Clear Sky Science · pt
Realinhamento de atenção em modelos de linguagem multimodais via orientação de camadas intermediárias
Por que leitores de imagem mais inteligentes importam
Quando perguntamos a sistemas de IA atuais sobre imagens — como “De que cor é a fita?” ou “O que diz esta placa de rua?” — esperamos que eles observem atentamente a imagem. Na prática, muitos modelos multimodais, que combinam visão e linguagem, tendem a se apoiar mais no que “sabem” a partir de texto do que no que realmente veem. Isso pode levá‑los a descrever com segurança objetos que não existem ou a interpretar mal detalhes finos, como textos pequenos. Este artigo apresenta uma forma de direcionar suavemente esses modelos de volta à própria imagem, ajudando‑os a prestar atenção aos detalhes visuais certos sem re-treiná‑los do zero.
Quando as palavras abafam o que os olhos veem
Modelos multimodais de grande porte modernos (MLLMs) combinam um motor de texto poderoso com um módulo de visão, permitindo descrever cenas, responder a perguntas sobre gráficos ou documentos e integrar conhecimento de mundo ao que está na imagem. Ainda assim, esses modelos são propensos a “alucinações”: podem afirmar que há um cachorro numa foto que mostra apenas um gato, ou errar a cor, número ou posição de objetos. Estudos anteriores sugeriram que esses erros surgem porque a parte de linguagem do modelo domina o raciocínio, apoiando‑se em padrões familiares extraídos da leitura em vez dos pixels específicos à sua frente.
Foco oculto no meio do modelo
