Clear Sky Science · nl
Aandachts-herschikking in multimodale grote taalmodellen via tussenlaagsturing
Waarom slimere beeldlezers ertoe doen
Wanneer we hedendaagse AI-systemen vragen stellen over afbeeldingen—zoals “Welke kleur heeft het lint?” of “Wat staat er op dit verkeersbord?”—verwachten we dat ze zorgvuldig naar de afbeelding kijken. In werkelijkheid leunen veel multimodale AI-modellen, die visie en taal combineren, vaak meer op wat ze uit tekst “weten” dan op wat ze daadwerkelijk zien. Dat kan ertoe leiden dat ze met vertrouwen objecten beschrijven die er niet zijn of kleine details, zoals fijne tekst, verkeerd lezen. Dit artikel introduceert een manier om zulke modellen zachtjes terug naar het beeld zelf te leiden, zodat ze aandacht besteden aan de juiste visuele details zonder ze helemaal opnieuw te hoeven trainen.
Wanneer woorden overstemmen wat de ogen zien
Moderne multimodale grote taalmodellen (MLLM's) combineren een krachtige tekstmotor met een visiemodule, waardoor ze scènes kunnen beschrijven, vragen over grafieken of documenten beantwoorden en wereldkennis met beeldinformatie kunnen samenbrengen. Toch zijn deze modellen vatbaar voor “hallucinaties”: ze kunnen beweren dat er een hond op een foto staat terwijl er alleen een kat is, of een verkeerde kleur, aantal of positie van objecten raden. Eerdere studies suggereerden dat deze fouten ontstaan omdat het taalgedeelte van het model het redeneren domineert en vertrouwt op bekende patronen uit tekst in plaats van op de specifieke pixels voor zich.
Verborgen focus in het midden van het model
