Clear Sky Science · he
יישור תשומת לב במודלים גדולים רב־מודאליים באמצעות הנחיה בשכבות הביניים
למה קוראי תמונות חכמים יותר חשובים
כשאנחנו שואלים מערכות בינה מלאכותית של היום שאלות על תמונות — כמו "איזה צבע הסרט?" או "מה כתוב על שלט הרחוב הזה?" — אנו מצפים שהן יבחנו בקפידה את התמונה. במציאות, רבות מהמערכות הרב־מודאליות שמחברות ראייה ושפה נוטות להסתמך יותר על מה שהן "יודעות" מטקסט מאשר על מה שהן רואות בפועל. זה יכול להוביל לתיאורים בטוחים של פריטים שאינם נמצאים בתמונה או לקריאה שגויה של פרטים עדינים כמו טקסט קטן. המאמר מציג דרך להטות בעדינות מודלים אלה חזרה לעבר התמונה עצמה, ולעזור להם לשים לב לפרטים הוויזואליים הנכונים מבלי לאמן אותם מחדש מהיסוד.
כשמילים מדחרות את מה שהעיניים רואות
מודלים גדולים רב־מודאליים מודרניים (MLLMs) משלבים מנוע טקסט חזק עם מודול ראייה, ומאפשרים להם לתאר סצנות, לענות על שאלות על גרפים או מסמכים ולשלב ידע עולמי עם מה שיש בתמונה. עם זאת, מודלים אלה רגישים ל"הלוצינציות": הם עלולים לטעון שיש כלב בתמונה שבה יש רק חתול, או לנחש בצבע, מספר או מיקום שגוי של אובייקטים. מחקרים קודמים הציעו שהטעויות הללו נובעות מכך שהחלק הלשוני של המודל שולט בתהליכי החשיבה, ומתבסס על דפוסים מוכרים מקריאתו במקום על הפיקסלים הספציפיים שלפניו.
מיקוד חבוי באמצע המודל
