Clear Sky Science · fr
Réalignement de l’attention dans les modèles de langage multimodaux via un guidage des couches intermédiaires
Pourquoi des lecteurs d’images plus intelligents comptent
Lorsque nous posons aux systèmes d’IA actuels des questions sur des images — par exemple « De quelle couleur est le ruban ? » ou « Que dit ce panneau de rue ? » — nous nous attendons à ce qu’ils examinent soigneusement l’image. En réalité, nombre de modèles multimodaux, qui combinent vision et langage, se fient souvent davantage à ce qu’ils « savent » à partir du texte qu’à ce qu’ils voient réellement. Cela peut les amener à décrire avec assurance des objets qui ne sont pas présents ou à mal lire des détails fins comme de petits textes. Cet article présente une méthode pour réorienter en douceur ces modèles vers l’image elle‑même, en les aidant à prêter attention aux bons détails visuels sans les réentraîner depuis zéro.
Quand les mots étouffent ce que voient les yeux
Les modèles de langage multimodaux (MLLM) modernes associent un moteur de texte puissant à un module de vision, ce qui leur permet de décrire des scènes, de répondre à des questions sur des graphiques ou des documents, et de combiner des connaissances générales avec ce qui figure dans une image. Pourtant, ces modèles sont sujets aux « hallucinations » : ils peuvent affirmer qu’il y a un chien sur une photo ne contenant qu’un chat, ou se tromper sur la couleur, le nombre ou la position d’objets. Des études antérieures suggéraient que ces erreurs proviennent du fait que la composante langage domine le raisonnement, s’appuyant sur des schémas familiers issus de sa lecture plutôt que sur les pixels spécifiques devant lui.
Un focus caché au milieu du modèle