De auteurs kijken in deze modellen, laag voor laag, om te zien waar de aandacht echt naartoe gaat terwijl het model een antwoord vormt. Verrassend genoeg blijken de modellen vaak wel te weten waar ze naar moeten kijken in de afbeelding—vooral in hun tussenliggende lagen. Zo kan het model, zelfs wanneer het ten onrechte zegt dat een lint wit is in plaats van rood, intern nog steeds scherp gericht zijn op het daadwerkelijke lintgebied. Naarmate de informatie naar diepere lagen stroomt, vervaagt deze visuele focus echter en wordt ze geleidelijk overschaduwd door taalgewoonten en algemene sceneverwachtingen. Het probleem is dus minder een gebrek aan zicht en meer het verlies van details onderweg.
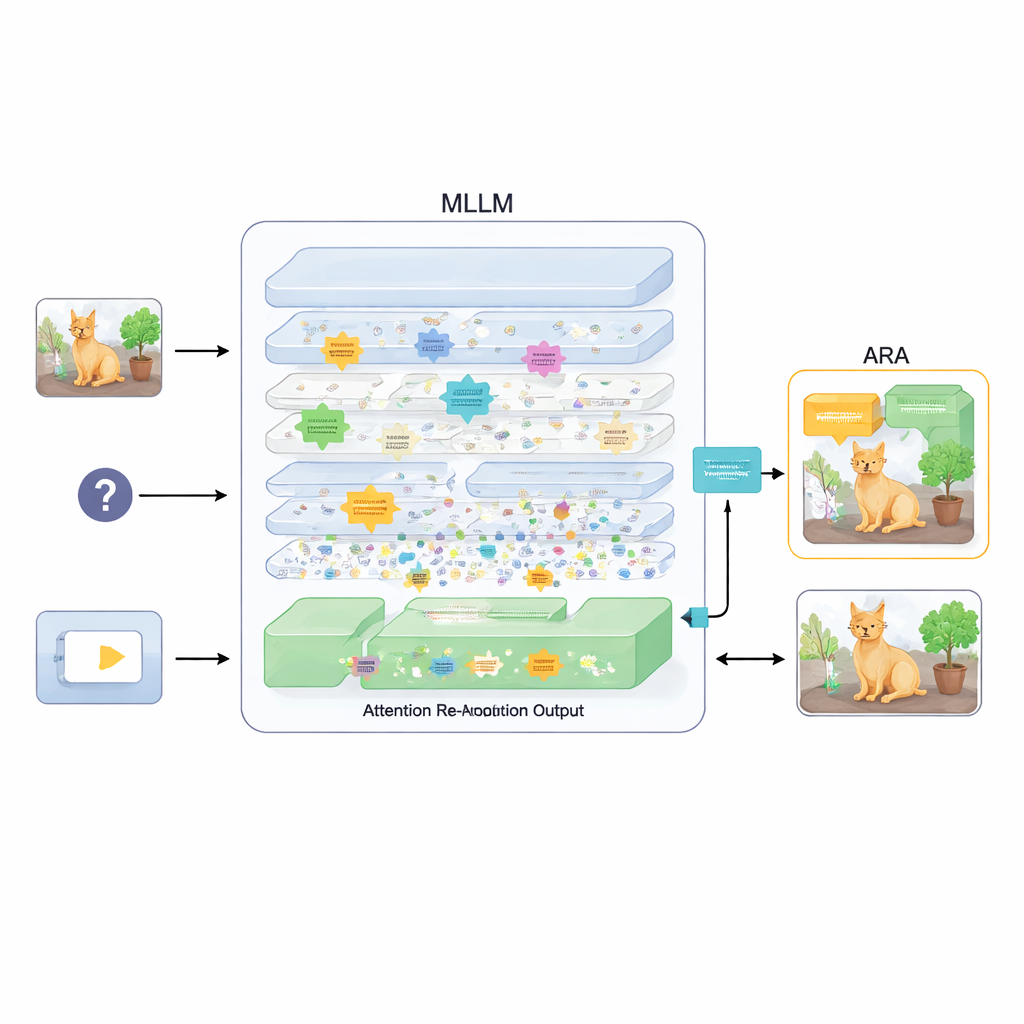
Een plug-in die de aandacht heruitlijnt
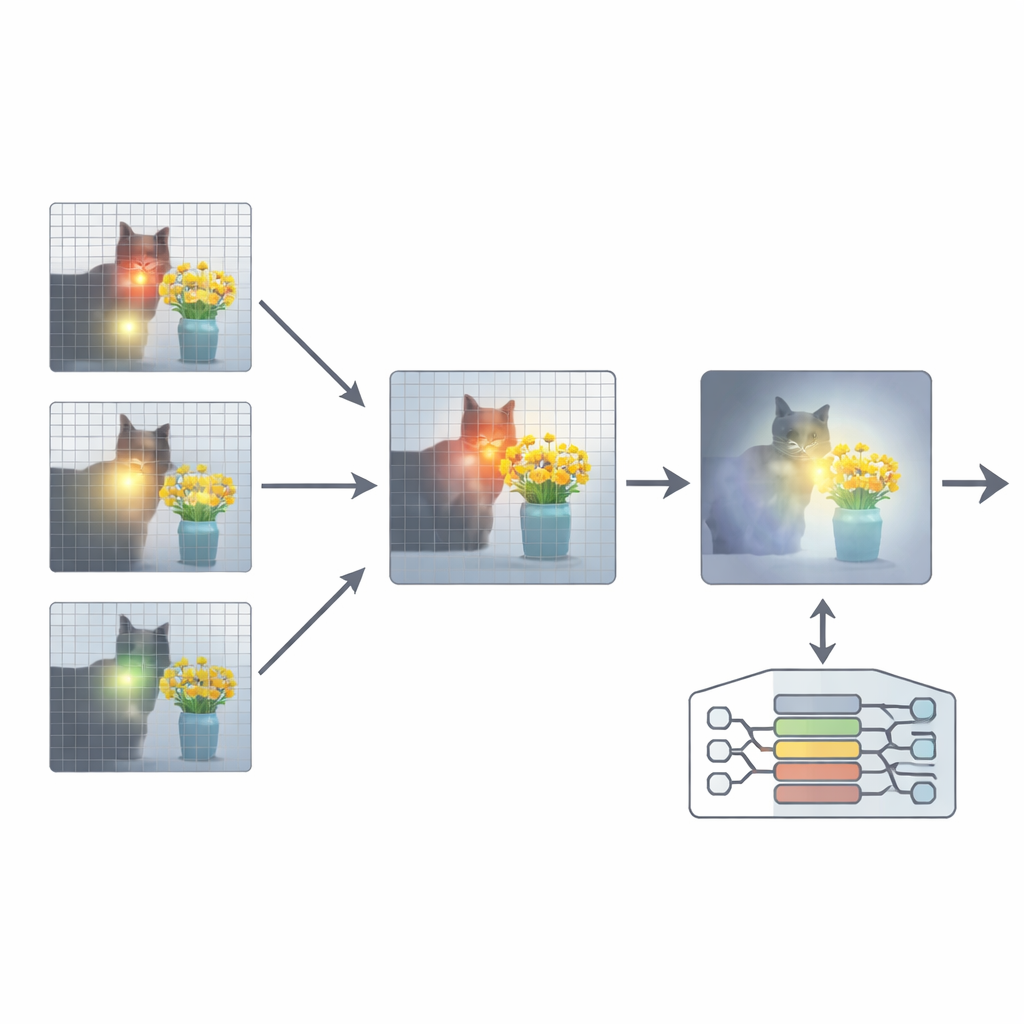
Om dit te verhelpen stelt het artikel een toevoeging voor genaamd Attention Re-Alignment (ARA). In plaats van de parameters van het model te wijzigen of het opnieuw te trainen, maakt ARA gebruik van de eigen aandachtskaarten van het model in de middenlagen. Het identificeert eerst die “beeldgerichte” heads—onderdelen van het model die betrouwbaar concentreren op regio's die verband houden met de vraag van de gebruiker, en niet alleen op wat visueel het meest opvallend is. Vervolgens beoordeelt het elke laag op hoe scherp en zelfverzekerd die focust en selecteert het voor elke vraag de beste paar lagen. Uit deze gekozen lagen fuseert ARA hun aandachtskaarten tot één duidelijke weergave van waar het model werkelijk gelooft dat het belangrijkste visuele bewijs ligt.
Het model alleen laten zien wat ertoe doet
ARA zet deze gefuseerde aandacht vervolgens om in een eenvoudige maskering over de afbeelding: gebieden waar het model veel waarde aan hecht blijven zichtbaar, terwijl minder relevante regio's gedimd of geblokkeerd worden. Deze gemaskeerde afbeelding wordt tijdens het genereren van het antwoord terug aan het model gevoerd, waardoor