Clear Sky Science · es
Modelo de fusión modulada basado en Mamba para recuperación de momentos en vídeo
Por qué importa encontrar el momento adecuado en un vídeo
Desde tutoriales de cocina hasta repeticiones deportivas, a menudo queremos saltar directamente al instante exacto de un vídeo largo que coincide con una breve descripción, como “cuando corta las cebollas” o “el gol final”. Hacer esto manualmente es lento y fatigoso. Este artículo presenta un método nuevo que ayuda a los ordenadores a localizar rápidamente el tramo de tiempo adecuado en un vídeo a partir de lenguaje natural, incluso cuando el vídeo es largo y la descripción solo alude a parte de lo que ocurre.
El reto de buscar dentro de vídeos largos
La recuperación de momentos en vídeo es la tarea de encontrar el segmento temporal más relevante en un vídeo sin recortar que coincida con una oración dada. Los sistemas anteriores primero dividían el vídeo en muchos clips candidatos y luego intentaban clasificarlos frente al texto, lo que hacía que la precisión dependiera en gran medida de la calidad de esas conjeturas iniciales. Los modelos “end to end” más recientes evitan este proceso en dos pasos y predicen directamente los tiempos de inicio y fin usando redes basadas en attention. Estos modelos nuevos alinean bien palabras y fotogramas, pero siguen teniendo problemas con vídeos largos donde entender el orden y el flujo de los eventos es crucial, como una receta con varios pasos o una jugada deportiva complicada.
Por qué la atención habitual se queda corta
Los modelos basados en attention tratan el vídeo como una bolsa de fotogramas, permitiendo que cualquier fotograma se conecte con cualquiera otro. Aunque esto es potente para detectar coincidencias visuales, puede perder la visión global de cómo se desarrollan las acciones en el tiempo. Por ejemplo, una consulta como “Después de sacar el exprimidor, exprime la primera mitad de la naranja” solo menciona el primer y el último paso, pero el momento real abarca varias acciones menores entre ellos. Los modelos estándar pueden aferrarse a los fotogramas más evidentes e ignorar los pasos intermedios, lo que conduce a predicciones incompletas o desplazadas. Algunos trabajos recientes intentan acortar los vídeos o agrupar fotogramas en eventos de nivel superior, pero esto puede romper la narrativa natural y sigue dejando al modelo con una visión parcial de la secuencia completa.
Una nueva forma de fusionar texto y vídeo a lo largo del tiempo
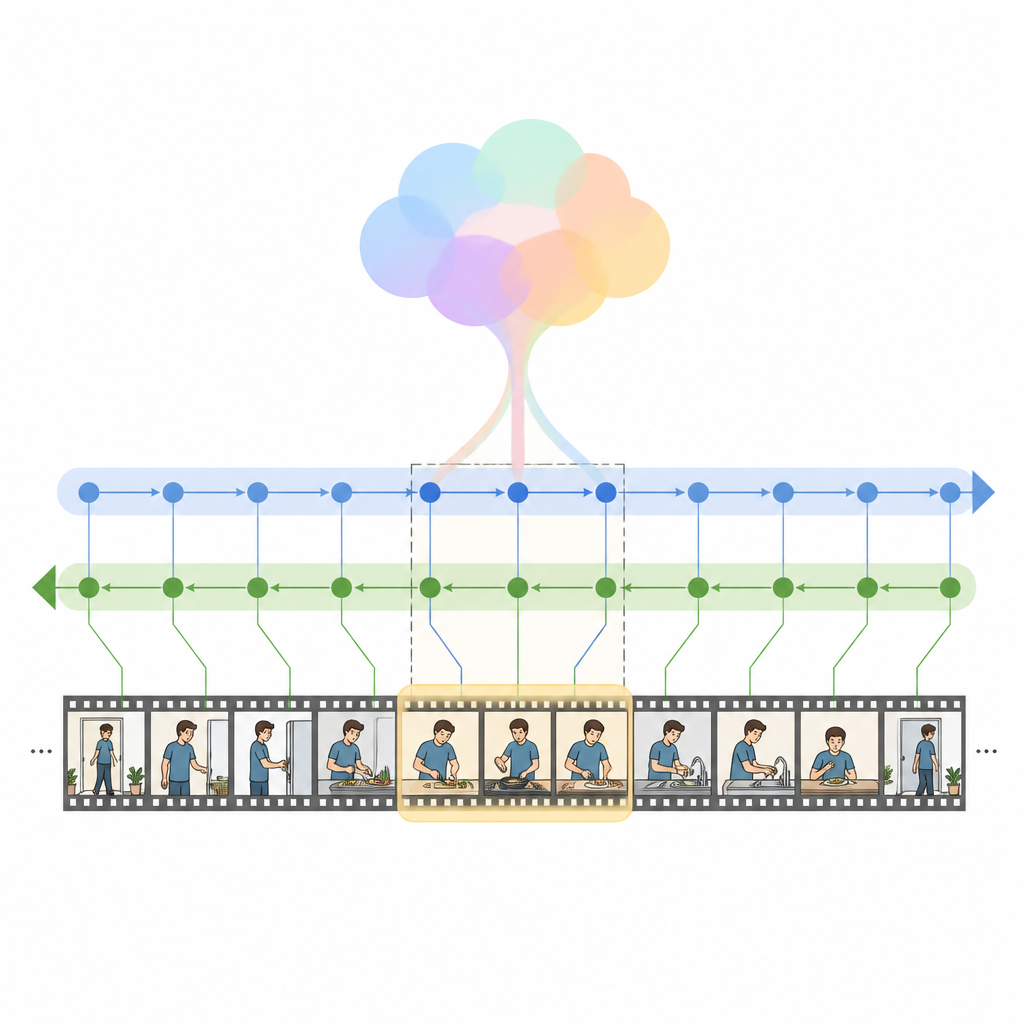
Los autores introducen HM Net, una Red Híbrida Mamba que combina las fortalezas de la attention con una clase más reciente de modelos de secuencia llamados modelos de espacio de estados. En su núcleo está el bloque Hybrid Modulated Bi Mamba, que primero usa cross attention para alinear cada fotograma de vídeo con las palabras relevantes y luego pasa esta información fusionada por un motor temporal bidireccional que lee el vídeo tanto hacia adelante como hacia atrás. Un resumen global de la consulta guía este proceso, orientando suavemente al modelo hacia la intención general en lugar de solo palabras aisladas. Para clips cortos, una señal posicional adicional ayuda al sistema a mantener el orden, mientras que en clips largos el modelo se apoya más en su sentido aprendido de la estructura temporal.
