Clear Sky Science · ru
Перенаправление внимания в мультимодальных больших языковых моделях с помощью руководства на промежуточных слоях
Почему важны умные «читатели» изображений
Когда мы просим современные ИИ-системы ответить на вопросы по картинкам — например, «Какого цвета лента?» или «Что написано на этом дорожном знаке?» — мы ожидаем, что они внимательно посмотрят на изображение. На деле многие мультимодальные модели, объединяющие зрение и язык, чаще опираются на то, что «знают» из текста, а не на то, что действительно видно. Это может приводить к уверенным описаниям отсутствующих объектов или к неверному прочтению мелких деталей, таких как маленький текст. В данной работе предложен способ аккуратно направить такие модели обратно к изображению, помогая им уделять внимание нужным визуальным деталям без полной дообучки.
Когда слова заглушают то, что видят глаза
Современные мультимодальные большие языковые модели (MLLM) сочетают мощный текстовый движок с модулем зрения, что позволяет им описывать сцены, отвечать на вопросы по графикам или документам и совмещать знания о мире с тем, что есть на изображении. Тем не менее эти модели склонны к «галлюцинациям»: они могут утверждать, что на картинке есть собака, где только кот, или ошибаться с цветом, числом или расположением объектов. Ранее предполагалось, что такие ошибки возникают потому, что языковая часть модели доминирует в рассуждениях, опираясь на знакомые текстовые шаблоны, а не на конкретные пиксели перед ней.
Скрытый фокус в середине модели
Авторы заглядывают внутрь моделей, слой за слоем, чтобы понять, куда реально направлено внимание при формировании ответа. Удивительно, но они обнаруживают, что модель часто знает, куда смотреть — особенно на промежуточных слоях. Например, даже когда модель ошибочно говорит, что лента белая вместо красной, её внутренние карты внимания могут быть чётко сосредоточены на самой ленте. По мере прохождения информации в более глубокие слои этот визуальный фокус размывается и постепенно вытесняется языковыми привычками и общими ожиданиями сцены. Проблема, следовательно, заключается не в слепоте модели, а в потере внимания к деталям по ходу обработки.
Плагин, который выравнивает внимание
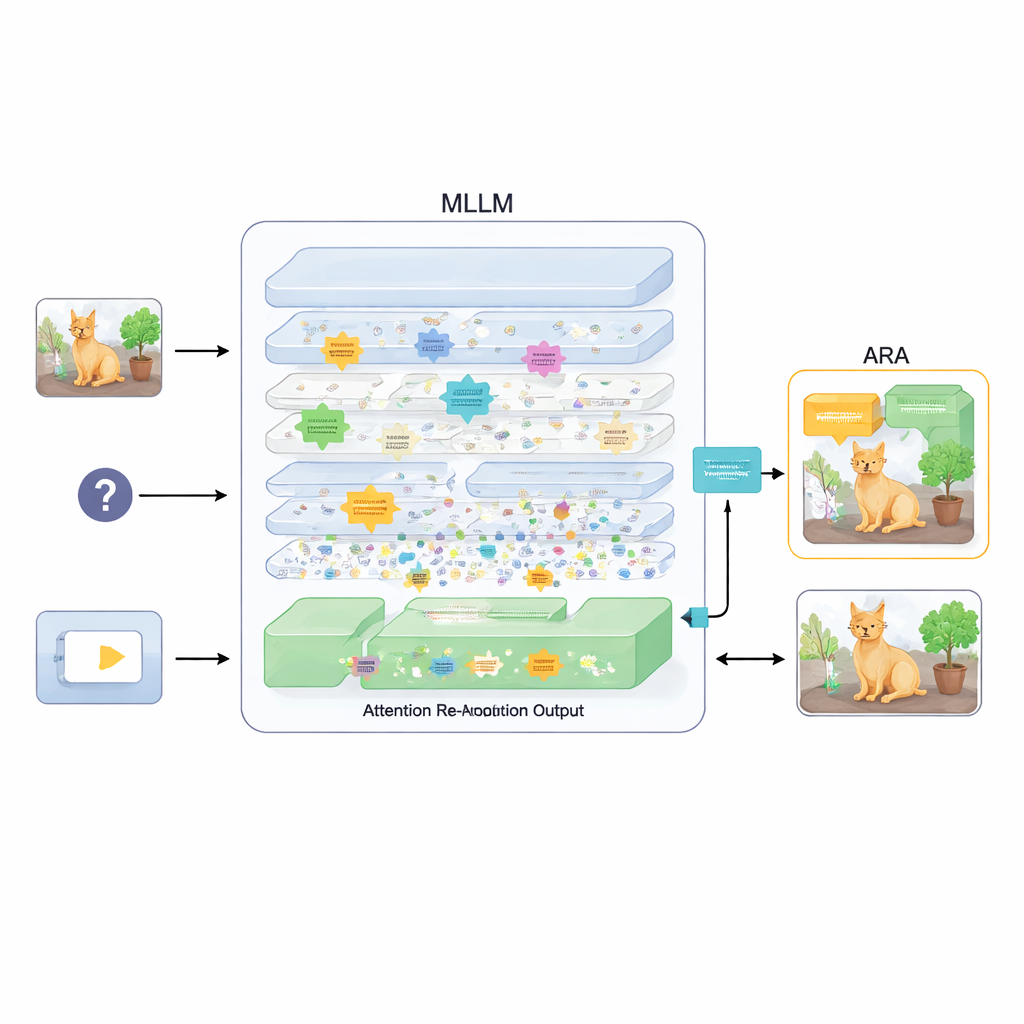
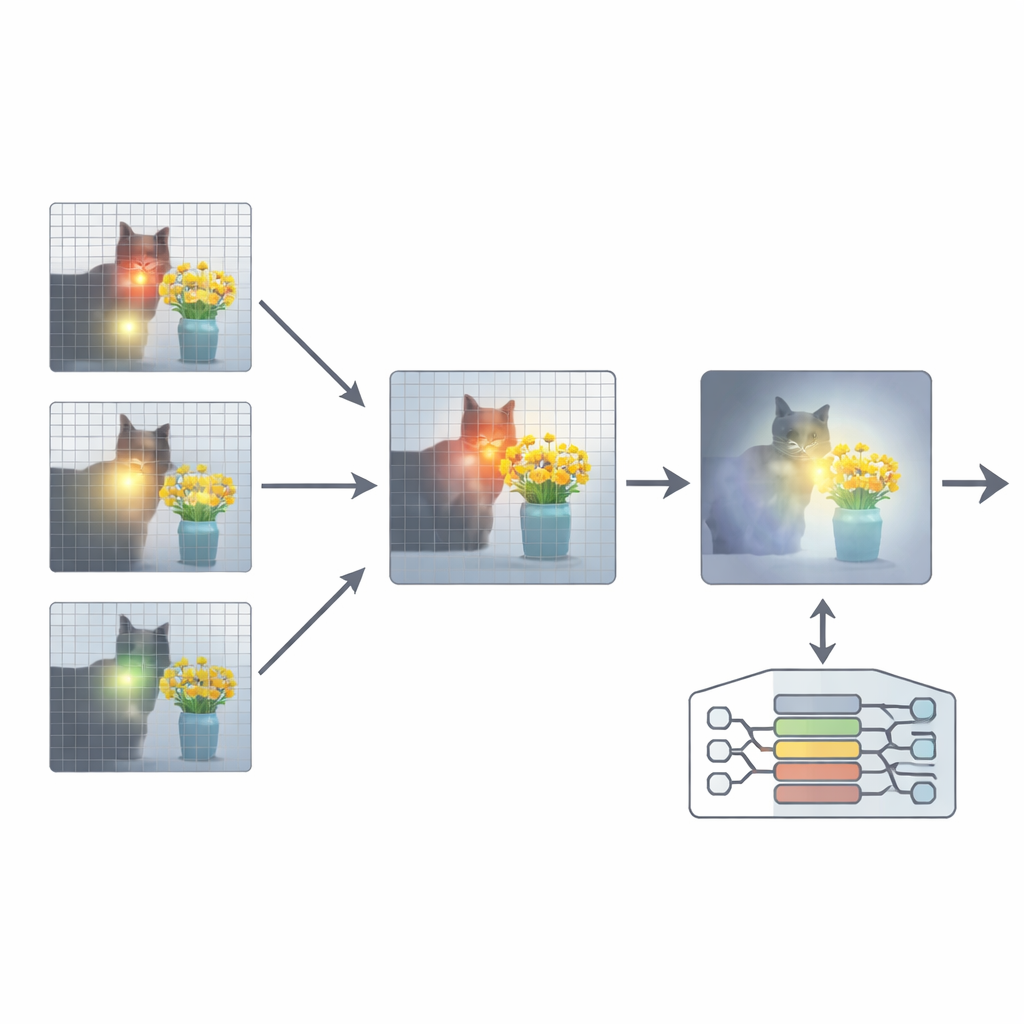
