Clear Sky Science · tr
Ara-katman yönlendirmesiyle çok modlu büyük dil modellerinde dikkat yeniden hizalaması
Neden daha akıllı görüntü okuyucuları önemlidir
Bugünün yapay zeka sistemlerine bir resimle ilgili sorular sorduğumuzda—örneğin “Kurdele hangi renkte?” veya “Bu yol işareti ne diyor?”—resme dikkatle bakmalarını bekleriz. Gerçekte, görme ve dili birleştiren birçok çok modlu AI modeli, gördüklerinden çok metinden “bildiklerine” daha fazla dayanma eğilimindedir. Bu durum, olmayan nesneleri güvenle tarif etmelerine veya küçük metin gibi ince ayrıntıları yanlış okumalarına yol açabilir. Bu makale, bu tür modelleri baştan eğitmeden görüntüye doğru nazikçe yönlendirmeye yarayan bir yöntem sunar; böylece doğru görsel ayrıntılara dikkat etmeleri sağlanır.
Sözler gözlerin gördüklerini bastırdığında
Modern çok modlu büyük dil modelleri (MLLM’ler), güçlü bir metin motorunu bir görsel modülle eşleştirir; bu sayede sahneleri tarif edebilir, grafikler veya belgelerle ilgili soruları yanıtlayabilir ve dünya bilgisini bir görüntüdeki bilgilerle birleştirebilir. Buna karşın bu modeller “halüsinasyon”lara yatkındır: sadece bir kedi olan bir resimde köpek var diyebilir veya renk, sayı ya da nesnelerin konumunu yanlış tahmin edebilirler. Önceki çalışmalar bu hataların, modelin dil kısmının muhakemede baskın olmasından ve önündeki belirli piksel yerine okuduklarından öğrendiği tanıdık kalıplara dayanmasından kaynaklandığını öne sürmüştür.
Modelin ortasında gizli odak
