Clear Sky Science · it
Modello di fusione modulata basato su Mamba per il recupero di momenti video
Perché è importante trovare il momento giusto in un video
Dai tutorial di cucina alle repliche sportive, spesso vogliamo saltare direttamente al punto preciso di un video lungo che corrisponde a una breve descrizione, ad esempio “quando taglia le cipolle” o “il gol finale”. Farlo manualmente è lento e faticoso. Questo articolo presenta un nuovo metodo che aiuta i computer a localizzare rapidamente l'intervallo temporale corretto in un video basandosi sul linguaggio naturale, anche quando il video è lungo e la descrizione accenna solo a parte di quanto accade.
La sfida di cercare all'interno di video lunghi
Il Video Moment Retrieval è il compito di trovare il segmento temporale più rilevante in un video non ritagliato che corrisponde a una frase fornita. I sistemi precedenti tagliavano prima il video in molti clip candidati e poi cercavano di classificarli rispetto al testo, rendendo la precisione fortemente dipendente dalla qualità di quelle ipotesi iniziali. I modelli più recenti “end-to-end” evitano questo processo in due fasi e predicono direttamente i tempi di inizio e fine usando reti basate su attenzione. Questi modelli allineano bene parole e frame, ma faticano ancora con video lunghi in cui comprendere l'ordine e il flusso degli eventi è cruciale, come una ricetta con più passaggi o una giocata sportiva complessa.
Perché l'attenzione tradizionale non basta
I modelli basati su attenzione trattano il video come un insieme di frame, permettendo a qualsiasi frame di connettersi a qualsiasi altro. Pur essendo potente per individuare corrispondenze visive, questo approccio può perdere la visione d'insieme di come le azioni si sviluppano nel tempo. Per esempio, una query come “Dopo aver tirato fuori lo spremiagrumi, lui stringe la prima metà d'arancia” menziona solo i passi iniziale e finale, eppure il momento vero comprende diverse azioni più piccole tra di loro. I modelli standard possono aggrapparsi ai frame più evidenti e ignorare i passaggi nascosti, portando a predizioni incomplete o spostate. Alcuni lavori recenti cercano di accorciare i video o raggruppare i frame in eventi di livello superiore, ma questo può spezzare la linea narrativa naturale e lasciare il modello con una visione frammentaria della sequenza completa.
Un nuovo modo di fondere testo e video nel tempo
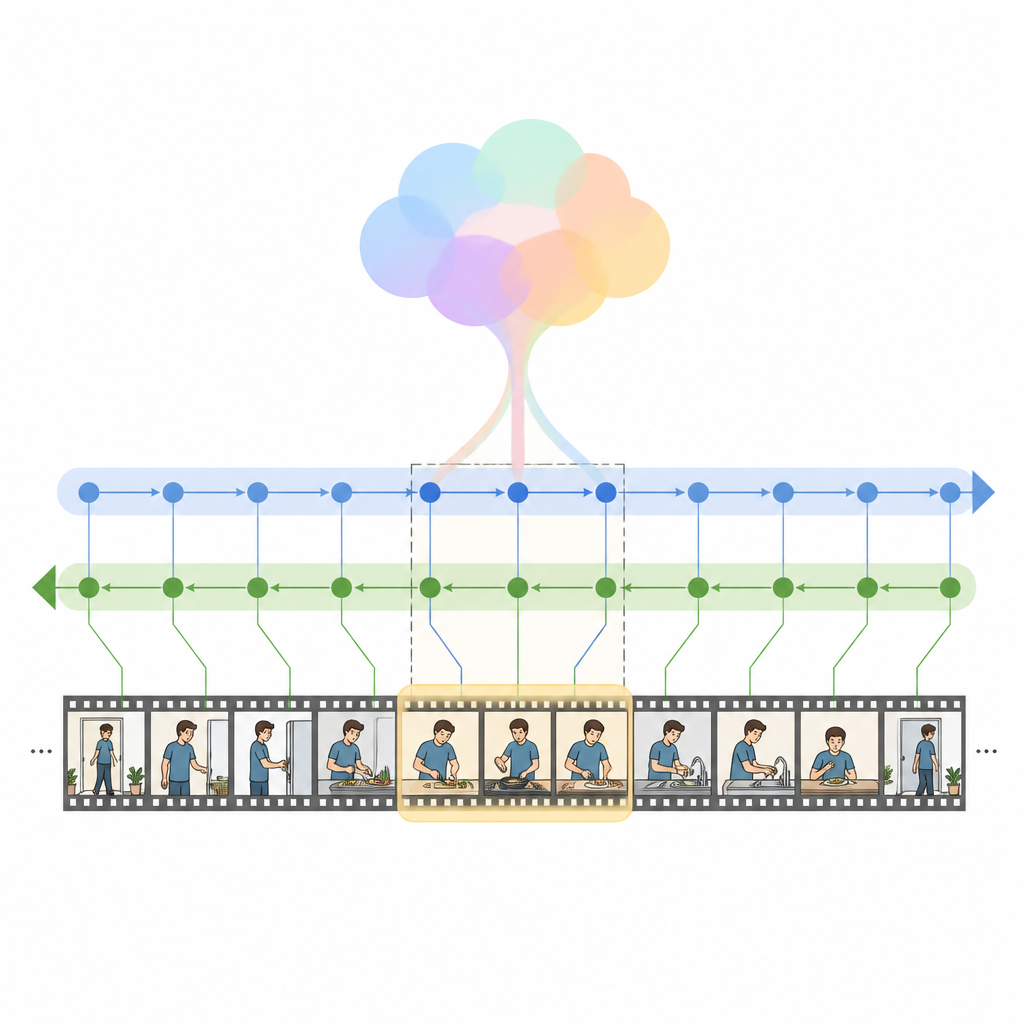
Gli autori introducono HM Net, un Hybrid Mamba Network che combina i punti di forza dell'attenzione con una classe più recente di modelli di sequenza chiamati modelli a spazio di stato. Al centro c'è il blocco Hybrid Modulated Bi Mamba, che prima usa la cross-attention per allineare ogni frame video con le parole rilevanti, e poi passa queste informazioni fuse attraverso un motore temporale bidirezionale che legge il video sia in avanti sia all'indietro. Un riepilogo globale della query guida questo processo, orientando delicatamente il modello verso l'intento complessivo piuttosto che verso parole isolate. Per clip più corte, un segnale posizionale aggiuntivo aiuta il sistema a mantenere il senso dell'ordine, mentre per clip lunghe il modello si affida maggiormente alla sua capacità appresa di rappresentare la struttura temporale.
