Clear Sky Science · en
Attention re-alignment in multimodal large language models via intermediate-layer guidance
Why smarter image readers matter
When we ask today’s AI systems questions about pictures—such as “What color is the ribbon?” or “What is this street sign saying?”—we expect them to look carefully at the image. In reality, many multimodal AI models, which combine vision and language, often lean more on what they “know” from text than on what they actually see. This can lead them to confidently describe objects that are not there or misread fine details like small text. This paper introduces a way to gently steer such models back toward the image itself, helping them pay attention to the right visual details without retraining them from scratch.
When words drown out what the eyes see
Modern multimodal large language models (MLLMs) pair a powerful text engine with a vision module, allowing them to describe scenes, answer questions about charts or documents, and combine world knowledge with what is in an image. Yet these models are prone to “hallucinations”: they might claim there is a dog in a picture with only a cat, or guess the wrong color, number, or position of objects. Earlier studies suggested that these errors arise because the language part of the model dominates the reasoning, relying on familiar patterns from its reading rather than the specific pixels in front of it.
Hidden focus in the middle of the model
The authors look inside these models, layer by layer, to see where the attention really goes while the model is forming an answer. Surprisingly, they find that the model often does know where to look in the image—especially in its intermediate layers. For instance, even when it wrongly states that a ribbon is white instead of red, its internal attention can still be sharply focused on the actual ribbon region. As the information flows to deeper layers, however, this visual focus becomes blurred and is gradually overshadowed by language habits and general scene expectations. The problem, then, is less about blindness and more about losing sight of details along the way.
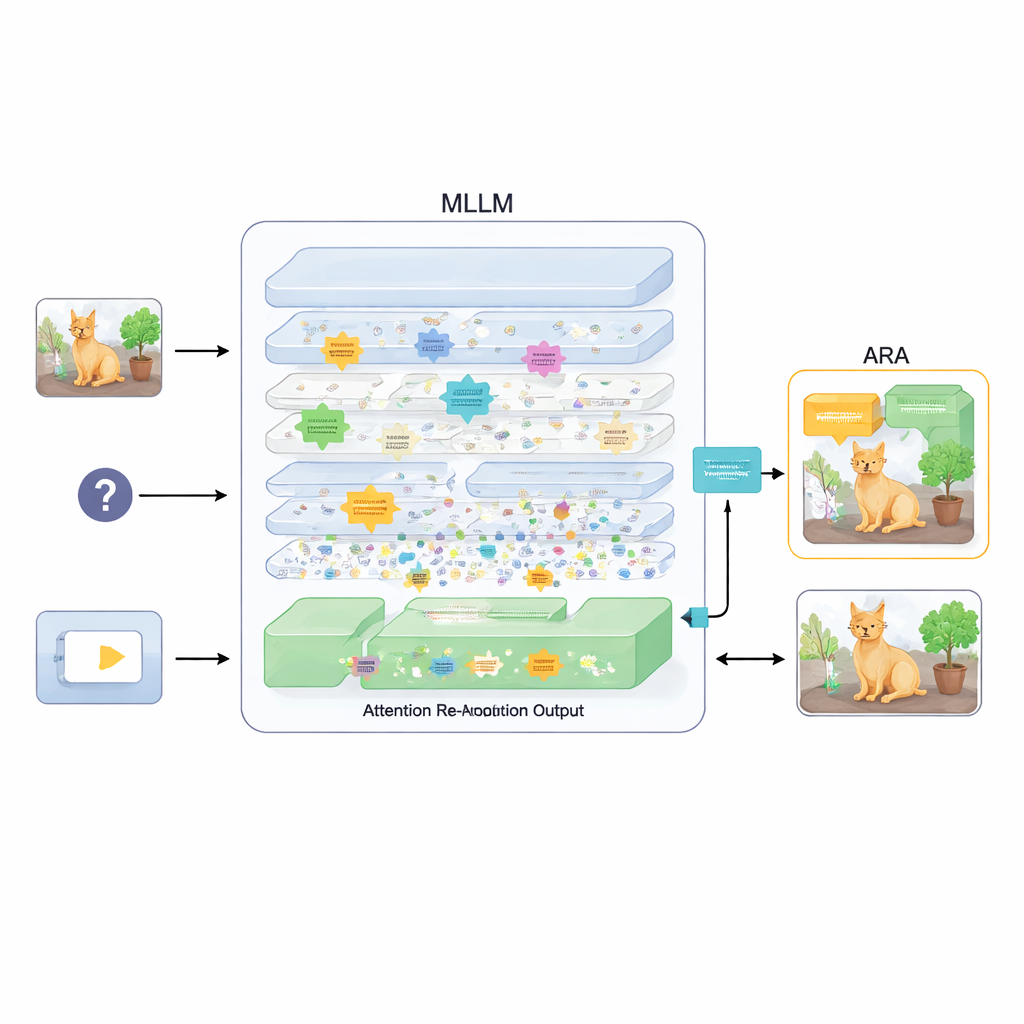
A plug-in that realigns attention
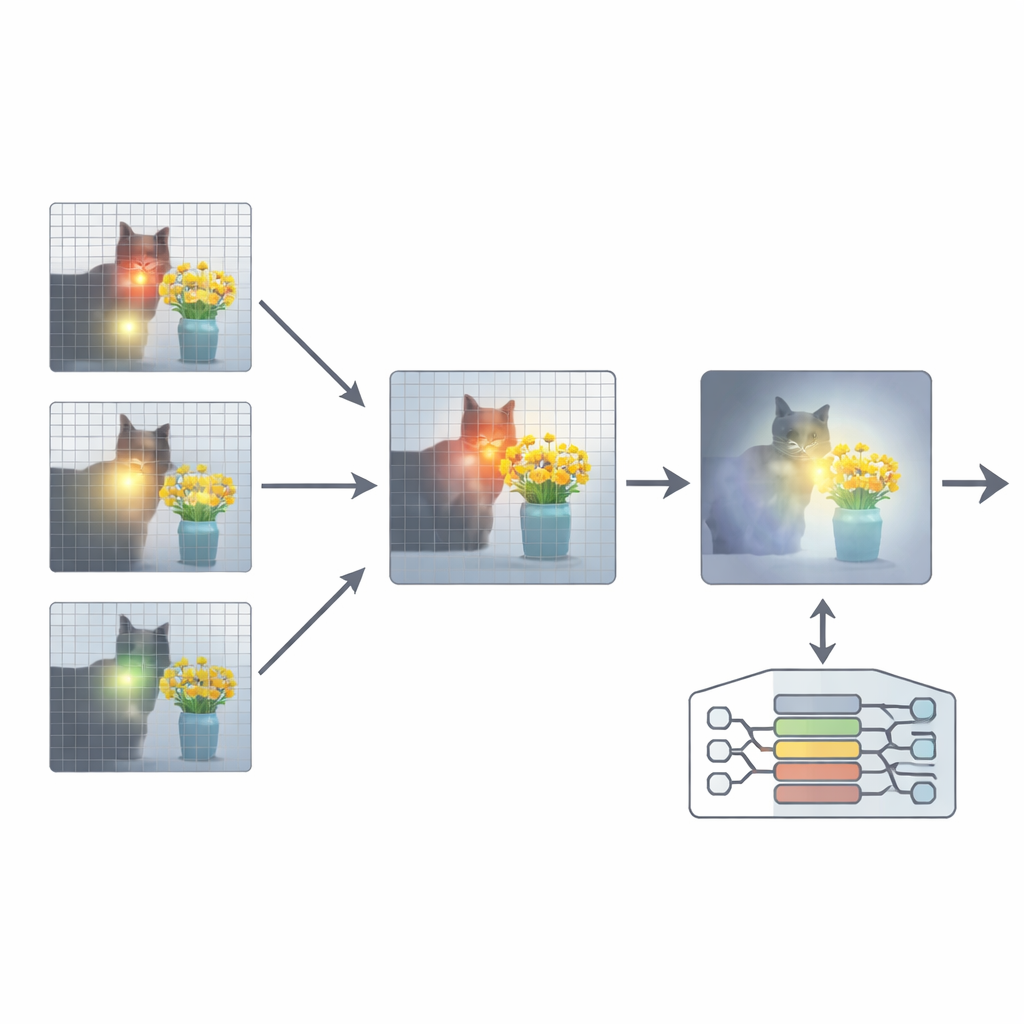