Les auteurs examinent ces modèles couche par couche pour voir où l’attention se porte réellement pendant que le modèle forme une réponse. De manière surprenante, ils constatent que le modèle sait souvent où regarder dans l’image — en particulier dans ses couches intermédiaires. Par exemple, même lorsqu’il affirme à tort que le ruban est blanc au lieu de rouge, son attention interne peut rester fortement concentrée sur la région réelle du ruban. À mesure que l’information afflue vers les couches profondes, toutefois, ce focus visuel s’estompe et est progressivement éclipsé par des habitudes linguistiques et des attentes générales de scène. Le problème est donc moins une cécité qu’une perte de vue des détails en cours de traitement.
Un module qui réaligne l’attention
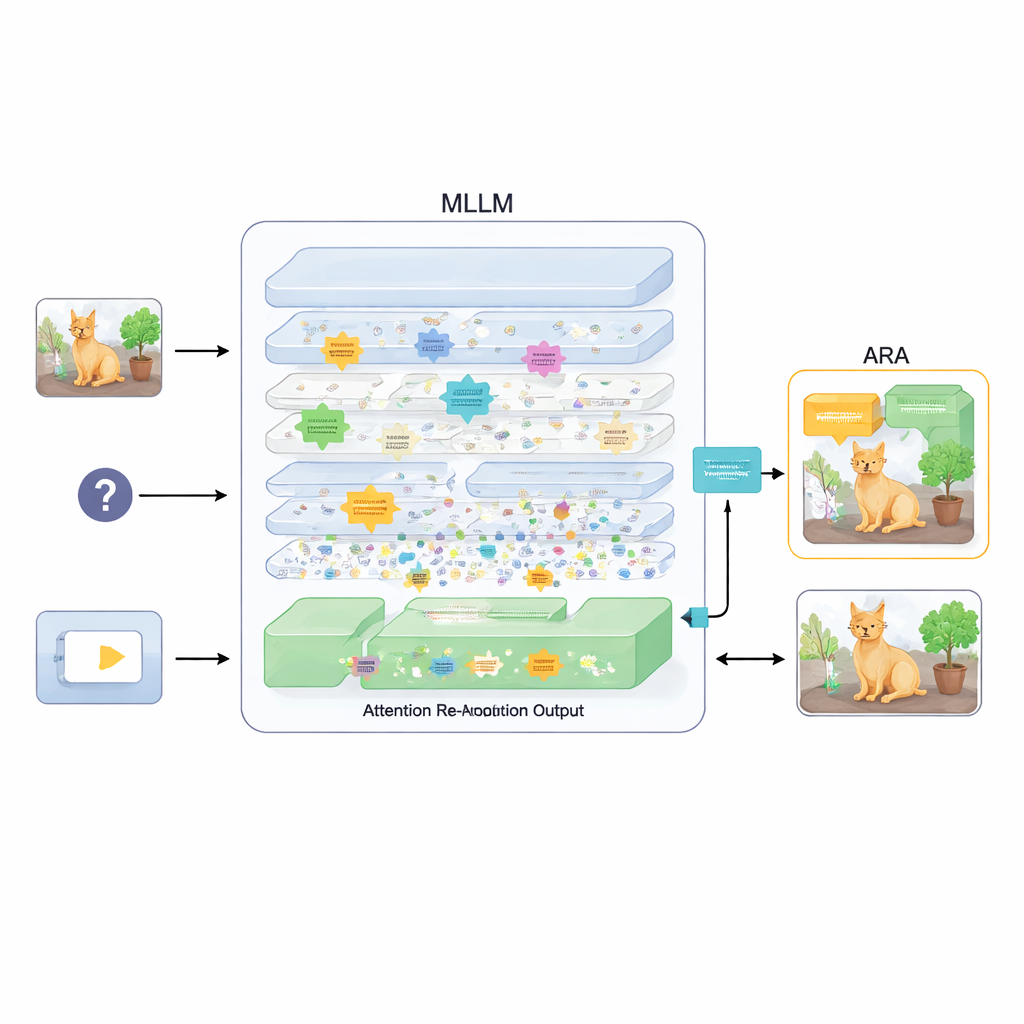
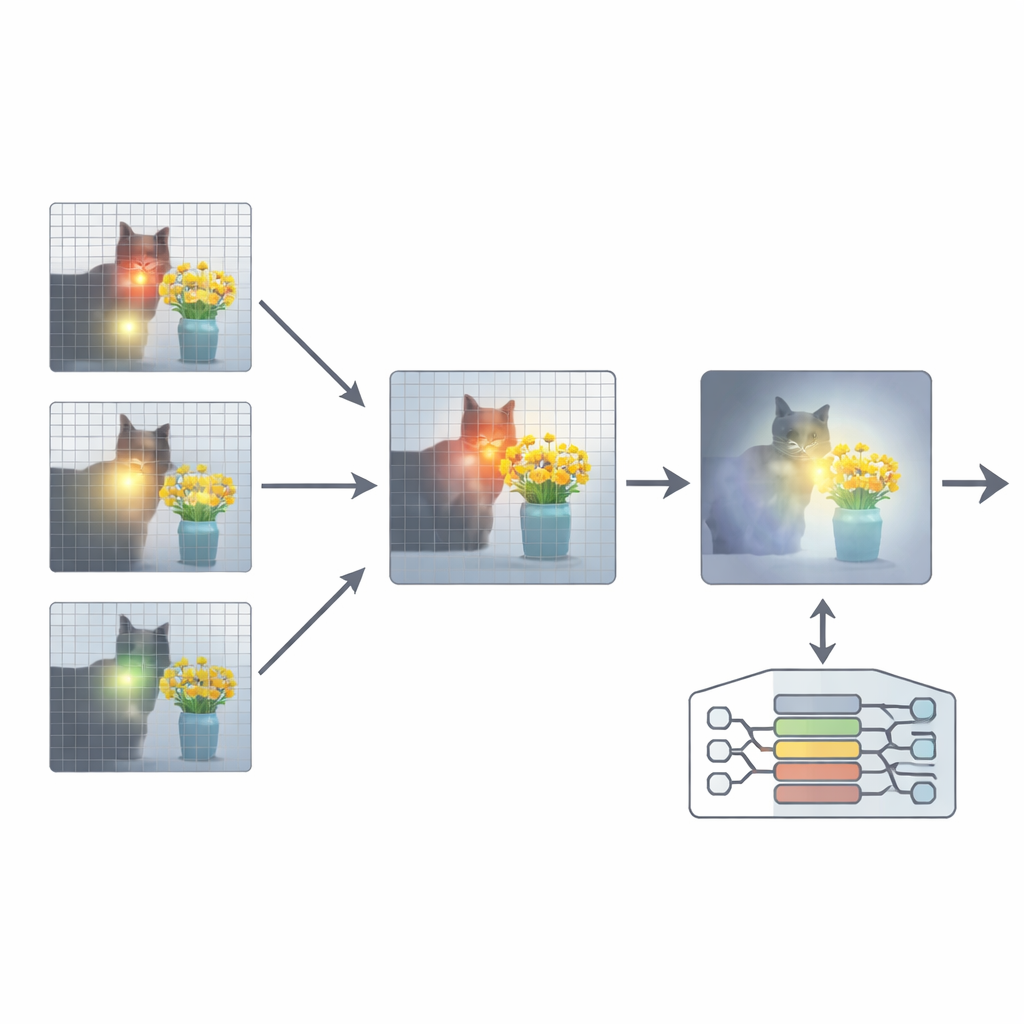
Pour remédier à cela, l’article propose un ajout appelé Réalignement de l’Attention (ARA). Plutôt que de modifier les paramètres du modèle ou de le réentraîner, ARA exploite les cartes d’attention du modèle dans les couches intermédiaires. Il identifie d’abord les « têtes centrées sur l’image » — des sous‑composants du modèle qui se concentrent de façon fiable sur les régions liées à la question posée, et pas seulement sur ce qui est visuellement le plus saillant. Il évalue ensuite chaque couche selon la netteté et la confiance de son focus, et sélectionne les meilleures couches pour chaque question. À partir de ces couches choisies, ARA fusionne leurs cartes d’attention en une image unique et épurée de l’endroit où le modèle considère réellement que se trouvent les preuves visuelles importantes.
Laisser le modèle voir uniquement ce qui importe
