Clear Sky Science · ja
ビデオモーメント検索のためのMambaベース変調融合モデル
ビデオ内の適切な瞬間を見つけることが重要な理由
料理チュートリアルからスポーツのリプレイまで、私たちはしばしば「玉ねぎを刻むとき」や「最後のゴール」のような短い記述に対応する長いビデオの正確な瞬間にすぐジャンプしたいと考えます。手作業では遅く疲れる作業です。本稿は、ビデオが長く記述が出来事の一部しか示唆していない場合でも、自然言語に基づいてコンピュータがビデオ内の該当する時間区間を素早く特定できる新しい手法を提示します。
長いビデオ内検索の難しさ
ビデオモーメント検索は、与えられた文に一致する未編集(untrimmed)ビデオ中の最も関連する時間区間を見つけるタスクです。従来のシステムはまずビデオを多数の候補クリップに切り分け、それらをテキストと比較してランク付けしていました。このため精度は初期候補の質に大きく依存しました。最近の「エンドツーエンド」モデルはこの二段階プロセスを回避し、注意機構ベースのネットワークで直接開始・終了時刻を予測します。これらのモデルは単語とフレームをよく整合させますが、複数ステップのレシピや複雑なスポーツプレイのように出来事の順序や流れを理解することが重要な長尺ビデオでは依然として苦戦します。
通常の注意機構が不足する理由
注意機構ベースのモデルはビデオをフレームの集合(bag of frames)として扱い、任意のフレーム同士が接続可能になります。視覚的な一致を見つけるには強力ですが、出来事が時間的にどのように展開するかという大局を見落とすことがあります。例えば「ジューサーを取り出した後、彼は最初のオレンジ半分を絞る」のようなクエリは最初と最後の手順しか明示していませんが、真の対象区間はそれらの間のいくつかの小さな行動をまたいでいます。標準的なモデルはもっとも明白なフレームに引き寄せられ、隠れた手順を無視してしまい、不完全またはずれた予測につながることがあります。最近の研究の中にはビデオを短縮したりフレームを上位のイベントにまとめたりする試みもありますが、これでは自然なストーリーラインが壊れることがあり、シーケンス全体の視野が断片的なままになることがあります。
時間軸でテキストとビデオを融合する新しい方法
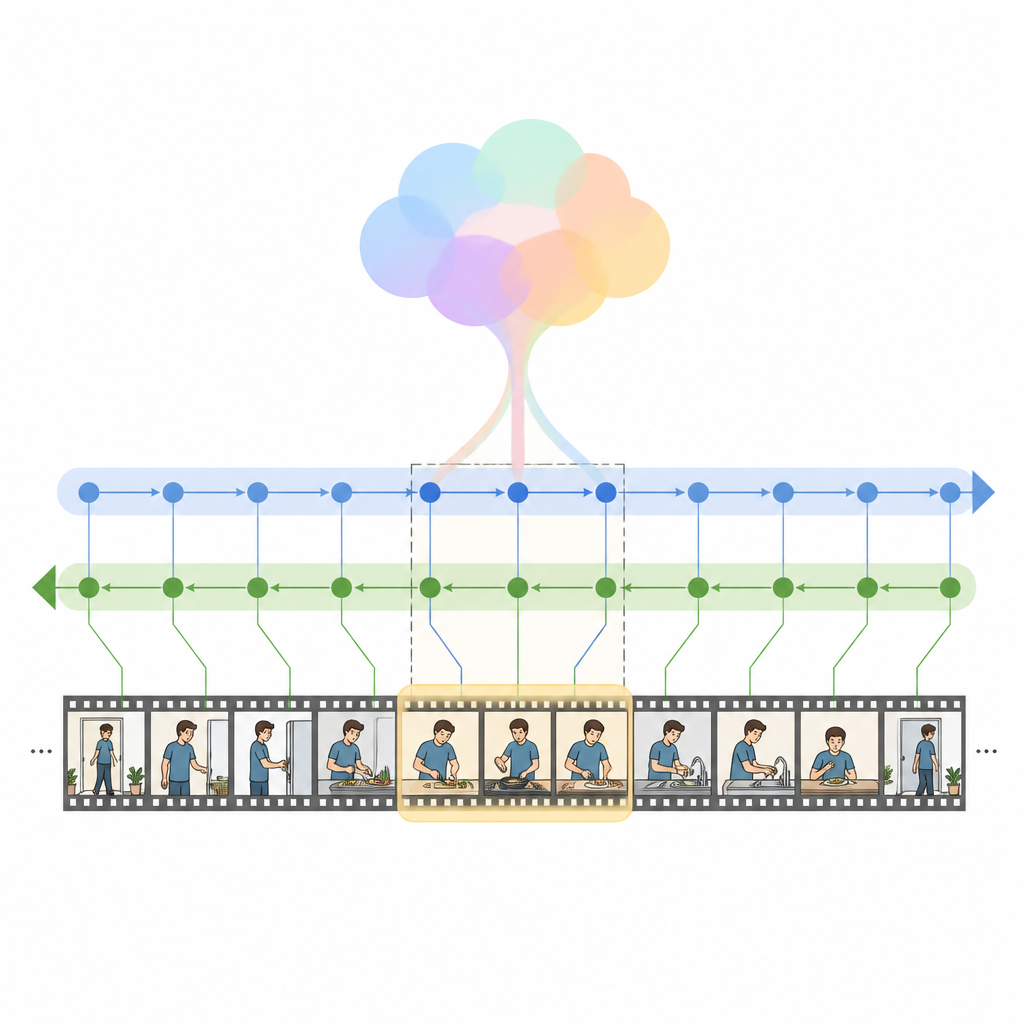
著者らはHM Net(ハイブリッドMambaネットワーク)を導入します。これは注意機構の強みと、状態空間モデルという新しいクラスの系列モデルを組み合わせたものです。中心となるのはHybrid Modulated Bi Mambaブロックで、まずクロスアテンションを使って各ビデオフレームを関連する単語に対して整合させ、次にこの融合情報を前後両方向に読み取る双方向の時間的エンジンに通します。クエリのグローバルサマリーがこのプロセスを導き、単語の断片にとらわれず全体の意図へと穏やかに誘導します。短いクリップでは追加の位置情報が順序の把握を助け、長尺のクリップではモデルが学習した時間構造の感覚により依存します。