Чтобы исправить это, в статье предлагается дополнение под названием Attention Re-Alignment (ARA). Вместо изменения параметров модели или её дообучения ARA использует собственные карты внимания модели на промежуточных слоях. Сначала метод выявляет «ориентированные на изображение» головы — части модели, которые надёжно фокусируются на областях, связанных с вопросом пользователя, а не просто на самых заметных визуальных элементах. Затем он оценивает каждый слой по тому, насколько чётко и уверенно тот фокусируется, и для каждого запроса выбирает несколько лучших слоёв. Из выбранных слоёв ARA объединяет их карты внимания в единое, аккуратное представление того, где модель действительно считает расположенным важное визуальное доказательство.
Позволяя модели видеть только важное
ARA затем превращает объединённую карту внимания в простую маску поверх изображения: области, на которые модель сильно ориентирована, остаются видимыми, а менее релевантные регионы затемняются или блокируются. Это замаскированное изображение подаётся обратно в модель во время генерации ответа, мягко заставляя её опираться на выделенные области. Маскирование адаптивно, поэтому оно захватывает как точные локальные детали (например, маленький знак или слово в документе), так и более широкий контекст, когда это необходимо. Через тщательные эксперименты на нескольких бенчмарках — от чтения текста на изображениях и в документах до общих вопросов и тестов, специально нацеленных на выявление галлюцинаций — авторы показывают, что ARA стабильно повышает точность и снижает выдумки, причём работает на разных популярных MLLM без дополнительного обучения.
Более чёткое зрение при том же «мозге»
Проще говоря, эта работа даёт существующим визуально-языковым моделям не новый «мозг», а лучшие «очки». Восстанавливая и усиливая собственный среднеуровневый фокус модели на правильных частях изображения, ARA помогает ей точнее описывать и рассуждать о визуальных деталях. Подход не добавляет внезапно глубоких здравых смыслов или энциклопедических знаний; он решает практическое узкое место: гарантирует, что ответы модели действительно основаны на том, что перед ней. По мере того как такие системы всё чаще используются для чтения документов, анализа реальных сцен или помощи в задачах, критичных с точки зрения безопасности, методы вроде ARA, которые удерживают их рассуждения привязанными к изображению, могут сделать ИИ-инструменты более надёжными и доверительными для обычных пользователей.
Цитирование: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Ключевые слова: мультимодальный ИИ, визуальные вопросы и ответы, механизмы внимания, снижение галлюцинаций, визуально-языковые модели