Clear Sky Science · pl
Wyrównywanie uwagi w multimodalnych dużych modelach językowych za pomocą wskazówek z warstw pośrednich
Dlaczego mądrzejsi czytelnicy obrazów mają znaczenie
Kiedy pytamy współczesne systemy AI o obrazy — na przykład „Jakiego koloru jest wstążka?” lub „Co mówi ten znak drogowy?” — oczekujemy, że uważnie przyjrzą się obrazowi. W praktyce wiele multimodalnych modeli AI, łączących wzrok i język, częściej polega na tym, co „wie” z tekstu, niż na tym, co naprawdę widzi. Może to prowadzić do pewnych stwierdzeń o obiektach, których nie ma, albo do błędnego odczytania drobnych detali, jak mały tekst. W artykule zaproponowano sposób delikatnego skierowania takich modeli z powrotem ku obrazowi, pomagając im zwracać uwagę na właściwe elementy wizualne bez konieczności całkowitego ponownego trenowania.
Kiedy słowa zagłuszają to, co widzą oczy
Nowoczesne multimodalne duże modele językowe (MLLM) łączą potężny silnik tekstowy z modułem wizualnym, co pozwala im opisywać sceny, odpowiadać na pytania dotyczące wykresów czy dokumentów oraz łączyć wiedzę o świecie z tym, co jest na obrazie. Jednak modele te są podatne na „halucynacje”: mogą twierdzić, że na zdjęciu jest pies, podczas gdy widać tylko kota, albo źle odgadnąć kolor, liczbę czy położenie obiektów. Wcześniejsze badania sugerowały, że te błędy wynikają z dominacji części językowej w procesie wnioskowania, która opiera się na znanych wzorcach z lektury, zamiast na konkretnych pikselach przed sobą.
Ukryte skupienie w środkowych warstwach modelu
