Clear Sky Science · zh
基于Mamba的调制融合模型用于视频时刻检索
为何在视频中定位正确时刻很重要
从烹饪教程到体育回放,我们常常希望能直接跳到长视频中与简短描述相匹配的精确时刻,例如“她切洋葱的那一刻”或“最后的进球”。手动查找既慢又费力。本文提出了一种新方法,帮助计算机基于自然语言快速定位视频中合适的时间段,即便视频很长且描述仅暗示了部分发生的内容。
在长视频中搜索的挑战
视频时刻检索的任务是从未剪辑的长视频中找到与给定句子最相关的时间片段。早期系统先将视频切成许多候选片段,然后再将它们与文本进行排序,这使得性能高度依赖于初始候选的质量。较新的“端到端”模型避免了这一步,直接用基于注意力的网络预测起止时间。这些新模型能够很好地对齐词与帧,但在需要理解事件顺序与流程的长视频(如多步食谱或复杂的体育战术)上仍然吃力。
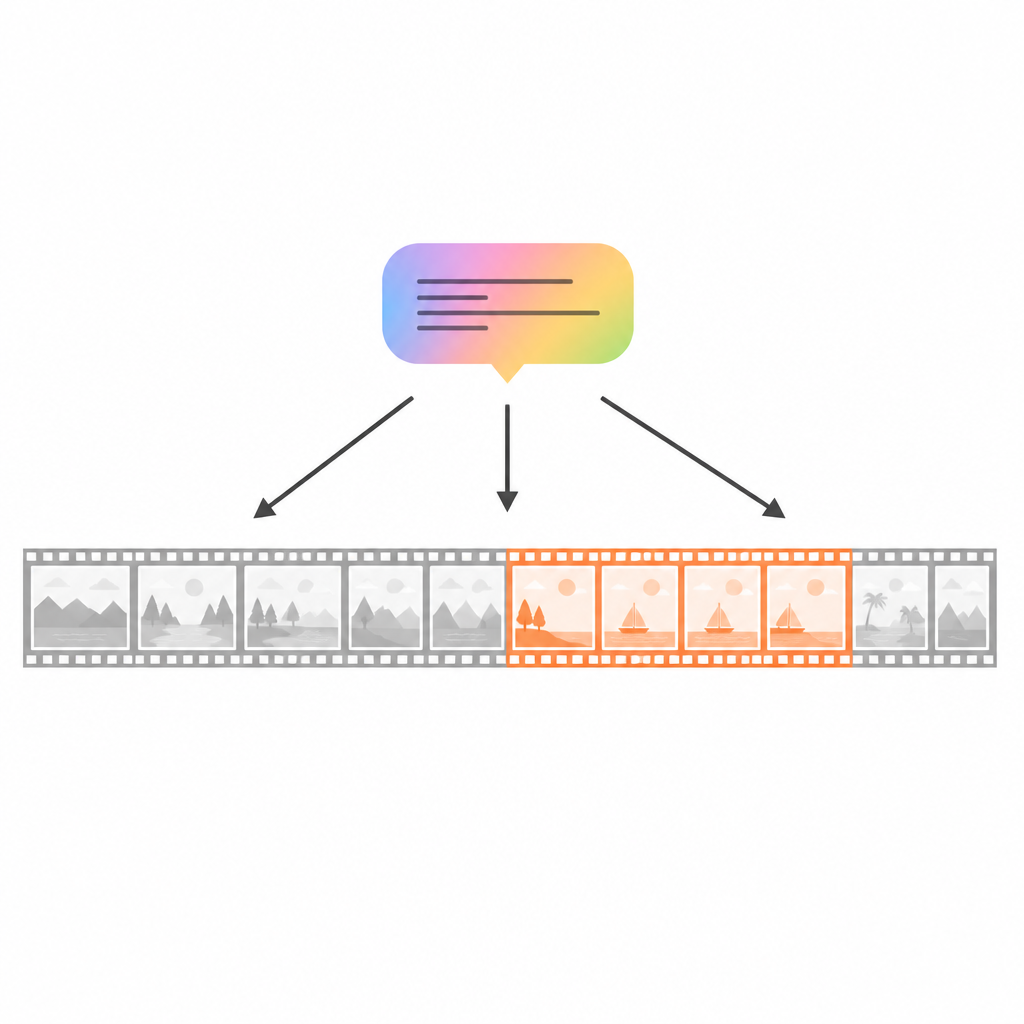
为何常规注意力不够
基于注意力的模型把视频视为帧的集合,允许任意帧彼此连接。尽管这对于发现视觉匹配非常有效,但可能忽略动作如何随时间展开的整体脉络。例如,查询“拿出榨汁机后,他挤第一个橙子半个”只提到首尾两步,而实际的真实时刻会跨越其间的若干小动作。标准模型可能会固定在最明显的帧上,忽视那些隐藏的中间步骤,导致预测不完整或位置偏移。一些近期工作尝试缩短视频或将帧分组为更高层次的事件,但这可能破坏自然的故事线,仍然让模型对整段序列的理解支离破碎。
一种随时间融合文本与视频的新方法
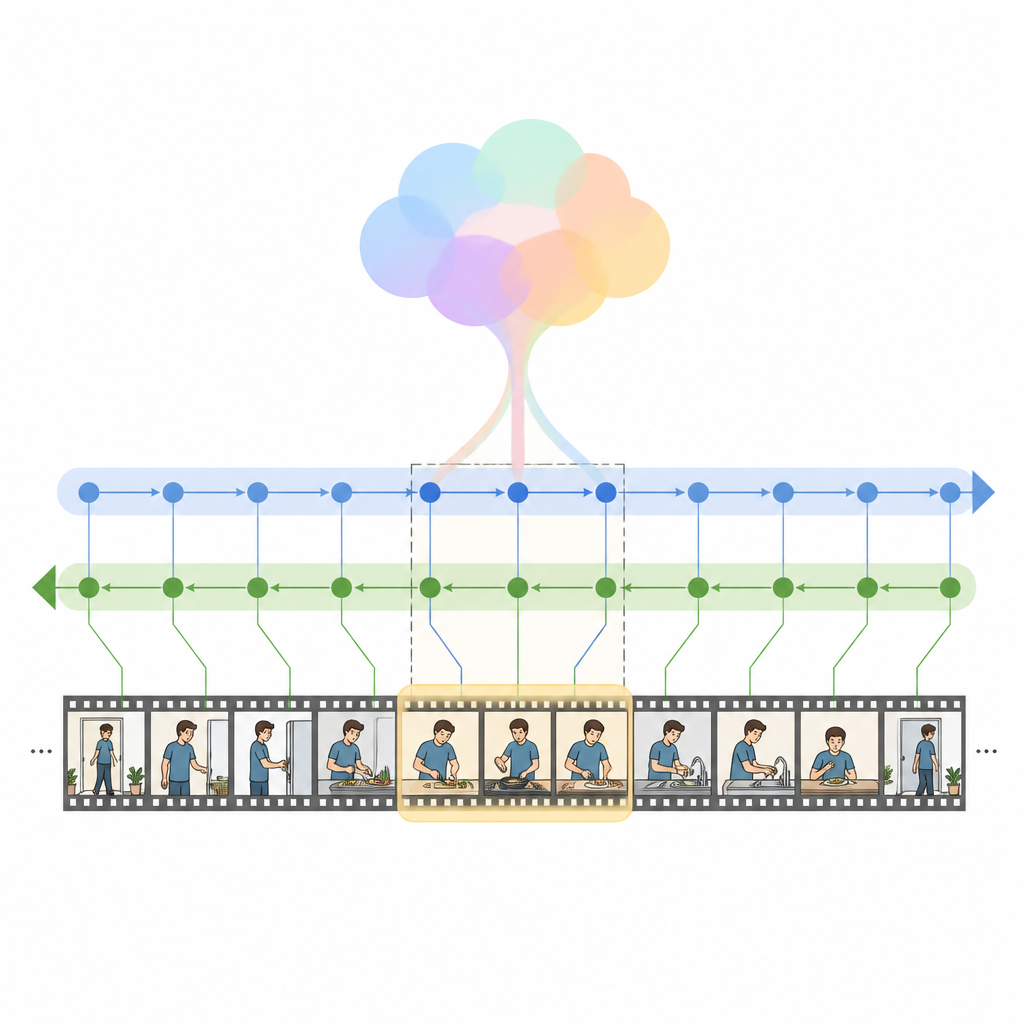
作者提出了HM Net,一种混合型Mamba网络,它结合了注意力机制和一种新型序列模型——状态空间模型的优势。其核心是混合调制双向Mamba模块,首先使用交叉注意力将每个视频帧与相关词对齐,然后将这种融合信息传入一个双向时间引擎,同时从前向和后向读取视频。查询的全局摘要在此过程中发挥引导作用,温和地将模型引向整体意图,而不仅仅是孤立的词语。对于较短片段,额外的位置性信号帮助系统保持顺序信息,而对于长片段,模型更多依赖其学到的时间结构感知。