To fix this, the paper proposes an add-on called Attention Re-Alignment (ARA). Rather than changing the model’s parameters or retraining it, ARA taps into the model’s own attention maps in the middle layers. It first identifies those “image-centric” heads—parts of the model that reliably concentrate on regions tied to the user’s question, not just on whatever is most visually striking. It then scores each layer based on how sharply and confidently it focuses, and selects the best few layers for each question. From these chosen layers, ARA fuses their attention maps into a single, clean picture of where the model truly believes the important visual evidence lies.
Letting the model see only what matters
ARA then turns this fused attention into a simple mask over the image: areas the model strongly cares about remain visible, while less relevant regions are dimmed or blocked out. This masked image is fed back into the model during answer generation, gently forcing it to ground its response in the highlighted regions. The masking is adaptive, so it captures both precise local details (such as a small sign or a word in a document) and the broader context when needed. Through careful experiments on several benchmarks—ranging from reading text in images and documents to general question answering and tests specifically designed to expose hallucinations—the authors show that ARA consistently improves accuracy and reduces made-up content, and it works across different popular MLLMs without extra training.
Sharper vision, same brain
In everyday terms, this work gives existing image–language models a better pair of glasses rather than a new brain. By recovering and reinforcing the model’s own mid-level focus on the right parts of an image, ARA helps it describe and reason about visual details more faithfully. The approach does not magically grant deeper common-sense or encyclopedic knowledge; instead, it tackles a practical bottleneck: making sure the model truly bases its answers on what is in front of it. As these systems are increasingly used in settings like reading documents, analyzing real-world scenes, or assisting with safety-critical decisions, methods like ARA that keep their stories anchored to the picture can make AI tools more trustworthy and reliable for everyday users.
Citation: Chen, Y., Wang, P., Qin, G. et al. Attention re-alignment in multimodal large language models via intermediate-layer guidance. Sci Rep 16, 14576 (2026). https://doi.org/10.1038/s41598-026-44935-1
Keywords: multimodal AI, visual question answering, attention mechanisms, hallucination reduction, vision language models