Clear Sky Science · ar
إعادة توجيه الانتباه في نماذج اللغة الكبيرة متعددة الوسائط عبر إرشاد الطبقات الوسيطة
لماذا يهم أن تكون قارئات الصور أذكى
عندما نسأل أنظمة الذكاء الاصطناعي الحالية أسئلة حول الصور — مثل «ما لون الشريط؟» أو «ماذا يقول لافتة الشارع هذه؟» — نتوقع أن تنظر بدقة إلى الصورة. في الواقع، كثير من النماذج متعددة الوسائط، التي تجمع بين الرؤية واللغة، تميل أكثر إلى ما «تعرفه» من النصوص بدلاً من ما تراه فعلاً. قد يؤدي ذلك إلى وصف واثق لأشياء غير موجودة أو قراءة خاطئة لتفاصيل دقيقة مثل نص صغير. تطرح هذه الورقة طريقة لإعادة توجيه هذه النماذج برفق نحو الصورة نفسها، لمساعدتها على التركيز على التفاصيل البصرية الصحيحة دون إعادة تدريبها من الصفر.
عندما تُغرق الكلمات ما تراه العينان
ترابط نماذج اللغة الكبيرة متعددة الوسائط الحديثة محرك نص قوي مع وحدة رؤية، مما يتيح لها وصف المشاهد، والإجابة عن أسئلة حول الرسوم البيانية أو الوثائق، ودمج المعرفة العامة مع ما في الصورة. ومع ذلك، هذه النماذج عرضة لـ«الهلوسات»: فقد تدّعي وجود كلب في صورة تحتوي على قطة فقط، أو تخمن لوناً أو رقماً أو موقعاً خاطئاً للأشياء. أشارت دراسات سابقة إلى أن هذه الأخطاء تنشأ لأن جزء اللغة في النموذج يهيمن على الاستدلال، معتمداً على أنماط مألوفة من قراءاته بدلاً من وحدات البكسل المحددة أمامه.
تركيز خفي في منتصف النموذج