Os autores investigam esses modelos camada por camada para ver para onde a atenção realmente vai enquanto o modelo forma uma resposta. Surpreendentemente, descobrem que o modelo frequentemente sabe onde olhar na imagem — especialmente em suas camadas intermediárias. Por exemplo, mesmo quando afirma erroneamente que uma fita é branca em vez de vermelha, sua atenção interna pode ainda estar nitidamente focada na região real da fita. Conforme a informação flui para camadas mais profundas, porém, esse foco visual se torna difuso e é gradualmente ofuscado por hábitos de linguagem e expectativas gerais da cena. O problema, portanto, é menos uma cegueira e mais uma perda de detalhes ao longo do caminho.
Um plug‑in que realinha a atenção
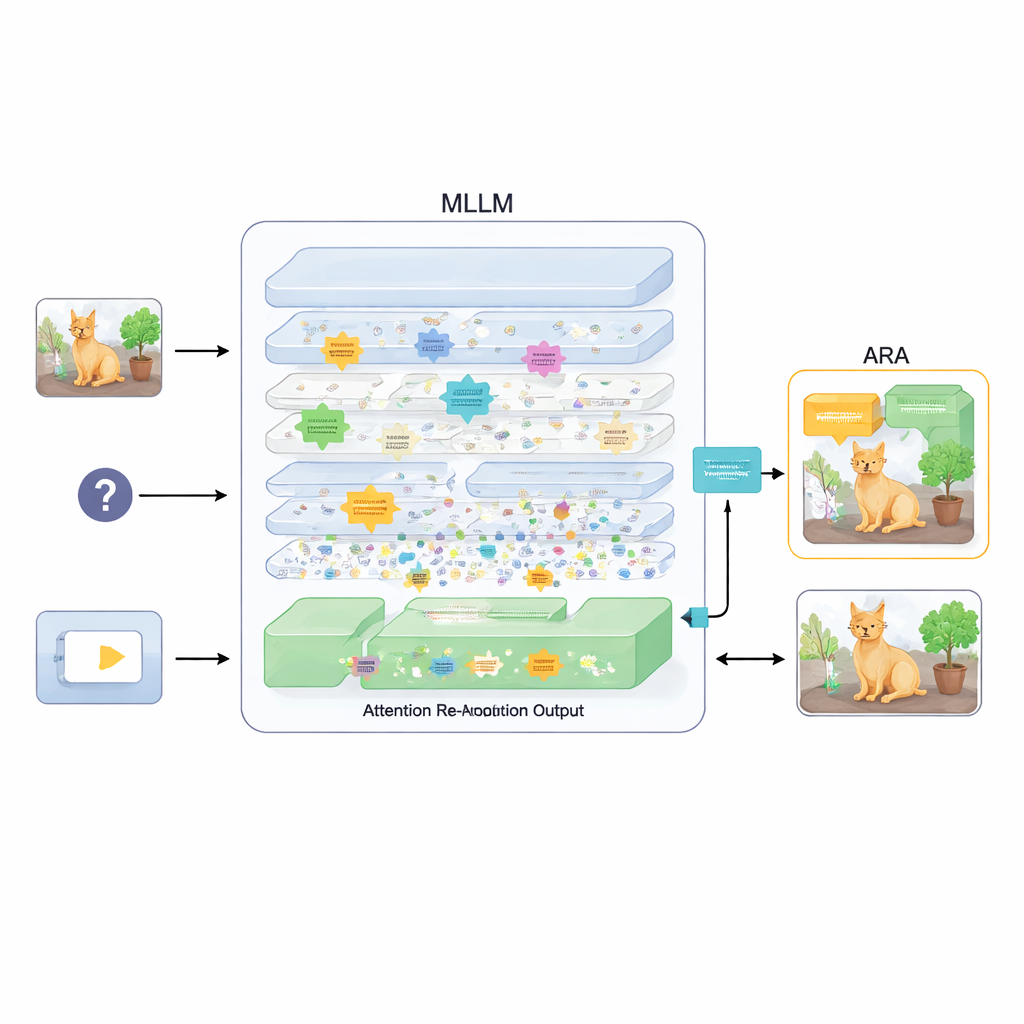
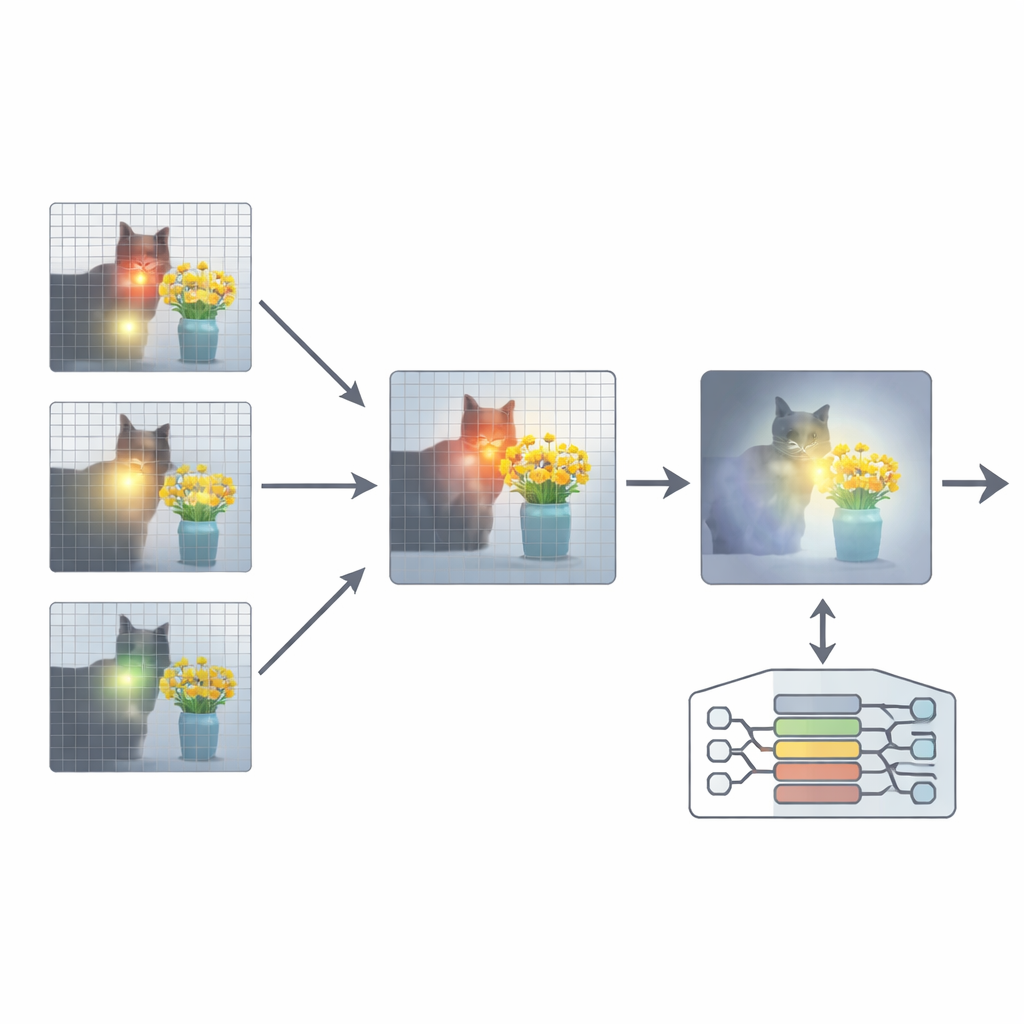
Para resolver isso, o artigo propõe um complemento chamado Re-Alinhamento de Atenção (ARA). Em vez de alterar os parâmetros do modelo ou re-treiná‑lo, o ARA explora os próprios mapas de atenção do modelo nas camadas intermediárias. Primeiro ele identifica as “cabeças centradas na imagem” — partes do modelo que se concentram de forma confiável em regiões relacionadas à pergunta do usuário, e não apenas no que é mais visualmente chamativo. Em seguida, pontua cada camada com base em quão nítido e confiante é seu foco, e seleciona as melhores camadas para cada pergunta. A partir dessas camadas escolhidas, o ARA funde seus mapas de atenção em uma única imagem limpa de onde o modelo realmente acredita estar a evidência visual importante.
Deixando o modelo ver apenas o que importa