המחברים מביטים בתוך המודלים האלה, שכבה אחר שכבה, כדי לראות לאן התשומת לב הולכת בזמן שהמודל בונה תשובה. באופן מפתיע, הם מוצאים שהמודל לעתים קרובות יודע איפה להסתכל בתמונה — במיוחד בשכבות הביניים שלו. לדוגמה, גם כאשר הוא מצהיר בטעות שהסרט לבן במקום אדום, תשומת הלב הפנימית שלו יכולה עדיין להיות ממוקדת בדיוק על אזור הסרט בפועל. כשהמידע זורם לשכבות העמוקות יותר, עם זאת, המיקוד הוויזואלי הזה מתערפל ובהדרגה נמחץ על ידי הרגלי השפה והציפיות הכלליות מהסצנה. הבעיה, אם כן, פחות בעיוורון ויותר באובדן ראייה של פרטים בדרך.
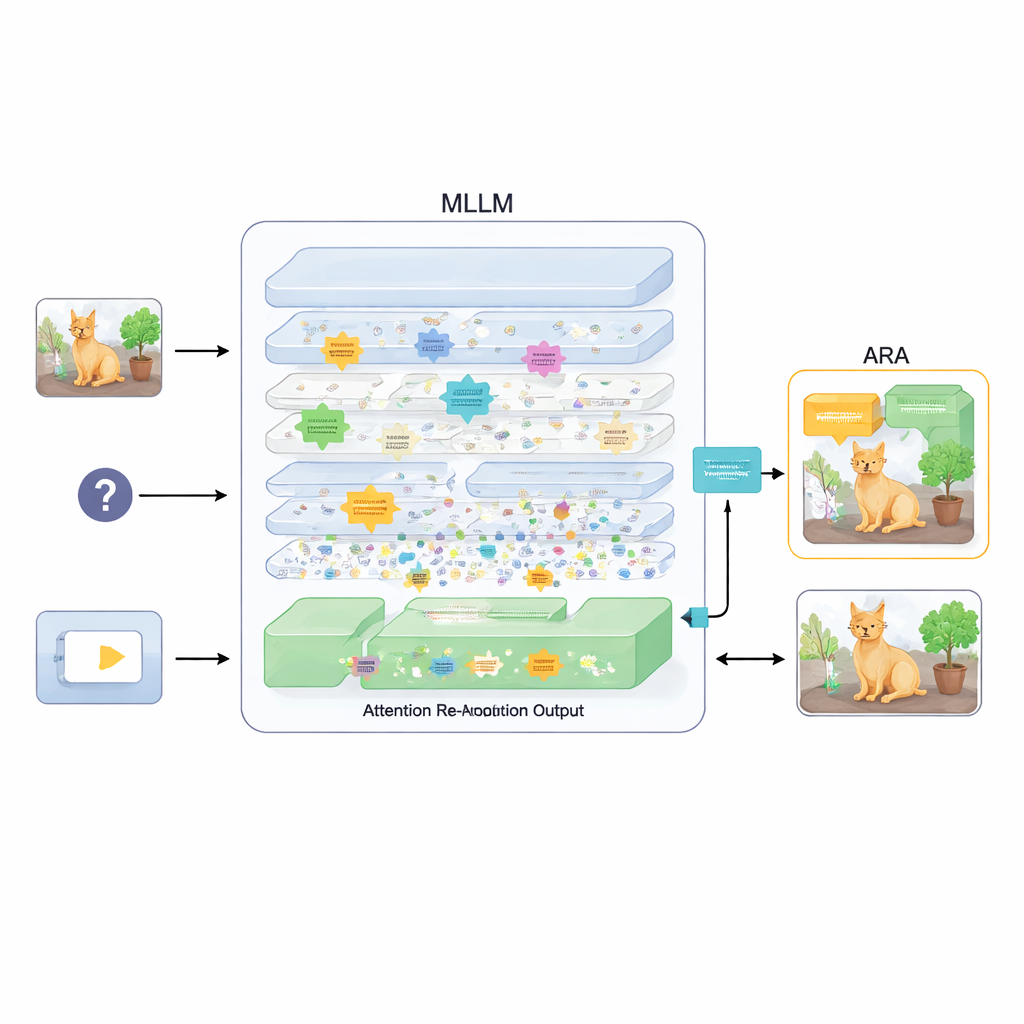
תוסף שמיישר מחדש את התשומת לב
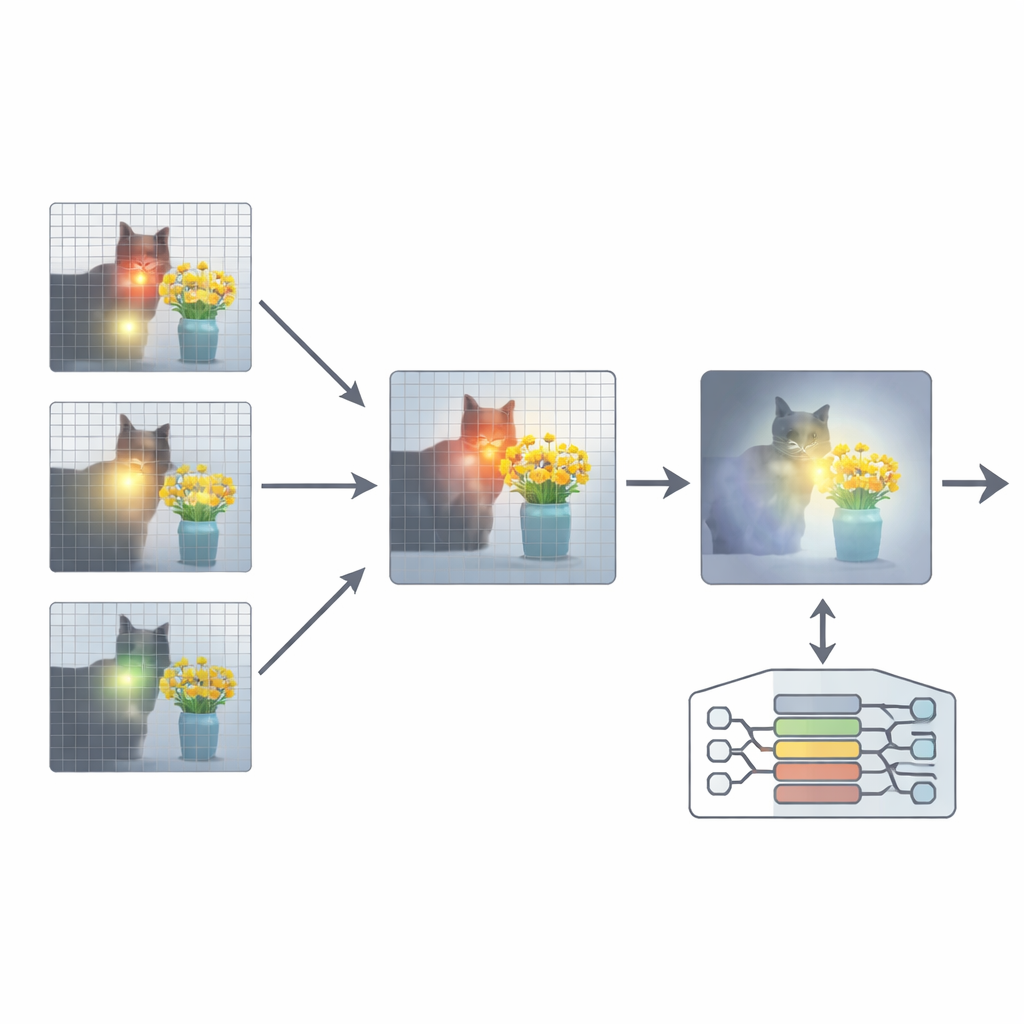
כדי לתקן זאת, המאמר מציע תוסף שנקרא יישור תשומת לב (Attention Re-Alignment, ARA). במקום לשנות את פרמטרי המודל או לאמן אותו מחדש, ARA נוגעת במפות התשומת לב של המודל בשכבות הביניים. היא מזהה תחילה את ה"ראשים" ה"מרוכזים בתמונה" — חלקים במודל שמרוכזים באמינות על אזורים הקשורים לשאלת המשתמש, ולא רק על מה שבולט חזותית. אחר כך היא מדרגת כל שכבה לפי עד כמה היא ממוקדת ובטוחה, ובוחרת את כמה השכבות הטובות ביותר עבור כל שאלה. מתוך השכבות הנבחרות האלה, ARA מאחדת את מפות התשומת לב לתמונה אחת, נקייה וברורה של המקום שבו המודל באמת מאמין שהראיות הוויזואליות החשובות נמצאות.
להשאיר למודל לראות רק את מה שחשוב
