モジュールを組み合わせ、シーンの記述やグラフ・文書への質問応答、世界知識と画像内容の統合などを可能にします。しかしこれらのモデルは「ハルシネーション」を起こしやすく、猫しか写っていない画像に犬がいると主張したり、物体の色・数・位置を誤推定したりします。先行研究は、これらの誤りが言語側の部分が推論を支配し、ピクセルの具体的な情報よりも読んだことから得た馴染みのあるパターンに頼ってしまうことに起因すると示唆してきました。
モデル中間で隠れている注目点
著者らはモデルを層ごとに観察し、回答が形成される過程でアテンションがどこに向かっているかを調べます。驚くべきことに、モデルはしばしば画像の正しい領域を知っていることが分かりました――特に中間層においてです。たとえば、リボンが赤であるのに白だと誤答していても、内部のアテンションは実際のリボン領域に鋭く集中していることがあります。しかし情報がより深い層へ流れるにつれて、その視覚的な焦点はぼやけ、言語的な習慣や一般的なシーン期待に徐々にかき消されていきます。つまり問題は視覚の欠如というよりは、途中で詳細を見失ってしまうことにあります。
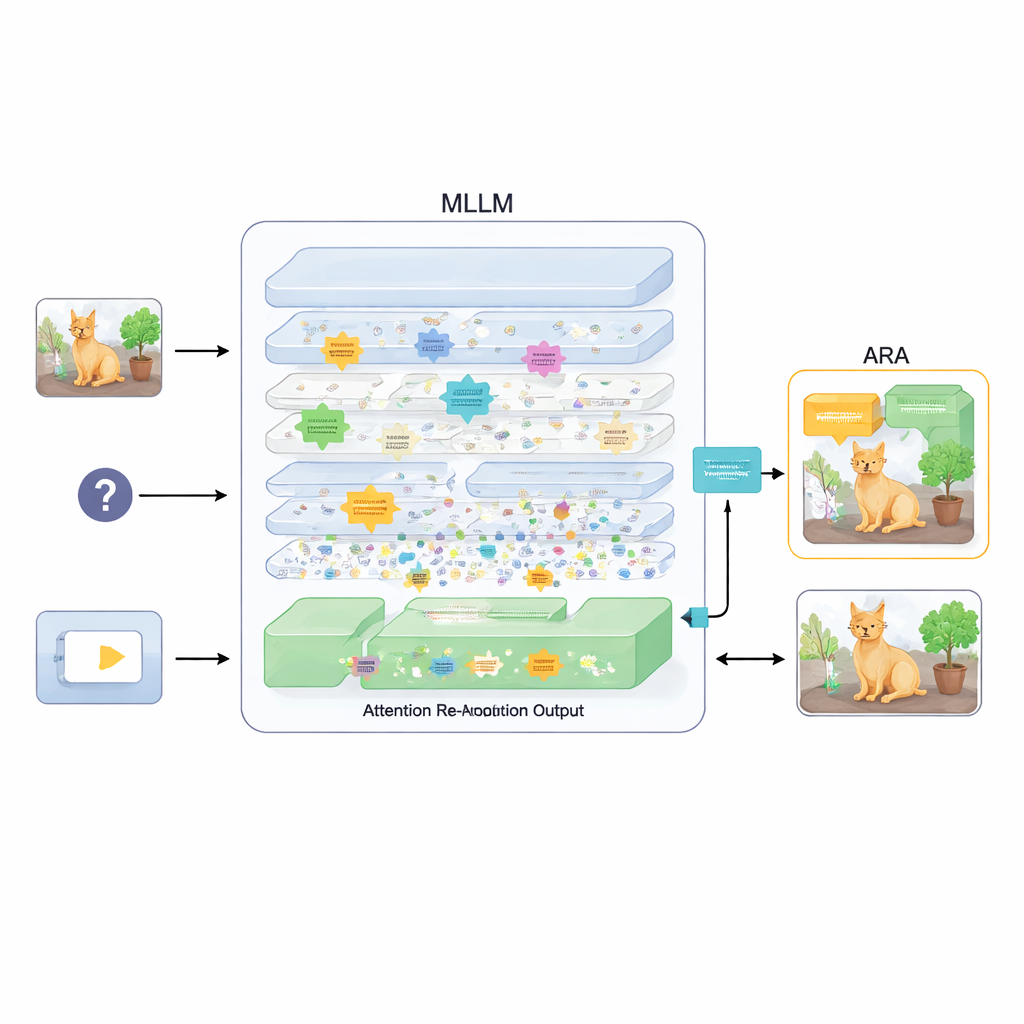
アテンションを再調整するプラグイン
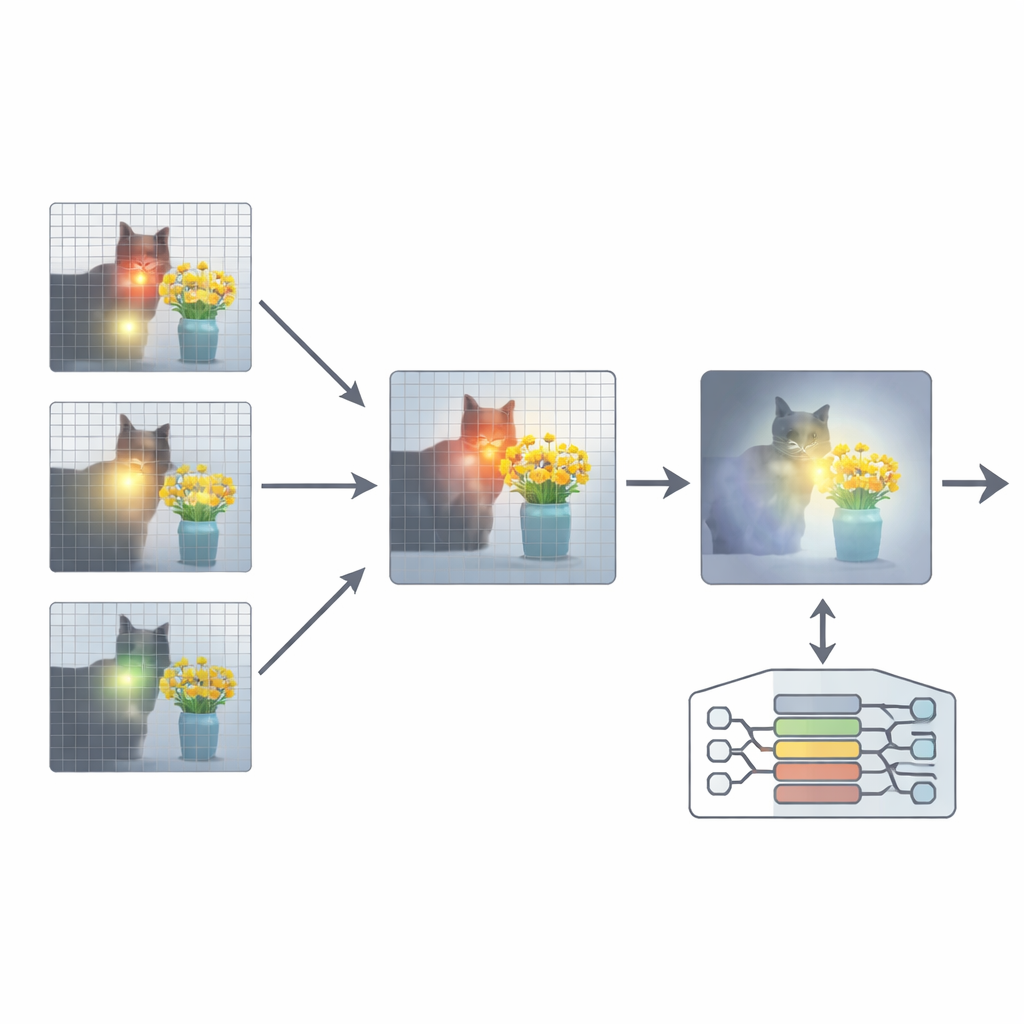
これを解決するために本論文はAttention Re-Alignment(ARA)というアドオンを提案します。モデルのパラメータを変更したり再学習させたりするのではなく、ARAはモデル自身の中間層のアテンションマップにアクセスします。まず、問いに関連する領域に確実に集中する「画像中心の」ヘッドを特定します。次に各層の集中の鋭さと確信度をスコア化し、問いごとに最適な数層を選択します。選ばれた層から得られたアテンションマップを融合して、モデルが本当に重要だと考えている視覚証拠の単一の明瞭な画像を作り出します。
