Clear Sky Science · en
Mamba-based modulated fusion model for video moment retrieval
Why finding the right moment in video matters
From cooking tutorials to sports replays, we often want to jump straight to the exact moment in a long video that matches a short description, such as “when she chops the onions” or “the final goal.” Doing this by hand is slow and tiring. This paper presents a new method that helps computers quickly locate the right stretch of time in a video based on natural language, even when the video is long and the description only hints at part of what happens.
The challenge of searching inside long videos
Video Moment Retrieval is the task of finding the most relevant time segment in an untrimmed video that matches a given sentence. Earlier systems first sliced the video into many candidate clips and then tried to rank them against the text, which made accuracy depend heavily on the quality of those initial guesses. Newer “end to end” models avoid this two step process and directly predict start and end times using attention based networks. These newer models align words and frames well, but they still struggle with long videos where understanding the order and flow of events is crucial, such as a multi step recipe or a complicated sports play.
Why usual attention falls short
Attention based models treat a video as a bag of frames, allowing any frame to connect to any other. While this is powerful for spotting visual matches, it can miss the big picture of how actions unfold over time. For example, a query like “After taking out the juicer, he squeezes the first orange half” only mentions the first and last steps, yet the true moment spans several smaller actions between them. Standard models may latch onto the most obvious frames and ignore the hidden steps, leading to incomplete or shifted predictions. Some recent work tries to shorten videos or group frames into higher level events, but this can break the natural storyline and still leaves the model with a patchy view of the full sequence.
A new way to fuse text and video over time
The authors introduce HM Net, a Hybrid Mamba Network that combines the strengths of attention with a newer class of sequence models called state space models. At its core is the Hybrid Modulated Bi Mamba block, which first uses cross attention to align each video frame with the relevant words, and then passes this fused information through a bidirectional temporal engine that reads the video both forward and backward. A global summary of the query guides this process, gently steering the model toward the overall intent rather than just isolated words. For shorter clips, an extra positional signal helps the system keep track of ordering, while for long clips the model relies more on its learned sense of temporal structure.
Step by step understanding of complex moments
HM Net performs fusion in two stages. In the first stage, the video features are enriched with cues from the text so that each frame “knows” which parts of the sentence matter most. In the second stage, video and text repeatedly refine each other in a symmetric fashion, creating a shared representation that captures fine detail and long range context at the same time. A final decoding module then predicts which segments of the timeline best match the query. The model is trained not only to locate the correct spans, but also to distinguish matching video text pairs from mismatched ones and to rebuild higher level descriptions from segments, which helps tighten the link between language and visual events.
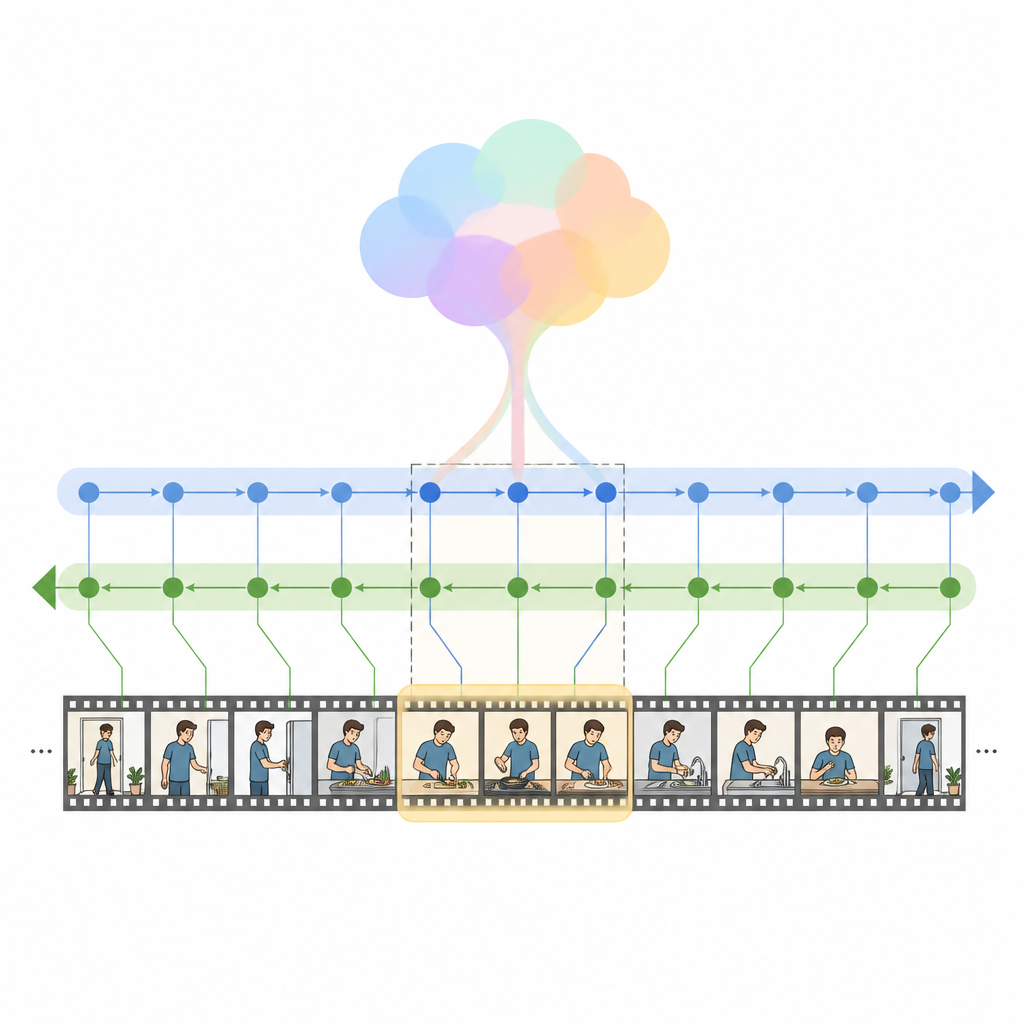
Evidence from cooking videos and daily clips
The team tests HM Net on two major benchmarks: TACoS, which contains long, detailed cooking videos, and QVHighlights, a collection of shorter, real world clips with highlight style queries. On TACoS, where videos are lengthy and actions unfold slowly, the new model clearly outperforms previous leading methods in both accuracy and ranking quality. It is especially strong on very long or complex queries that span minutes rather than seconds. On QVHighlights, where many clips are shorter, gains are smaller but still consistent, showing that the hybrid design helps even when temporal reasoning is less demanding. Ablation studies confirm that each ingredient—the bidirectional Mamba core, cross attention, and global context pooling—contributes meaningfully to the final performance.
What this means for everyday video search
In simple terms, this research shows that pairing precise word frame matching with a strong sense of story flow helps computers better understand and search long videos. HM Net not only locks onto the frames that look right, it also tracks how actions build up and wind down over time. This allows it to find longer, multi step events that people actually care about, such as a full demonstration in a tutorial or the key sequence in a vlog, making future video platforms more responsive to natural language queries.
Citation: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Keywords: video moment retrieval, cross modal learning, temporal modeling, state space models, video understanding