Clear Sky Science · sv
Mamba-baserad modulerad fusionsmodell för videomoment-sökning
Varför det är viktigt att hitta rätt ögonblick i video
Från matlagningsvideor till sportrepriser vill vi ofta hoppa direkt till det exakta ögonblicket i en lång video som matchar en kort beskrivning, såsom ”när hon hackar löken” eller ”det sista målet.” Att göra detta manuellt är långsamt och mödosamt. Denna artikel presenterar en ny metod som hjälper datorer att snabbt lokalisera rätt tidsintervall i en video baserat på naturligt språk, även när videon är lång och beskrivningen bara antyder en del av vad som händer.
Utmaningen med att söka i långa videor
Video Moment Retrieval är uppgiften att hitta det mest relevanta tidssegmentet i en oklippt video som matchar en given mening. Tidigare system delade först upp videon i många kandidatklipp och försökte sedan rangordna dem mot texten, vilket gjorde att noggrannheten i hög grad berodde på kvaliteten i dessa initiala gissningar. Nyare ”end-to-end”-modeller undviker denna tvåstegsprocess och predicerar direkt start- och sluttider med hjälp av uppmärksamhetsbaserade nätverk. Dessa nyare modeller alignar ord och bildrutor väl, men har fortfarande svårt med långa videor där förståelsen av ordning och händelseförlopp är avgörande, såsom ett flerstegsrecept eller en komplicerad sportsekvens.
Varför vanlig attention inte räcker
Uppmärksamhetsbaserade modeller behandlar en video som en säck med bildrutor och tillåter att vilken ruta som helst kan kopplas till vilken annan som helst. Även om detta är kraftfullt för att hitta visuella matchningar kan det missa helheten i hur handlingar utvecklas över tid. Till exempel nämner en fråga som ”Efter att ha tagit fram juicen, pressar han den första apelsinhalvan” endast första och sista stegen, men det verkliga ögonblicket spänner över flera mindre handlingar däremellan. Standardmodeller kan haka fast vid de mest uppenbara bildrutorna och ignorera de dolda stegen, vilket leder till ofullständiga eller förskjutna prediktioner. En del nyare arbete försöker förkorta videor eller gruppera rutor till högre nivå-händelser, men det kan bryta den naturliga berättelsen och lämnar ändå modellen med en fragmentarisk bild av hela sekvensen.
En ny metod för att fusera text och video över tid
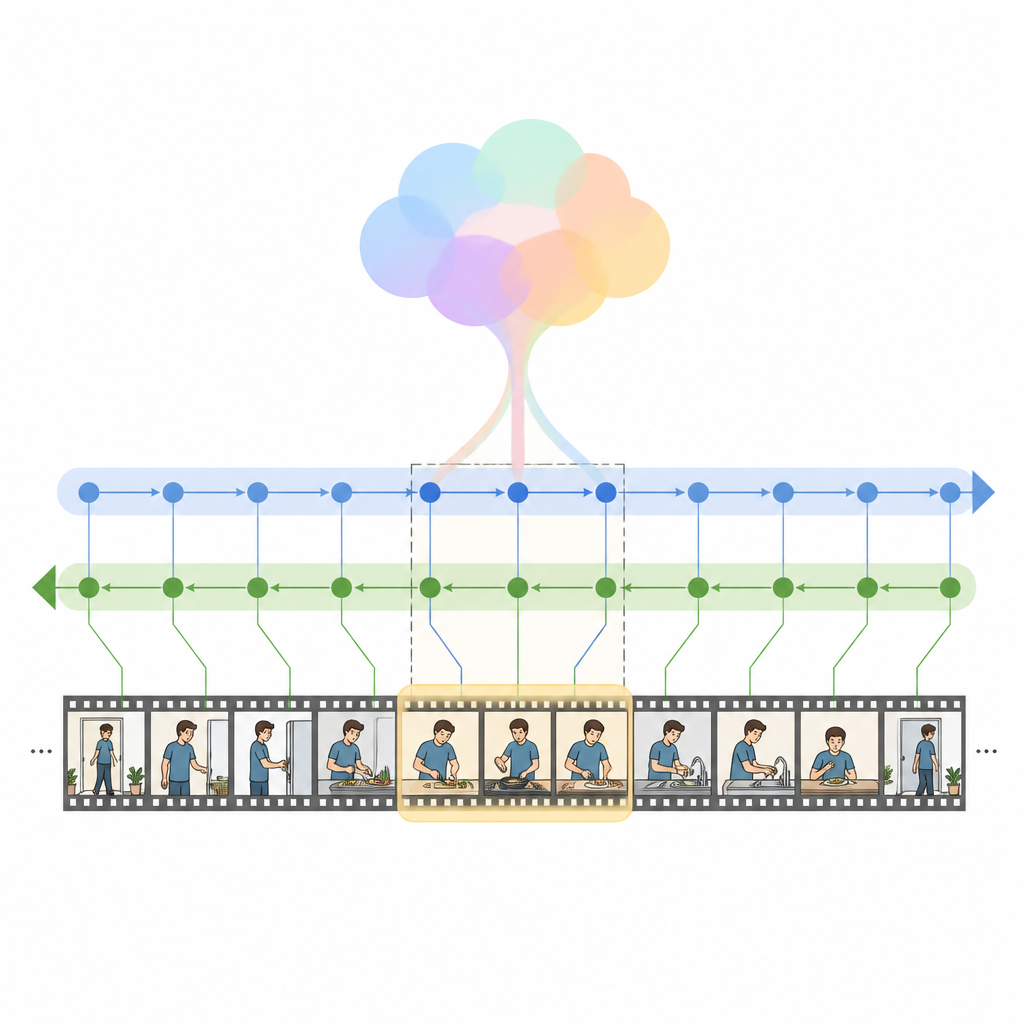
Författarna introducerar HM Net, ett Hybrid Mamba Network som kombinerar styrkorna hos attention med en nyare klass av sekvensmodeller kallade state space-modeller. I sin kärna ligger Hybrid Modulated Bi Mamba-blocket, som först använder korsuppmärksamhet för att aligna varje videoruta med relevanta ord, och sedan skickar denna sammansmälta information genom en bidirektionell temporal motor som läser videon både framåt och bakåt. En global sammanfattning av frågan vägleder denna process och styr modellen mot den övergripande avsikten snarare än bara isolerade ord. För kortare klipp hjälper en extra positionssignal systemet att hålla ordningen, medan modellen för långa klipp i större utsträckning förlitar sig på sin inlärda känsla för temporal struktur.