Comprensión paso a paso de momentos complejos
HM Net realiza la fusión en dos etapas. En la primera etapa, las características del vídeo se enriquecen con pistas del texto de modo que cada fotograma “sepa” qué partes de la oración importan más. En la segunda etapa, vídeo y texto se refinan mutuamente de forma iterativa y simétrica, creando una representación compartida que captura detalle fino y contexto de largo alcance al mismo tiempo. Un módulo de decodificación final predice entonces qué segmentos de la línea temporal mejor coinciden con la consulta. El modelo se entrena no solo para localizar los intervalos correctos, sino también para distinguir pares vídeo-texto coincidentes de los no coincidentes y para reconstruir descripciones de nivel superior a partir de segmentos, lo que ayuda a estrechar el vínculo entre el lenguaje y los eventos visuales.
Evidencia a partir de vídeos de cocina y clips cotidianos
El equipo prueba HM Net en dos benchmarks principales: TACoS, que contiene vídeos de cocina largos y detallados, y QVHighlights, una colección de clips del mundo real más cortos con consultas estilo highlights. En TACoS, donde los vídeos son extensos y las acciones se despliegan lentamente, el nuevo modelo supera claramente a los métodos líderes previos tanto en precisión como en calidad de ranking. Es especialmente sólido en consultas muy largas o complejas que abarcan minutos en lugar de segundos. En QVHighlights, donde muchos clips son más cortos, las ganancias son menores pero consistentes, mostrando que el diseño híbrido ayuda incluso cuando el razonamiento temporal es menos exigente. Los estudios de ablación confirman que cada ingrediente—el núcleo Mamba bidireccional, la cross attention y el pooling de contexto global—contribuye de forma significativa al rendimiento final.
Qué implica esto para la búsqueda de vídeo cotidiana
En términos sencillos, esta investigación muestra que emparejar una coincidencia precisa palabra-fotograma con un fuerte sentido del flujo narrativo ayuda a los ordenadores a comprender y buscar mejor vídeos largos. HM Net no solo se fija en los fotogramas que parecen correctos, sino que también sigue cómo las acciones se construyen y se disipan en el tiempo. Esto le permite encontrar eventos largos y de varios pasos que importan a las personas, como una demostración completa en un tutorial o la secuencia clave en un vlog, haciendo que las futuras plataformas de vídeo respondan mejor a consultas en lenguaje natural.
Cita: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Palabras clave: recuperación de momentos en vídeo, aprendizaje cross-modal, modelado temporal, modelos de espacio de estados, comprensión de vídeo