Clear Sky Science · pt
Modelo de fusão modulado baseado em Mamba para recuperação de momentos em vídeo
Por que encontrar o momento certo em um vídeo importa
De tutoriais de culinária a reprises esportivas, frequentemente queremos pular diretamente para o instante exato em um vídeo longo que corresponda a uma descrição curta, como “quando ela pica as cebolas” ou “o gol final”. Fazer isso manualmente é lento e cansativo. Este artigo apresenta um novo método que ajuda computadores a localizar rapidamente o trecho correto do vídeo com base em linguagem natural, mesmo quando o vídeo é longo e a descrição só faz referência a parte do que acontece.
O desafio de buscar dentro de vídeos longos
Video Moment Retrieval é a tarefa de encontrar o segmento temporal mais relevante em um vídeo não editado que corresponda a uma sentença dada. Sistemas anteriores primeiro fatiavam o vídeo em muitos clipes candidatos e depois tentavam ranqueá-los em relação ao texto, o que tornava a precisão fortemente dependente da qualidade dessas suposições iniciais. Modelos “end-to-end” mais recentes evitam esse processo em dois passos e predizem diretamente tempos de início e fim usando redes baseadas em atenção. Esses modelos alinham bem palavras e quadros, mas ainda têm dificuldades com vídeos longos onde entender a ordem e o fluxo dos eventos é crucial, como uma receita com vários passos ou uma jogada esportiva complicada.
Por que a atenção usual não é suficiente
Modelos baseados em atenção tratam um vídeo como um saco de quadros, permitindo que qualquer quadro se conecte a qualquer outro. Embora isso seja poderoso para identificar correspondências visuais, pode perder a visão geral de como as ações se desenrolam ao longo do tempo. Por exemplo, uma consulta como “Depois de tirar o espremedor, ele aperta a primeira metade da laranja” menciona apenas o primeiro e o último passos, mas o momento real se estende por várias ações menores entre eles. Modelos padrão podem se fixar nos quadros mais óbvios e ignorar os passos ocultos, levando a previsões incompletas ou deslocadas. Trabalhos recentes tentam encurtar vídeos ou agrupar quadros em eventos de nível mais alto, mas isso pode quebrar a narrativa natural e ainda deixar o modelo com uma visão fragmentada da sequência completa.
Uma nova forma de fundir texto e vídeo ao longo do tempo
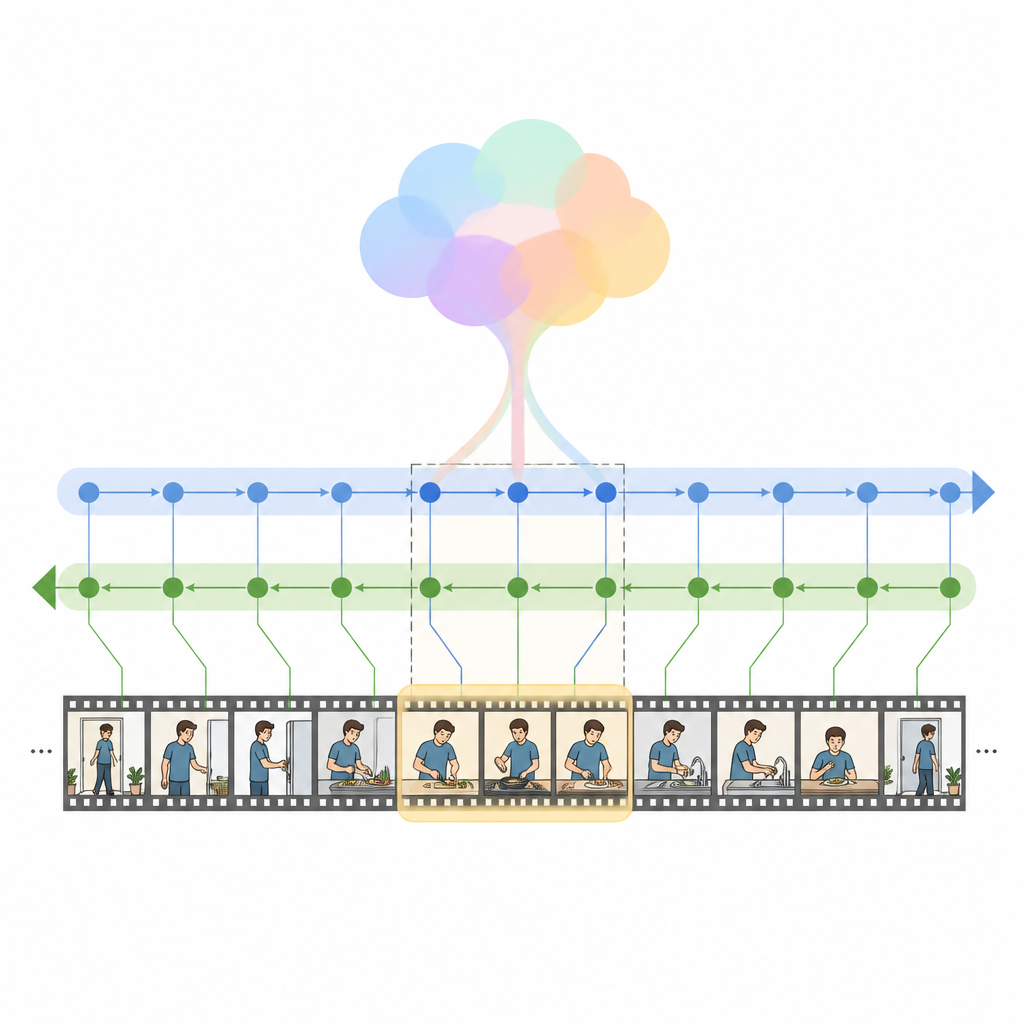
