Clear Sky Science · ar
نموذج دمج معدل قائم على مانبا لاسترجاع لحظات الفيديو
لماذا يهم العثور على اللحظة المناسبة في الفيديو
من دروس الطبخ إلى إعادة لقطات الألعاب الرياضية، غالبًا نرغب في القفز مباشرة إلى اللحظة الدقيقة في فيديو طويل التي تتطابق مع وصف موجز مثل «عندما تقطع البصل» أو «الهدف النهائي». القيام بذلك يدويًا بطيء ومجهد. تعرض هذه الورقة طريقة جديدة تساعد الحواسيب على تحديد المقطع الزمني المناسب بسرعة استنادًا إلى اللغة الطبيعية، حتى عندما يكون الفيديو طويلًا والوصف يلمّح فقط إلى جزء مما يحدث.
تحدي البحث داخل الفيديوهات الطويلة
استرجاع لحظات الفيديو هو مهمة إيجاد المقطع الزمني الأكثر صلة في فيديو غير مُقتَطَع يتطابق مع جملة معطاة. أنظمة سابقة كانت تقسم الفيديو أولًا إلى العديد من المقاطع المرشحة ثم تحاول ترتيبها مقابل النص، مما جعل الدقة تعتمد كثيرًا على جودة تلك التخمينات الأولية. النماذج الأحدث «نهاية إلى نهاية» تتجنب هذه العملية ذات المرحلتين وتتنبأ مباشرة بأوقات البداية والنهاية باستخدام شبكات تعتمد على الانتباه. هذه النماذج الأحدث توائم الكلمات والإطارات جيدًا، لكنها ما تزال تكافح مع الفيديوهات الطويلة حيث يكون فهم ترتيب وتدفق الأحداث أمرًا حاسمًا، مثل وصفة متعددة الخطوات أو لعبة رياضية معقدة.
لماذا الانتباه التقليدي غير كافٍ
تعامل النماذج المبنية على الانتباه الفيديو كحقيبة من الإطارات، ما يسمح لأي إطار أن يرتبط بأي إطار آخر. ورغم أن هذا قوي لاكتشاف التطابقات البصرية، فقد يغفل الصورة الكبيرة لكيفية تتابع الأفعال عبر الزمن. على سبيل المثال، استعلام مثل «بعد إخراج العصارة، يعصر النصف الأول من البرتقال» يذكر فقط الخطوتين الأولى والأخيرة، بينما تمتد اللحظة الحقيقية عبر عدة إجراءات أصغر بينهما. قد يلتقط النموذج القياسي الإطارات الأكثر وضوحًا ويتجاهل الخطوات المخفية، مما يؤدي إلى تنبؤات ناقصة أو محرفة. بعض الأعمال الحديثة تحاول اختصار الفيديو أو تجميع الإطارات إلى أحداث أعلى مستوى، لكن ذلك قد يكسر التسلسل الطبيعي للقصة ويترك النموذج برؤية مجزأة للتسلسل الكامل.
طريقة جديدة لدمج النص والفيديو عبر الزمن
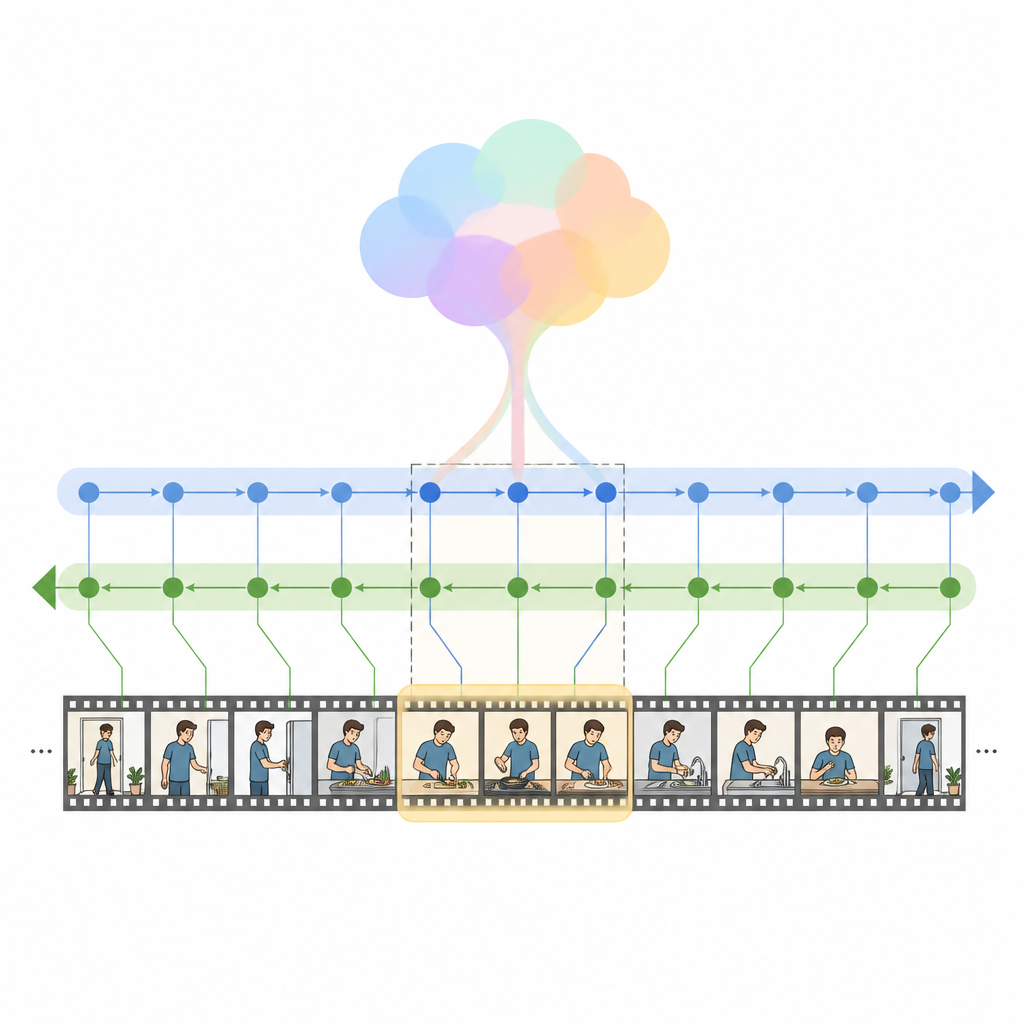
يقدم المؤلفون HM Net، شبكة مانبا هجينة تدمج مزايا الانتباه مع فئة أحدث من نماذج التسلسل تُسمى نماذج فضاء الحالة. في جوهرها توجد كتلة الهجين المعدلة ثنائية الاتجاه Mamba، التي تستخدم أولًا الانتباه المتقاطع لملاءمة كل إطار فيديو مع الكلمات ذات الصلة، ثم تمرر هذه المعلومة المدمجة عبر محرك زمني ثنائي الاتجاه يقرأ الفيديو للأمام وللخلف. مُلخص عام للاستعلام يوجّه هذه العملية، مُوجِهًا النموذج بلطف نحو النية العامة بدلًا من الكلمات المعزولة فقط. للمقاطع القصيرة، يساعد إشارة موضعية إضافية النظام على تتبُّع الترتيب، بينما للمقاطع الطويلة يعتمد النموذج أكثر على إحساسه المتعلَّم بالبنية الزمنية.