Stegvis förståelse av komplexa ögonblick
HM Net utför fusion i två steg. I första steget berikas videofunktionerna med signaler från texten så att varje ruta ”vet” vilka delar av meningen som är viktigast. I andra steget förfinar video och text upprepade gånger varandra på ett symmetriskt sätt, vilket skapar en delad representation som fångar både fin detalj och långsiktig kontext samtidigt. En slutlig avkodningsmodul predicerar sedan vilka segment av tidslinjen som bäst matchar frågan. Modellen tränas inte bara för att lokalisera rätt spann, utan också för att skilja matchande video-text-par från icke-matchande och för att återskapa högre nivå-beskrivningar från segment, vilket hjälper till att stärka länken mellan språk och visuella händelser.
Bevis från matlagningsvideos och vardagsklipp
Teamet testar HM Net på två stora benchmarkar: TACoS, som innehåller långa, detaljerade matlagningsvideor, och QVHighlights, en samling kortare, verkliga klipp med highlight-stilfrågor. På TACoS, där videorna är långa och handlingar utvecklas långsamt, överträffar den nya modellen tydligt tidigare ledande metoder både vad gäller noggrannhet och rangordningskvalitet. Den är särskilt stark på mycket långa eller komplexa frågor som sträcker sig över minuter snarare än sekunder. På QVHighlights, där många klipp är kortare, är förbättringarna mindre men fortfarande konsekventa, vilket visar att den hybrida utformningen hjälper även när temporal resonemang är mindre krävande. Ablationsstudier bekräftar att varje beståndsdel—den bidirektionella Mamba-kärnan, korsuppmärksamheten och global kontextpoolning—bidrar meningsfullt till slutprestandan.
Vad detta betyder för vardaglig videosökning
Enkelt uttryckt visar denna forskning att en kombination av exakt ord–ruta-matchning och en stark känsla för berättelsens flöde hjälper datorer att bättre förstå och söka i långa videor. HM Net låser inte bara fast vid de rutor som ser rätt ut, den spår också hur handlingar byggs upp och avklingar över tid. Det gör att den kan hitta längre, flerstegs-händelser som människor faktiskt bryr sig om, såsom en fullständig demonstration i en handledning eller nyckelsekvensen i en vlog, vilket gör framtida videoplattformar mer responsiva för naturliga språkfrågor.
Citering: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Nyckelord: sökning av videomoment, tvärmodal inlärning, temporal modellering, tillståndsrumssmodeller, videoförståelse