Clear Sky Science · sv
Ominriktningsuppmärksamhet i multimodala stora språkmodeller via vägledning i mellanliggande lager
Varför bättre bildtolkare spelar roll
När vi ställer frågor till dagens AI-system om bilder—som ”Vilken färg har bandet?” eller ”Vad står det på denna vägskylt?”—förväntar vi oss att de granskar bilden noggrant. I verkligheten lutar många multimodala AI-modeller, som kombinerar syn och språk, ofta mer åt vad de ”vet” från text än åt vad de faktiskt ser. Det kan få dem att med säkerhet beskriva objekt som inte finns eller misstolka fina detaljer som små texter. Denna artikel introducerar ett sätt att varsamt styra sådana modeller tillbaka mot bilden, så att de uppmärksammar rätt visuella detaljer utan att behöva tränas om från grunden.
När orden dränker det ögonen ser
Moderna multimodala stora språkmodeller (MLLMs) parar ihop en kraftfull textmotor med en synmodul, vilket gör att de kan beskriva scener, svara på frågor om diagram eller dokument och kombinera världskunskap med vad som finns i en bild. Ändå är dessa modeller benägna att ”hallucinera”: de kan hävda att det finns en hund i en bild där det bara finns en katt, eller gissa fel färg, antal eller position för objekt. Tidigare studier har föreslagit att dessa fel uppstår eftersom språkdelen av modellen dominerar resonemanget och förlitar sig på bekanta mönster från sin läsning snarare än de specifika pixlarna framför den.
Doldd fokus mitt i modellen