فهم خطوة بخطوة للحظات المعقدة
ينفذ HM Net الدمج على مرحلتين. في المرحلة الأولى، تُثري ميزات الفيديو بإشارات من النص بحيث «يعرف» كل إطار أي أجزاء الجملة هي الأهم. في المرحلة الثانية، يتبادل الفيديو والنص عملية تكرارية من التكرير المتناظر، مُنتجين تمثيلًا مشتركًا يلتقط التفاصيل الدقيقة والسياق طويل المدى في آن واحد. ثم يتنبأ وحدة فك الشفرة النهائية أي مقاطع من الخط الزمني هي الأنسب للاستعلام. يُدرّب النموذج ليس فقط لتحديد النطاقات الصحيحة، بل أيضًا لتمييز أزواج الفيديو والنص المتطابقة عن غير المتطابقة ولإعادة بناء أوصاف أعلى مستوى من المقاطع، مما يساعد على تضييق الرابط بين اللغة والأحداث البصرية.
دليل من فيديوهات الطهي والمقاطع اليومية
يُختبر الفريق HM Net على معيارين رئيسيين: TACoS، الذي يحتوي على فيديوهات طهي طويلة ومفصّلة، وQVHighlights، مجموعة من المقاطع الواقعية الأقصر مع استعلامات على شكل لقطات مميزة. على TACoS، حيث تكون الفيديوهات مطوّلة وتتطور الأفعال ببطء، يتفوق النموذج الجديد بوضوح على الأساليب الرائدة السابقة من حيث الدقة وجودة الترتيب. يكون النموذج قويًا بشكل خاص مع الاستعلامات الطويلة أو المعقدة التي تمتد لدقائق بدلًا من ثوانٍ. على QVHighlights، حيث العديد من المقاطع أقصر، تكون المكاسب أصغر لكنها لا تزال متسقة، ما يظهر أن التصميم الهجين مفيد حتى عندما يكون التفكير الزمني أقل تطلبًا. دراسات الإقصاء تؤكد أن كل مكوّن — جوهر المانبا ثنائي الاتجاه، والانتباه المتقاطع، وتجميع السياق العام — يساهم بشكل ملحوظ في الأداء النهائي.
ماذا يعني هذا لبحث الفيديو اليومي
بعبارة بسيطة، تُظهِر هذه الدراسة أن الجمع بين مطابقة الكلمات الدقيقة مع الإطارات وإحساس قوي بتدفق القصة يساعد الحواسيب على فهم الفيديوهات الطويلة والبحث فيها بشكل أفضل. لا يكتفي HM Net بالتمسك بالإطارات التي تبدو مناسبة، بل يتتبّع أيضًا كيف تتراكم الأفعال وتنكسر عبر الزمن. هذا يمكّنه من العثور على أحداث أطول ومتعددة الخطوات ذات أهمية فعلية للمستخدمين، مثل عرض كامل في درس إرشادي أو التسلسل الرئيسي في مدونة فيديو، مما يجعل منصات الفيديو المستقبلية أكثر تجاوبًا مع استعلامات اللغة الطبيعية.
الاستشهاد: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
الكلمات المفتاحية: استرجاع لحظات الفيديو, التعلم عبر الوسائط, النمذجة الزمنية, نماذج فضاء الحالة, فهم الفيديو