Yazarlar, modelin bir cevabı oluştururken dikkatin gerçekte nereye gittiğini katman katman incelemek için modellere bakıyor. Şaşırtıcı şekilde, modelin genellikle görüntüye nerede bakacağını bildiğini—özellikle ara katmanlarında—görüyorlar. Örneğin, kurdelenin beyaz değil kırmızı olduğunu yanlış ifade etse bile, içsel dikkat haritaları hâlâ gerçek kurdele bölgesine keskin şekilde odaklanmış olabilir. Ancak bilgi daha derin katmanlara aktıkça bu görsel odak bulanıklaşır ve zamanla dil alışkanlıkları ile genel sahne beklentileri tarafından gölgelenir. Sorun bu durumda görme yetersizliği değil, yol boyunca ayrıntıların gözden kaybolmasıdır.
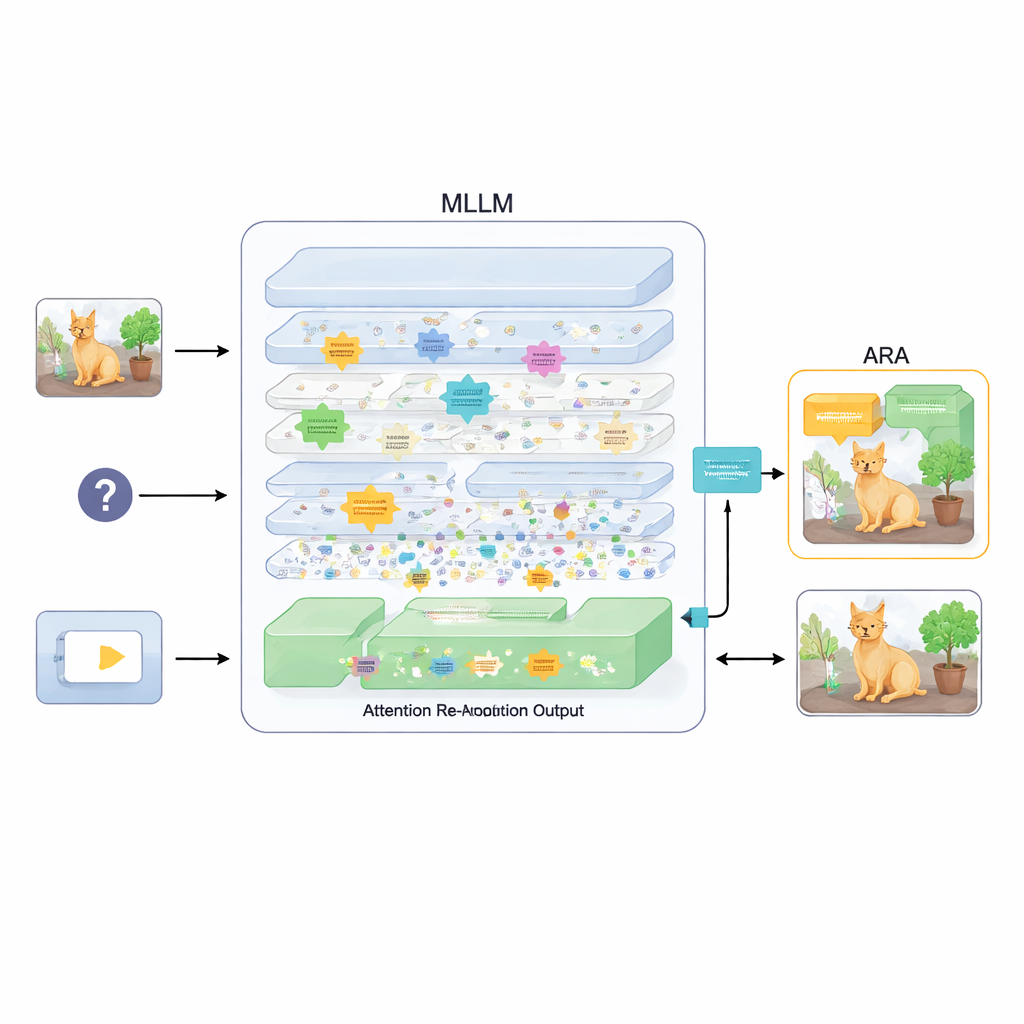
Dikkati yeniden hizalayan bir eklenti
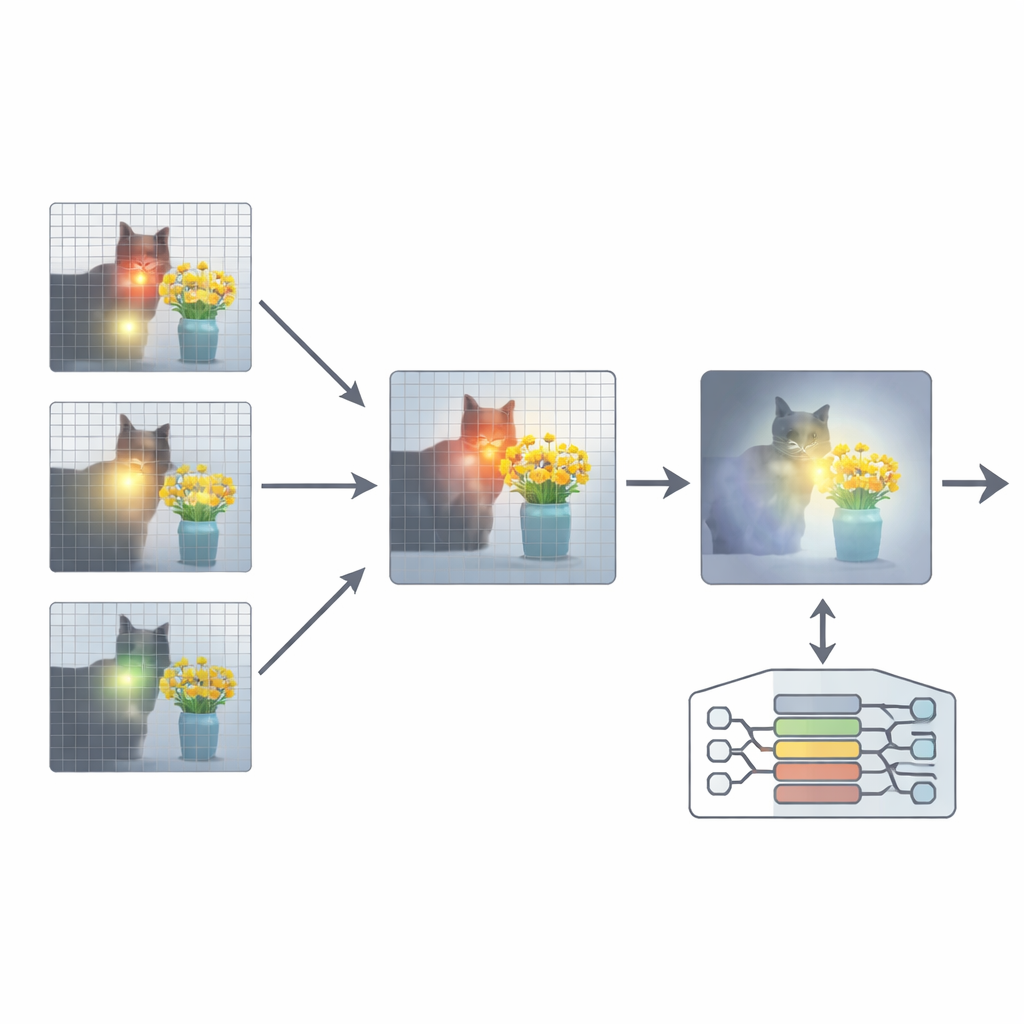
Bunu düzeltmek için makale, Dikkat Yeniden-Hizalaması (ARA) adlı bir eklenti öneriyor. Modelin parametrelerini değiştirmek veya yeniden eğitmek yerine, ARA modelin kendi ara katman dikkat haritalarına erişir. Öncelikle, soru ile ilişkilendirilen bölgeler üzerinde güvenilir şekilde yoğunlaşan—sadece görsel olarak en çarpıcı olana değil—“görüntü-odaklı” başları tanımlar. Ardından her katmanı ne kadar keskin ve emin odaklandığına göre puanlar ve her soru için en iyi birkaç katmanı seçer. Seçilen bu katmanlardan ARA, modelin gerçekten önemli görsel kanıtın nerede olduğuna inandığını gösteren tek, temiz bir dikkat haritası oluşturmak için bunları birleştirir.
Modelin sadece önemli olanı görmesine izin vermek
ARA daha sonra bu birleştirilmiş dikkati görüntü üzerinde basit bir maske haline getirir: modelin güçlü şekilde önem verdiği alanlar görünür kalırken daha az ilgili bölümler karartılır veya engellenir. Bu maskeli görüntü, cevap üretimi sırasında modele