Författarna granskar modellernas inre, lager för lager, för att se vart uppmärksamheten egentligen går medan modellen formar ett svar. Överraskande nog finner de att modellen ofta vet var den ska titta i bilden—särskilt i dess mellanliggande lager. Till exempel, även när den felaktigt säger att ett band är vitt istället för rött, kan dess interna uppmärksamhet fortfarande vara skarpt fokuserad på det faktiska bandområdet. När informationen däremot flödar till djupare lager blir detta visuella fokus suddigt och gradvis överröstat av språkvanor och allmänna scenförväntningar. Problemet handlar alltså mindre om blindhet än om att förlora synen för detaljer på vägen.
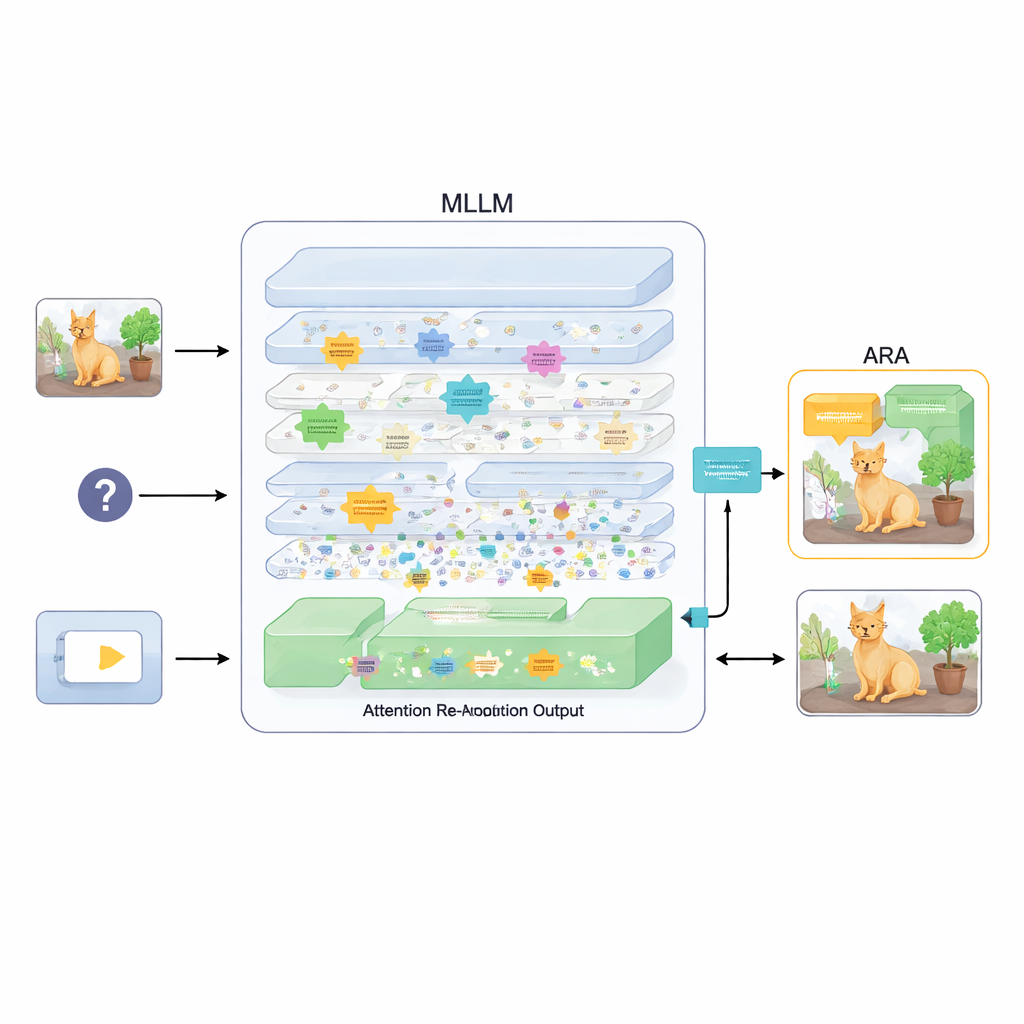
En plug-in som återinriktar uppmärksamheten
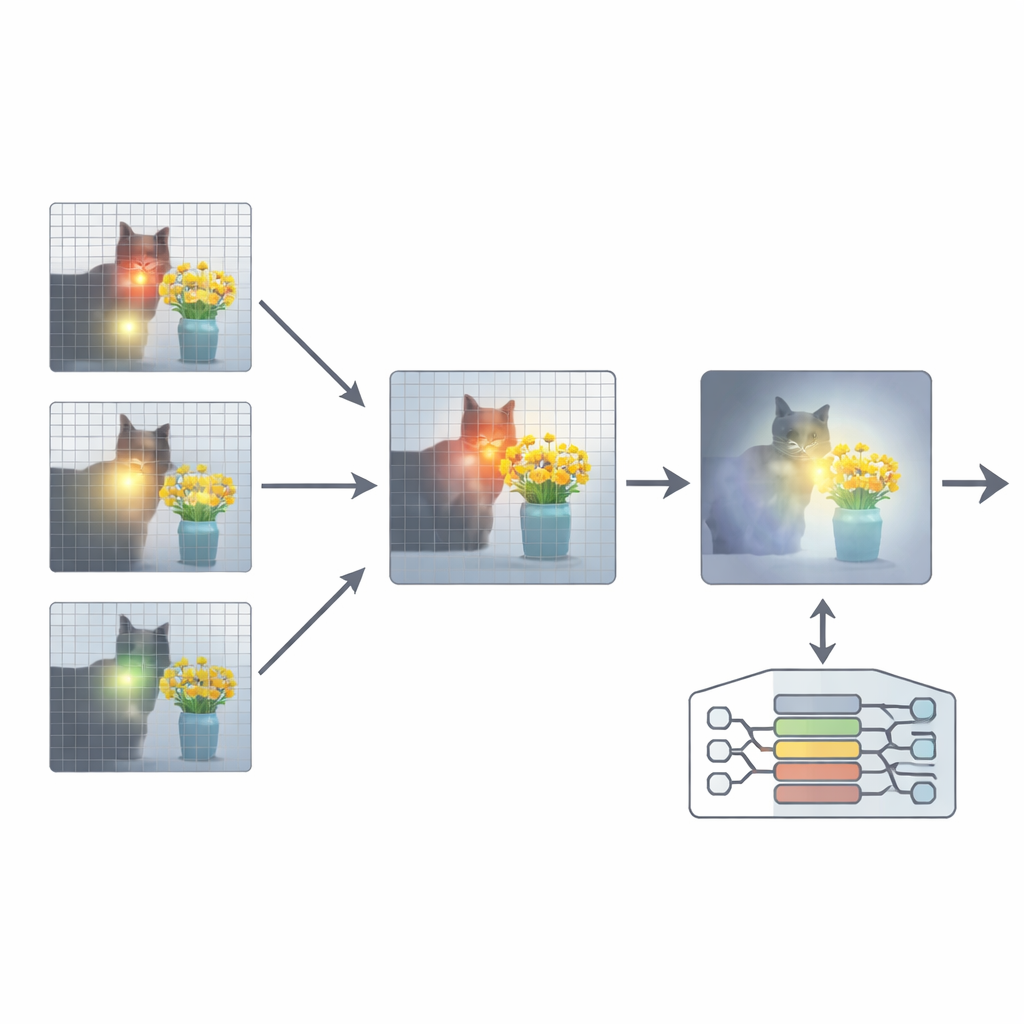
För att åtgärda detta föreslår artikeln ett tillägg kallat Attention Re-Alignment (ARA). Istället för att ändra modellens parametrar eller träna om den, utnyttjar ARA modellens egna uppmärksamhetskartor i mellanlagren. Det identifierar först de ”bildcentrerade” huvudena—delar av modellen som konsekvent koncentrerar sig på regioner kopplade till användarens fråga, inte bara på det som är visuellt mest iögonfallande. Därefter poängsätter det varje lager baserat på hur skarpt och självsäkert det fokuserar, och väljer de bästa få lagren för varje fråga. Från dessa utvalda lager smälter ARA samman deras uppmärksamhetskartor till en enda, tydlig bild av var modellen faktiskt tror att den viktiga visuella evidensen finns.
Låta modellen se endast det som betyder något