Autorzy zaglądają do wnętrza tych modeli, warstwa po warstwie, aby zobaczyć, dokąd naprawdę kieruje się uwaga podczas formułowania odpowiedzi. Ku zaskoczeniu stwierdzają, że model często wie, gdzie spojrzeć na obraz — zwłaszcza w warstwach pośrednich. Na przykład, nawet gdy błędnie twierdzi, że wstążka jest biała zamiast czerwonej, jego wewnętrzna uwaga może nadal być silnie skupiona na rzeczywistym obszarze wstążki. W miarę przepływu informacji do głębszych warstw to wizualne skupienie jednak się rozmywa i stopniowo ustępuje na rzecz językowych nawyków i ogólnych oczekiwań co do sceny. Problem więc nie polega tyle na niewidzeniu, ile na utracie uwagi na szczegółach po drodze.
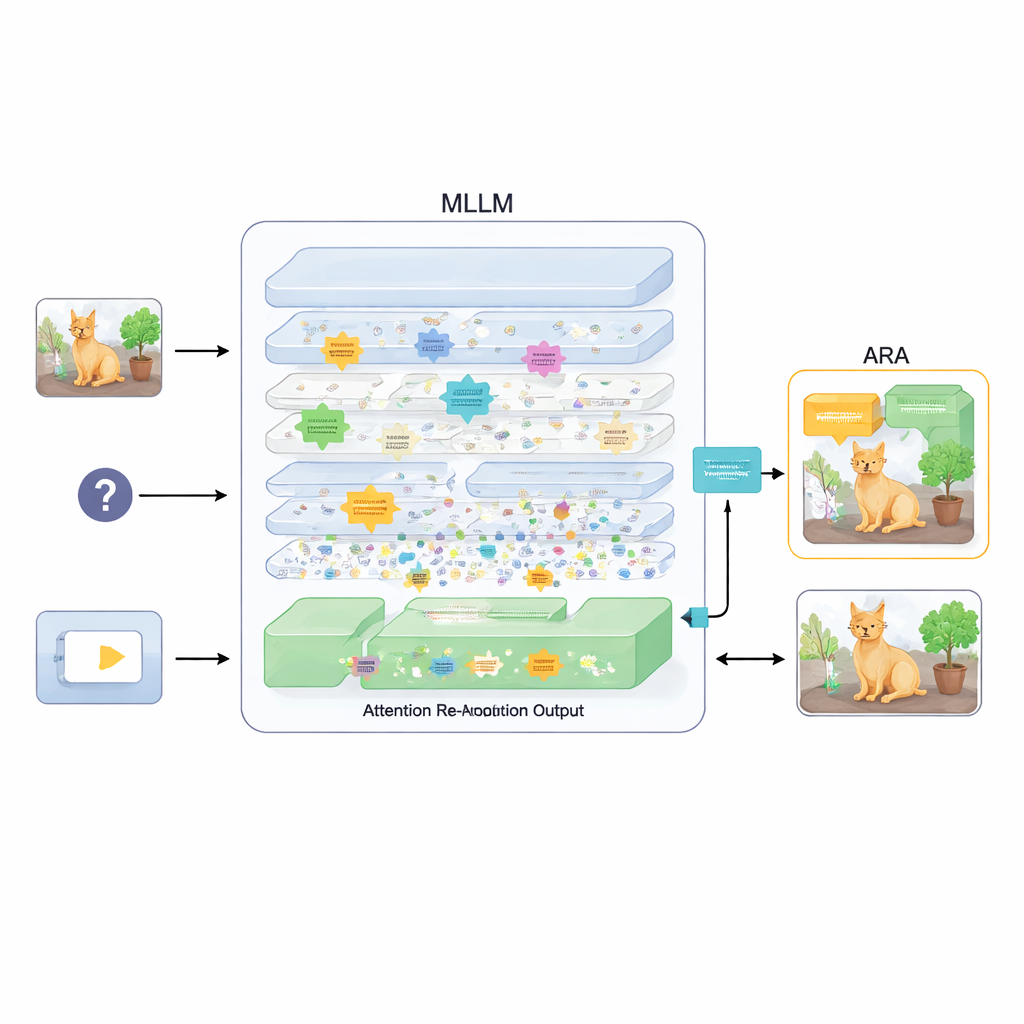
Wtyczka, która wyrównuje uwagę
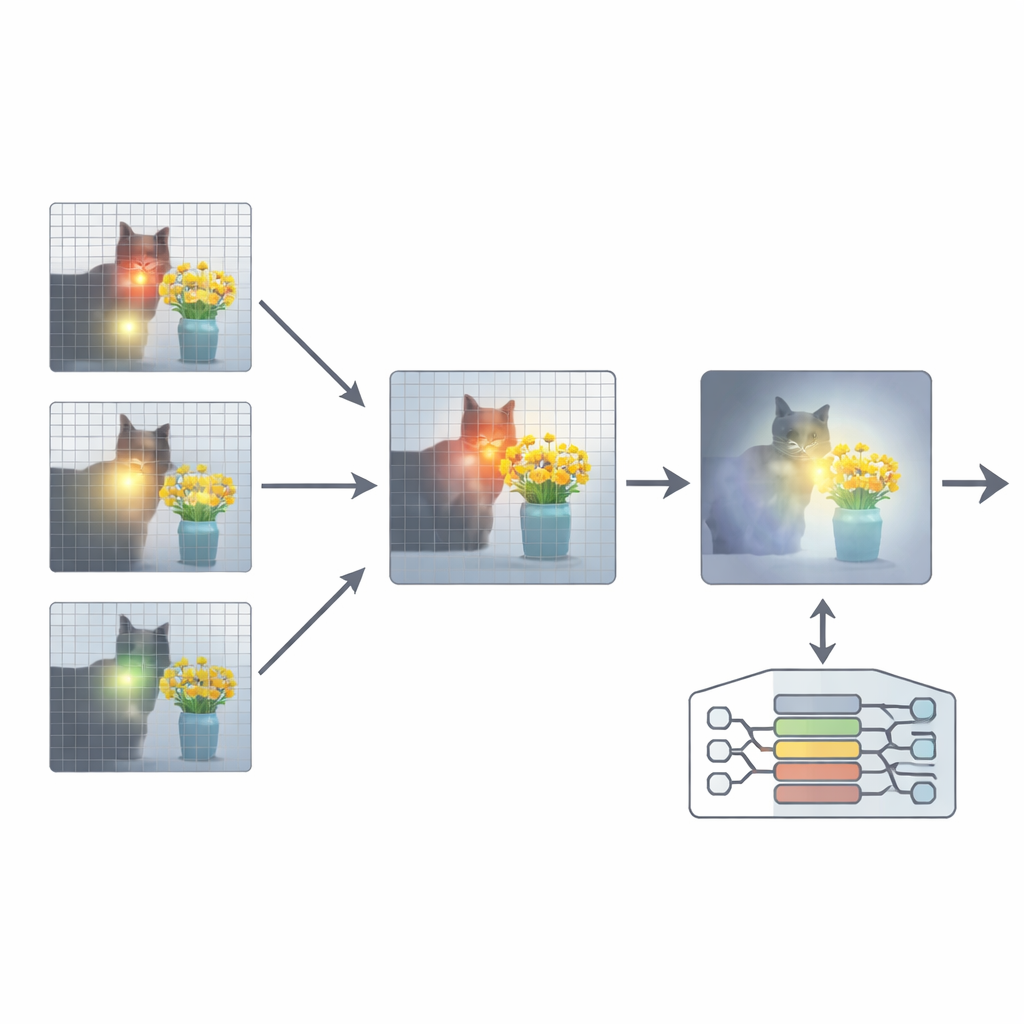
Aby to naprawić, artykuł proponuje dodatek nazwany Attention Re-Alignment (ARA). Zamiast zmieniać parametry modelu czy trenować go od nowa, ARA korzysta z własnych map uwagi modelu w warstwach pośrednich. Najpierw identyfikuje te „skoncentrowane na obrazie” głowy — części modelu, które niezawodnie koncentrują się na regionach związanych z pytaniem użytkownika, a nie tylko na tym, co najbardziej przyciąga wzrok. Następnie ocenia każdą warstwę pod kątem ostrości i pewności skupienia i wybiera najlepsze kilka warstw dla danego pytania. Z wybranych warstw ARA scala ich mapy uwagi w jeden, czysty obraz tego, gdzie model rzeczywiście uważa, że leży ważne dowodowe wsparcie wizualne.
Puszczenie modelowi widoku tylko tego, co ważne
ARA przekształca następnie tę złączoną uwagę w prostą maskę na obrazie: obszary, na których model silnie skupia uwagę, pozostają widoczne, podczas gdy mniej istotne regiony są przyciemniane lub zasłaniane. Taki zamaskowany obraz jest podawany z powrotem do modelu podczas generowania odpowiedzi, delikatnie zmuszając go do ugruntowania