geri verilir ve modelin yanıtını vurgulanan bölgelere dayandırması nazikçe zorlanır. Maskeleme uyarlanabilirdir; böylece küçük bir işaret veya belgedeki bir kelime gibi hassas yerel ayrıntıları ve gerektiğinde daha geniş bağlamı yakalar. Görsellerdeki metinleri ve belgeleri okuma, genel soru yanıtlama ve halüsinasyonları açığa çıkarmaya yönelik özel testler gibi çeşitli ölçütlerde dikkatle yapılan deneyler aracılığıyla, yazarlar ARA’nın doğruluğu tutarlı biçimde artırdığını ve uydurma içeriği azalttığını, ayrıca ek eğitim gerektirmeden farklı popüler MLLM’lerde çalıştığını gösterirler.
Daha keskin görüş, aynı zihin
Gündelik ifadeyle, bu çalışma mevcut görüntü–dil modellerine yeni bir beyin yerine daha iyi bir gözlük sağlar. Modelin bir görüntünün doğru kısımlarına yönelik orta düzey odaklanmasını kurtarıp güçlendirerek, ARA görsel ayrıntıları daha sadık bir şekilde tarif edip onların üzerinde akıl yürütebilmesine yardımcı olur. Yaklaşım sihirli şekilde daha derin bir sağduyu veya ansiklopedik bilgi vermez; bunun yerine pratik bir darboğazı ele alır: modelin yanıtlarını gerçekten önündeki görsele dayandırmasını sağlamak. Bu sistemler belgeleri okuma, gerçek dünya sahnelerini analiz etme veya güvenlikle kritik kararlarda yardım etme gibi ortamlarda giderek daha fazla kullanıldıkça, anlatılarını görüntüye bağlayan ARA gibi yöntemler AI araçlarını günlük kullanıcılar için daha güvenilir ve güvenli kılabilir.
Atıf: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Anahtar kelimeler: çok modlu AI, görsel soru yanıtlama, dikkat mekanizmaları, halüsinasyon azaltma, görsel dil modelleri