يفحص المؤلفون هذه النماذج طبقة بطبقة ليعرفوا إلى أين يذهب الانتباه فعلاً أثناء تكوين الإجابة. بشكل مفاجئ، يجدون أن النموذج غالباً ما يعرف أين ينظر في الصورة — خصوصاً في طبقاته الوسيطة. على سبيل المثال، حتى عندما يصرح خطأً بأن الشريط أبيض بدلًا من أحمر، يمكن أن يكون انتباهه الداخلي مركّزاً بدقة على منطقة الشريط الفعلية. مع تدفق المعلومات إلى الطبقات الأعمق، يصبح هذا التركيز البصري مشوشاً ويتلاشى تدريجياً لصالح عادات اللغة وتوقعات المشهد العامة. المشكلة إذن ليست العمى، بل فقدان الرؤية للتفاصيل على طول المسار.
مُلحق يعيد ضبط الانتباه
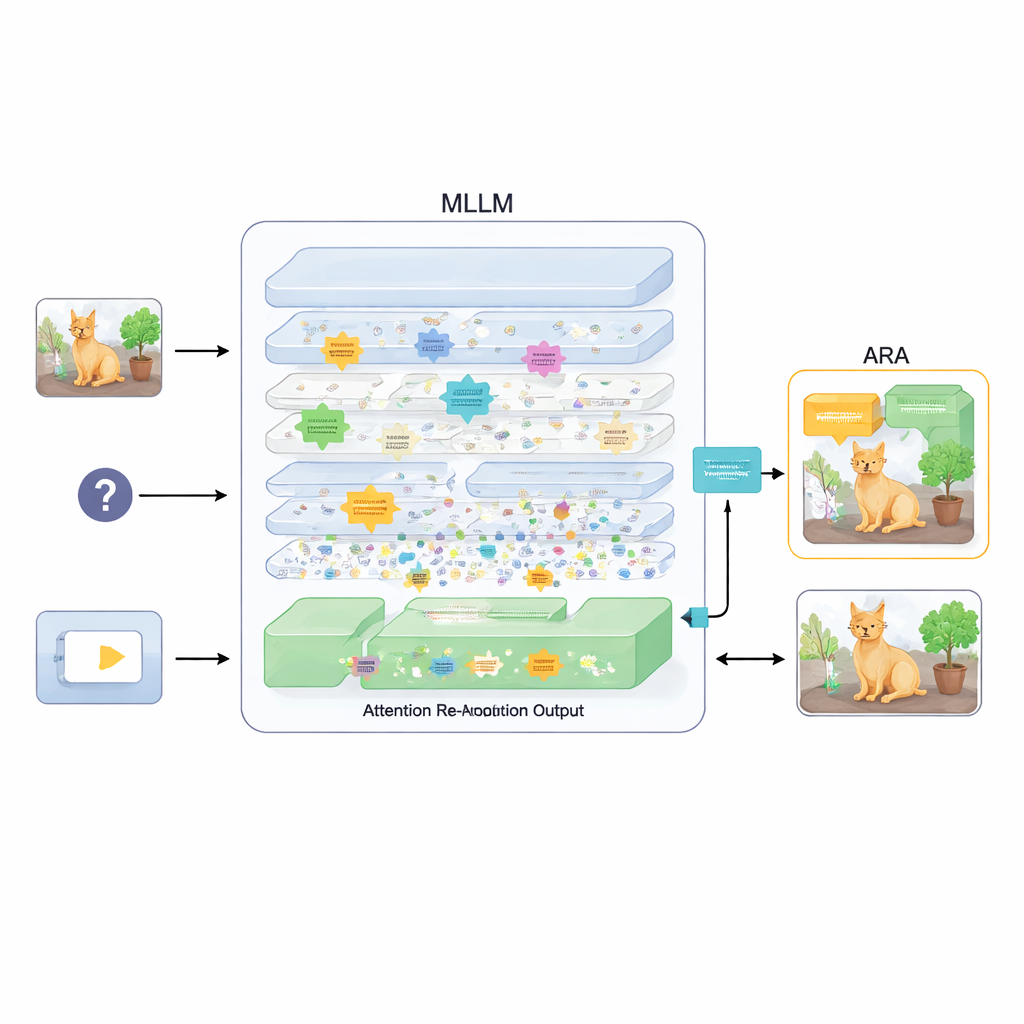
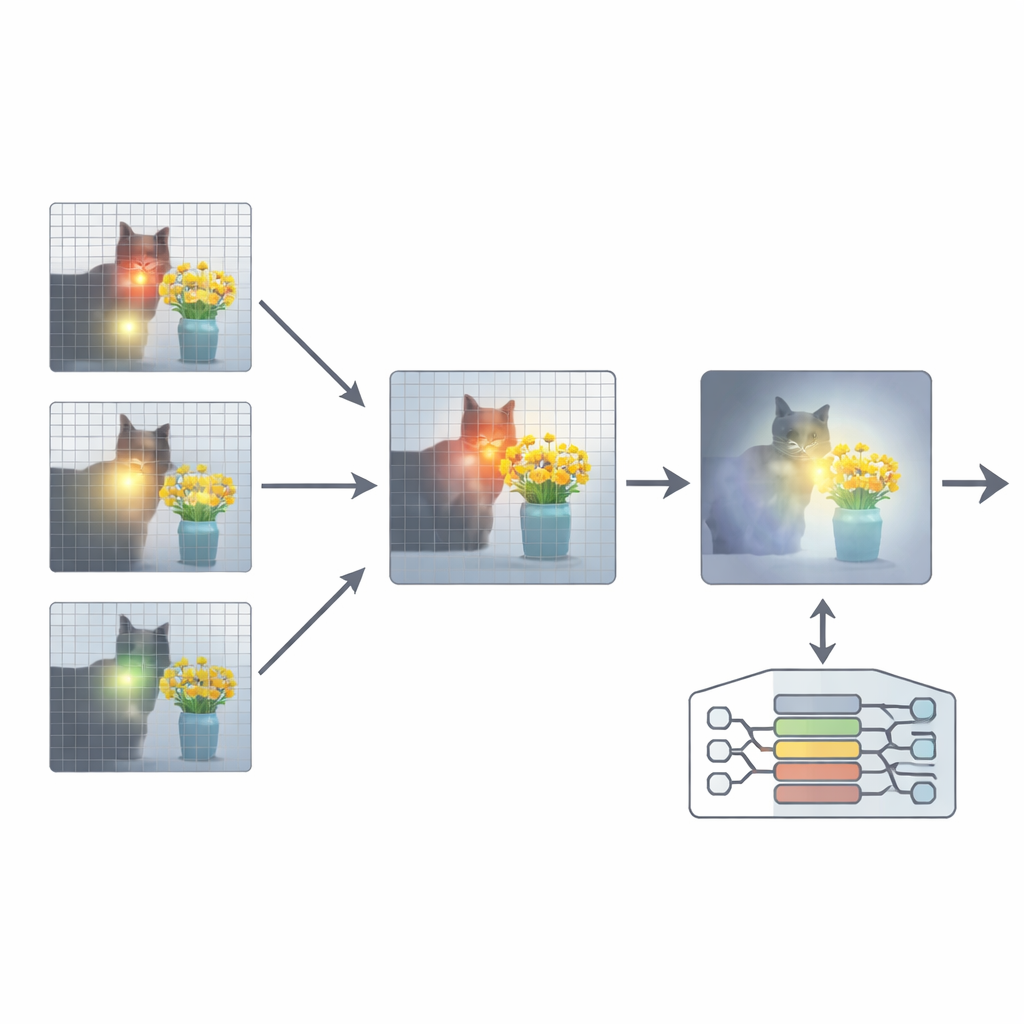
لإصلاح ذلك، تقترح الورقة ملحقاً يُسمى إعادة توجيه الانتباه (ARA). بدلاً من تغيير معلمات النموذج أو إعادة تدريبه، يستغل ARA خرائط الانتباه الخاصة بالنموذج في الطبقات الوسيطة. أولاً يحدد تلك الرؤوس «المتمحورة حول الصورة» — أجزاء من النموذج تركز بشكل موثوق على مناطق مرتبطة بسؤال المستخدم، وليس فقط على ما هو بصرياً بارز. ثم يقوّم كل طبقة استناداً إلى مدى حدة وثقة تركيزها، ويختار أفضل بضع طبقات لكل سؤال. من هذه الطبقات المختارة، يدمج ARA خرائط الانتباه في صورة واحدة واضحة لمكان وجود الدليل البصري الذي يعتقده النموذج فعلاً.
إتاحة الرؤية للنموذج لما يهم فقط
يقوم ARA بعد ذلك بتحويل هذا الانتباه المدمج إلى قناع بسيط على الصورة: تظل المناطق التي يهتم بها النموذج بقوة مرئية، بينما تُخفت أو تُحجب المناطق الأقل صلة. تُعاد هذه الصورة المقنعة إلى النموذج أثناء توليد