モデルに重要な部分だけを見せる
ARAはその融合されたアテンションを画像上の単純なマスクに変換します:モデルが強く重視する領域は可視のままにし、重要度の低い領域は暗くするか遮断します。このマスクした画像を回答生成時にモデルへ再入力することで、モデルが強引にではなく強制的にではなく、強く強化する形でハイライトされた領域に基づいて応答するよう促します(訳注:原文の意図に沿い「穏やかに強制する」という表現を保っています)。マスキングは適応的で、小さな標識や文書内の単語のような精密な局所情報も、必要に応じて広い文脈も取り込めます。画像中のテキストや文書の読み取りから一般的な質問応答、ハルシネーションを露呈させるためのベンチマークまで、多様な実験においてARAは一貫して精度を向上させ、作り話を減らし、追加の学習を行うことなく複数の代表的なMLLMで動作することを示しています。
脳は同じまま、視覚だけ鮮明に
日常的に言えば、この手法は既存の画像言語モデルに新しい脳を与えるのではなく、よりよいメガネをかけさせるようなものです。モデル自身の中間レベルの焦点を回復し強化することで、ARAは視覚的詳細の記述や推論をより忠実に行わせます。このアプローチは常識や百科事典的知識を魔法のように深めるものではなく、むしろ実用的なボトルネックに対処します:モデルが本当に目の前のものに基づいて答えていることを確かにすることです。文書の読み取り、実世界シーンの解析、安全性に関わる判断支援などの利用が増える中で、ARAのように応答を画像にしっかりと結びつける手法は、AIツールを日常利用者にとってより信頼できるものにするでしょう。
引用: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
キーワード: マルチモーダルAI, 視覚質問応答, アテンション機構, ハルシネーション低減, ビジョン言語モデル