逐步理解复杂时刻
HM Net以两阶段进行融合。第一阶段,视频特征通过文本提示被增强,使得每一帧“知道”句子中哪些部分最重要。第二阶段,视频与文本以对称方式反复互相精炼,创建出既含有细节又兼顾长程上下文的共享表示。最终的解码模块预测时间线上哪些片段最匹配查询。模型不仅被训练来定位正确的时间段,还要将匹配的视频-文本对与不匹配的对区分开,并从片段重建更高层次的描述,这有助于强化语言与视觉事件之间的联系。
来自烹饪视频与日常短片的证据
团队在两个主要基准上测试了HM Net:TACoS,包含时长较长、细节丰富的烹饪视频,以及QVHighlights,一组较短的真实世界短片并以高光式查询为主。在TACoS上,视频较长且动作展开缓慢,新模型在准确性和排序质量上明显优于先前的领先方法。它在跨越分钟级而非秒级的非常长或复杂查询上尤其强劲。在QVHighlights上,由于许多片段较短,提升较小但仍然稳定,显示混合设计即便在时间推理要求较低时也有帮助。消融研究确认了每个组成部分——双向Mamba核心、交叉注意力与全局上下文池化——均对最终性能有实质贡献。
这对日常视频搜索意味着什么
简而言之,这项研究表明,将精确的词-帧匹配与强大的故事流感知相结合,可以帮助计算机更好地理解和检索长视频。HM Net不仅能锁定看起来合适的帧,还能追踪动作如何随着时间积累与收尾。这使其能够找到用户真正关心的更长的多步事件,例如教程中的完整演示或视频博客中的关键片段,使未来的视频平台能更好地响应自然语言查询。
引用: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
关键词: 视频时刻检索, 跨模态学习, 时间建模, 状态空间模型, 视频理解