ARA omvandlar sedan denna sammanslagna uppmärksamhet till en enkel mask över bilden: områden som modellen bryr sig mycket om förblir synliga, medan mindre relevanta regioner dämpas eller blockeras. Denna maskerade bild matas tillbaka in i modellen under svarsgenereringen, vilket varsamt tvingar den att grundfästa sitt svar i de markerade regionerna. Maskningen är adaptiv, så den fångar både precisa lokala detaljer (såsom en liten skylt eller ett ord i ett dokument) och den bredare kontexten när det behövs. Genom noggranna experiment på flera benchmarks—från att läsa text i bilder och dokument till allmän frågesvar och tester särskilt utformade för att exponera hallucinationer—visar författarna att ARA konsekvent förbättrar noggrannheten och minskar påhittat innehåll, och att det fungerar över olika populära MLLMs utan extra träning.
Skarpare syn, samma hjärna
I vardagliga termer ger detta arbete befintliga bild–språkmodeller ett bättre par glasögon snarare än en ny hjärna. Genom att återvinna och förstärka modellens eget mellanskiktsfokus på rätt delar av en bild hjälper ARA den att beskriva och resonera kring visuella detaljer mer troget. Metoden förmedlar inte magiskt djupare sunt förnuft eller encyklopedisk kunskap; istället tar den itu med en praktisk flaskhals: att se till att modellen verkligen baserar sina svar på vad som finns framför den. Eftersom dessa system alltmer används i situationer som att läsa dokument, analysera verkliga scener eller bistå vid säkerhetskritiska beslut, kan metoder som ARA som håller deras berättelser förankrade i bilden göra AI-verktyg mer pålitliga och tillförlitliga för vanliga användare.
Citering: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Nyckelord: multimodal AI, visuell frågesvar, uppmärksamhetsmekanismer, minskning av hallucinationer, visions-språkmodeller