複雑な瞬間の段階的理解
HM Netは融合を二段階で行います。第一段階では、ビデオ特徴がテキストからの手がかりで強化され、各フレームが文のどの部分が重要かを「認識」します。第二段階では、ビデオとテキストが対称的に何度も相互に洗練し合い、詳細な局所情報と長距離の文脈を同時に捉える共有表現を作り出します。最後のデコーディングモジュールが、タイムライン上のどの区間がクエリに最も合致するかを予測します。モデルは正しい区間を見つけるだけでなく、マッチするビデオ・テキスト対と不一致の対を区別したり、区間から上位の記述を再構成したりするように学習されており、言語と視覚イベントの結びつきを強めます。
料理動画と日常クリップからの証拠
研究チームはHM Netを二つの主要ベンチマークで評価しました。TACoSは長く詳細な料理動画を含み、QVHighlightsはハイライト風のクエリを含む短めの実世界クリップを集めたものです。TACoSでは、ビデオが長く動作がゆっくり展開するため、新モデルは従来の最先端手法を精度とランキング品質の両面で明確に上回りました。特に秒ではなく分単位にまたがる非常に長い・複雑なクエリに強みを発揮します。QVHighlightsではクリップが短めの例が多いため利得は小さめですが一貫しており、ハイブリッド設計が時間的推論の要求がそれほど高くない場合でも寄与することを示しています。アブレーション研究は、双方向Mambaコア、クロスアテンション、グローバルコンテキストプーリングそれぞれが最終性能に意義ある寄与をしていることを確認しています。
日常のビデオ検索への意味
簡単に言えば、本研究は精密な単語−フレームの照合を物語の流れへの強い感覚と組み合わせることで、コンピュータが長尺ビデオをより良く理解し検索できることを示しています。HM Netは見た目が合うフレームにとどまらず、行動が時間を通じてどのように積み上がり収束していくかを追跡します。これにより、チュートリアルの完全なデモンストレーションやブログ映像の重要な一連など、人が実際に気にする長い複数ステップの出来事を見つけられるようになり、将来のビデオプラットフォームが自然言語クエリに対してより応答的になることが期待されます。
引用: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
キーワード: ビデオモーメント検索, クロスモーダル学習, 時間的モデリング, 状態空間モデル, ビデオ理解