ARA transforme ensuite cette attention fusionnée en un simple masque sur l’image : les zones importantes pour le modèle restent visibles, tandis que les régions moins pertinentes sont atténuées ou masquées. Cette image masquée est réinjectée dans le modèle lors de la génération de la réponse, l’incitant doucement à fonder sa réponse sur les régions mises en évidence. Le masquage est adaptatif, il capture à la fois des détails locaux précis (comme un petit panneau ou un mot dans un document) et le contexte plus large lorsque nécessaire. Grâce à des expériences rigoureuses sur plusieurs bancs d’essai — allant de la lecture de texte dans des images et des documents à la réponse à des questions générales et à des tests conçus pour révéler les hallucinations — les auteurs montrent qu’ARA améliore systématiquement la précision et réduit les contenus inventés, et qu’il fonctionne avec différents MLLM populaires sans entraînement supplémentaire.
Une vision plus nette, le même cerveau
En termes simples, ce travail dote les modèles image‑langage existants de meilleures lunettes plutôt que d’un nouveau cerveau. En retrouvant et en renforçant le focus de niveau intermédiaire du modèle sur les bonnes parties d’une image, ARA l’aide à décrire et à raisonner sur les détails visuels de manière plus fidèle. L’approche n’accorde pas miraculeusement plus de sens commun ou de savoir encyclopédique ; elle s’attaque plutôt à un goulot pratique : s’assurer que le modèle fonde réellement ses réponses sur ce qui se trouve devant lui. Alors que ces systèmes sont de plus en plus utilisés pour lire des documents, analyser des scènes réelles ou assister dans des décisions critiques pour la sécurité, des méthodes comme ARA qui ancrent leurs récits à l’image peuvent rendre les outils d’IA plus dignes de confiance et plus fiables pour les utilisateurs quotidiens.
Citation: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Mots-clés: IA multimodale, réponse visuelle aux questions, mécanismes d’attention, réduction des hallucinations, modèles vision-langage