O ARA então transforma essa atenção fundida em uma máscara simples sobre a imagem: áreas de forte interesse permanecem visíveis, enquanto regiões menos relevantes são escurecidas ou bloqueadas. Esta imagem mascarada é realimentada ao modelo durante a geração da resposta, forçando suavemente que a resposta se baseie nas regiões destacadas. A máscara é adaptativa, capturando tanto detalhes locais precisos (como uma placa pequena ou uma palavra em um documento) quanto o contexto mais amplo quando necessário. Em experimentos cuidadosos em vários benchmarks — desde leitura de texto em imagens e documentos até perguntas gerais e testes desenhados para expor alucinações — os autores mostram que o ARA melhora consistentemente a precisão e reduz conteúdo inventado, funcionando em diferentes MLLMs populares sem necessidade de treinamento adicional.
Visão mais nítida, mesmo cérebro
Em termos cotidianos, este trabalho dá aos modelos imagem–linguagem existentes um par de óculos melhor, e não um novo cérebro. Ao recuperar e reforçar o próprio foco de nível médio do modelo nas partes corretas de uma imagem, o ARA o ajuda a descrever e raciocinar sobre detalhes visuais com mais fidelidade. A abordagem não outorga magicamente conhecimento de senso comum ou enciclopédico mais profundo; em vez disso, enfrenta um gargalo prático: garantir que o modelo realmente fundamente suas respostas no que está diante dele. À medida que esses sistemas são cada vez mais usados em tarefas como leitura de documentos, análise de cenas do mundo real ou assistência em decisões críticas para a segurança, métodos como o ARA que mantêm suas narrativas ancoradas à imagem podem tornar as ferramentas de IA mais confiáveis e seguras para usuários do dia a dia.
Citação: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Palavras-chave: IA multimodal, resposta visual a perguntas, mecanismos de atenção, redução de alucinações, modelos visão-linguagem