swojej odpowiedzi w podświetlonych obszarach. Maskowanie jest adaptacyjne, więc uchwyci zarówno precyzyjne lokalne detale (jak mały znak lub słowo w dokumencie), jak i szerszy kontekst, gdy jest to potrzebne. Dzięki starannym eksperymentom na kilku benchmarkach — od odczytywania tekstu na obrazach i w dokumentach po ogólne odpowiadanie na pytania i testy zaprojektowane specjalnie, by ujawniać halucynacje — autorzy pokazują, że ARA konsekwentnie poprawia dokładność i zmniejsza wymyślone treści, działając przy tym w różnych popularnych MLLM bez konieczności dodatkowego trenowania.
Bardziej ostre widzenie, ten sam mózg
W potocznym ujęciu ta praca daje istniejącym modelom obrazowo‑językowym lepsze okulary zamiast nowego mózgu. Poprzez odzyskanie i wzmocnienie wewnętrznego, średniopoziomowego skupienia modelu na właściwych częściach obrazu, ARA pomaga mu wierniej opisywać i rozumować o szczegółach wizualnych. Podejście to nie nadawuje modelowi nagle głębszej wiedzy zdroworozsądkowej ani encyklopedycznej; zamiast tego rozwiązuje praktyczne wąskie gardło: upewnia się, że model naprawdę opiera swoje odpowiedzi na tym, co jest przed nim. W miarę jak te systemy są coraz częściej używane w zadaniach takich jak czytanie dokumentów, analizowanie scen rzeczywistych czy wspieranie decyzji o krytycznym znaczeniu dla bezpieczeństwa, metody takie jak ARA, które utrzymują ich relacje z obrazem, mogą uczynić narzędzia AI bardziej godnymi zaufania i niezawodnymi dla codziennych użytkowników.
Cytowanie: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Słowa kluczowe: sztuczna inteligencja multimodalna, wizualne odpowiadanie na pytania, mechanizmy uwagi, redukcja halucynacji, modele wizja-język