het zachtjes gedwongen wordt zijn respons te funderen op de gemarkeerde gebieden. De maskering is adaptief, zodat zowel precieze lokale details (zoals een klein bordje of een woord in een document) als de bredere context worden vastgelegd wanneer dat nodig is. Door zorgvuldige experimenten op verschillende benchmarks—variërend van het lezen van tekst in afbeeldingen en documenten tot algemene vraagbeantwoording en tests die specifiek ontworpen zijn om hallucinaties bloot te leggen—tonen de auteurs aan dat ARA consequent de nauwkeurigheid verbetert en verzonnen inhoud vermindert, en dat het werkt voor verschillende populaire MLLM's zonder extra training.
Scherper zicht, hetzelfde brein
In gewone bewoordingen geeft dit werk bestaande beeld–taalmodellen een beter paar brilglazen in plaats van een nieuw brein. Door de eigen mid-level focus van het model op de juiste delen van een afbeelding te herstellen en te versterken, helpt ARA het model visuele details trouwer te beschrijven en te redeneren. De benadering verleent het model niet op magische wijze diepere commonsense- of encyclopedische kennis; in plaats daarvan pakt het een praktisch knelpunt aan: ervoor zorgen dat het model zijn antwoorden echt baseert op wat voor zich ligt. Nu deze systemen steeds vaker worden gebruikt bij taken als het lezen van documenten, het analyseren van scenes in de echte wereld of het assisteren bij veiligheidkritische beslissingen, kunnen methoden zoals ARA die verhalen aan het beeld verankeren AI-hulpmiddelen betrouwbaarder en geloofwaardiger maken voor alledaagse gebruikers.
Bronvermelding: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Trefwoorden: multimodale AI, visuele vraagbeantwoording, aandachtsmechanismen, vermindering van hallucinaties, visie-taalmodellen