الإجابة، مما يجبره بلطف على تأصيل رده في المناطق المظللة. القناع تكيّفي، فيلتقط كلاً من التفاصيل المحلية الدقيقة (مثل لافتة صغيرة أو كلمة في مستند) والسياق الأوسع عند الحاجة. ومن خلال تجارب دقيقة على عدة معايير — تتراوح بين قراءة النصوص في الصور والوثائق إلى الإجابة العامة عن الأسئلة واختبارات مصممة خصيصاً لكشف الهلوسات — يظهر المؤلفون أن ARA يحسّن الدقة بانتظام ويقلل المحتوى المختلق، ويعمل عبر نماذج MLLM شعبية مختلفة دون تدريب إضافي.
رؤية أوضح، نفس العقل
بمصطلحات يومية، تمنح هذه الدراسة نماذج الصورة-اللغة الحالية زوجاً أفضل من النظارات بدلًا من دماغ جديد. من خلال استعادة وتعزيز تركيز النموذج الوسيط على أجزاء الصورة الصحيحة، يساعد ARA النموذج على وصف والتفكير في التفاصيل البصرية بشكل أكثر أمينة. لا يمنح النهج معرفة أعمق منطقية أو موسوعية بشكل سحري؛ بل يعالج عنق زجاجة عملي: التأكد من أن إجابات النموذج تستند فعلاً إلى ما أمامه. ومع تزايد استخدام هذه الأنظمة في سياقات مثل قراءة الوثائق، وتحليل المشاهد الواقعية، أو المساعدة في قرارات ذات أثر على السلامة، يمكن لطرق مثل ARA التي تُبقي سردها مربوطاً بالصورة أن تجعل أدوات الذكاء الاصطناعي أكثر موثوقية وجديرة بالاعتماد للمستخدمين اليوميين.
الاستشهاد: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
الكلمات المفتاحية: الذكاء الاصطناعي متعدد الوسائط, الإجابة المرئية عن الأسئلة, آليات الانتباه, تقليل الهلوسة, نماذج الرؤية واللغة