Comprensione passo dopo passo di momenti complessi
HM Net esegue la fusione in due fasi. Nella prima fase, le caratteristiche video vengono arricchite con indizi dal testo in modo che ogni frame “sappia” quali parti della frase sono più importanti. Nella seconda fase, video e testo si perfezionano reciprocamente in modo simmetrico, creando una rappresentazione condivisa che cattura allo stesso tempo dettagli fini e contesto a lungo raggio. Un modulo di decodifica finale predice quindi quali segmenti della linea temporale corrispondono meglio alla query. Il modello viene addestrato non solo a localizzare gli intervalli corretti, ma anche a distinguere coppie video-testo corrispondenti da quelle non corrispondenti e a ricostruire descrizioni di livello superiore a partire dai segmenti, il che aiuta a rafforzare il legame tra linguaggio ed eventi visivi.
Prove da video di cucina e clip quotidiane
Il team testa HM Net su due benchmark principali: TACoS, che contiene video di cucina lunghi e dettagliati, e QVHighlights, una raccolta di clip più brevi del mondo reale con query in stile highlight. Su TACoS, dove i video sono lunghi e le azioni si svolgono lentamente, il nuovo modello supera chiaramente i metodi leader precedenti sia in accuratezza sia nella qualità del ranking. È particolarmente forte su query molto lunghe o complesse che si estendono per minuti piuttosto che secondi. Su QVHighlights, dove molti clip sono più corti, i guadagni sono minori ma comunque coerenti, mostrando che il design ibrido aiuta anche quando il ragionamento temporale è meno impegnativo. Studi di ablation confermano che ogni componente — il nucleo Mamba bidirezionale, la cross-attention e il pooling del contesto globale — contribuisce in modo significativo alla prestazione finale.
Cosa significa per la ricerca video di tutti i giorni
In termini semplici, questa ricerca mostra che abbinare l'allineamento preciso di parole e frame con un solido senso del flusso narrativo aiuta i computer a comprendere e cercare meglio i video lunghi. HM Net non solo individua i frame che appaiono corretti, ma segue anche come le azioni si accumulano e si concludono nel tempo. Questo gli consente di trovare eventi lunghi e a più passi che interessano davvero le persone, come una dimostrazione completa in un tutorial o la sequenza chiave in un vlog, rendendo le future piattaforme video più reattive alle query in linguaggio naturale.
Citazione: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Parole chiave: recupero di momenti video, apprendimento cross-modale, modellazione temporale, modelli a spazio di stato, comprensione video