ARA הופכת אז את התשומת לב המאוחדת למסכה פשוטה על התמונה: אזורים שהמודל דואג אליהם בחוזקה נותרו גלויים, בעוד שאזורים פחות רלוונטיים מואפלים או נחסמים. תמונה ממוסכת זו מוזנת חזרה למודל במהלך יצירת התשובה, וכופה בעדינות שהוא יתבסס על האזורים המודגשים. ההטלה היא אדפטיבית, כך שהיא תופסת גם פרטים מקומיים מדויקים (כמו שלט קטן או מילה במסמך) וגם את ההקשר הרחב יותר כשנדרש. דרך ניסויים קפדניים במבחנים שונים — החל מקריאת טקסט בתמונות ובמסמכים ועד לשאלות כלליות ומבחנים שנועדו לחשוף הלוצינציות במיוחד — המחברים מראים ש-ARA משפרת בעקביות את הדיוק ומפחיתה תוכן מומצא, והיא פועלת על פני כמה MLLMs פופולריים ללא צורך באימון נוסף.
ראייה חדה יותר, אותו מוח
במונחים יומיומיים, עבודה זו נותנת למודלים קיימים של תמונה–שפה זוג משקפיים טוב יותר במקום מוח חדש. על ידי שחזור וחיזוק המיקוד הביניים של המודל על החלקים הנכונים של התמונה, ARA עוזרת לו לתאר ולהסיק לגבי פרטים חזותיים בצורה נאמנה יותר. הגישה אינה נותנת באופן קסום ידע עמוק יותר של שכל פשוט או אנציקלופדי; במקום זאת היא מטפלת בצוואר בקבוק מעשי: להבטיח שהמודל באמת מבסס את תשובותיו על מה שעומד מולו. ככל שמערכות אלה משמשות יותר בתחומים כמו קריאת מסמכים, ניתוח סצנות בעולם האמיתי או סיוע בהחלטות קריטיות לבטיחות, שיטות כמו ARA ששומרות על עיגון התשובות לתמונה יכולות לעשות את כלי ה-AI מהימנים ואמינים יותר למשתמשים היומיומיים.
ציטוט: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
מילות מפתח: בינה רב־מודאלית, מענה חזותי לשאלות, מנגנוני תשומת לב, הפחתת הלוצינציות, מודלים לשפה ולראייה