Os autores introduzem o HM Net, uma Hybrid Mamba Network que combina as vantagens da atenção com uma classe mais nova de modelos de sequência chamados modelos de espaço de estados. No núcleo está o bloco Hybrid Modulated Bi Mamba, que primeiro usa cross-attention para alinhar cada quadro do vídeo com as palavras relevantes, e então passa essa informação fundida por um motor temporal bidirecional que lê o vídeo tanto para frente quanto para trás. Um resumo global da consulta guia esse processo, orientando sutilmente o modelo para a intenção geral em vez de apenas palavras isoladas. Para clipes mais curtos, um sinal posicional extra ajuda o sistema a acompanhar a ordenação, enquanto para clipes longos o modelo confia mais em seu sentido aprendido de estrutura temporal.
Compreensão passo a passo de momentos complexos
O HM Net realiza a fusão em duas etapas. Na primeira etapa, as features do vídeo são enriquecidas com pistas do texto para que cada quadro “saiba” quais partes da sentença são mais importantes. Na segunda etapa, vídeo e texto refinam-se repetidamente de forma simétrica, criando uma representação compartilhada que captura detalhes finos e contexto de longo alcance ao mesmo tempo. Um módulo final de decodificação então prediz quais segmentos da linha do tempo melhor correspondem à consulta. O modelo é treinado não apenas para localizar os intervalos corretos, mas também para distinguir pares vídeo-texto correspondentes de pares não correspondentes e para reconstruir descrições de nível mais alto a partir de segmentos, o que ajuda a reforçar a ligação entre linguagem e eventos visuais.
Evidências em vídeos de culinária e clipes do dia a dia
A equipe testa o HM Net em dois benchmarks principais: TACoS, que contém vídeos de culinária longos e detalhados, e QVHighlights, uma coleção de clipes do mundo real, mais curtos, com consultas no estilo de highlights. No TACoS, onde os vídeos são longos e as ações se desenrolam devagar, o novo modelo supera claramente métodos líderes anteriores tanto em precisão quanto em qualidade de ranqueamento. Ele é especialmente forte em consultas muito longas ou complexas que se estendem por minutos em vez de segundos. No QVHighlights, onde muitos clipes são mais curtos, os ganhos são menores, mas ainda consistentes, mostrando que o design híbrido ajuda mesmo quando o raciocínio temporal é menos exigente. Estudos de ablação confirmam que cada ingrediente — o núcleo Mamba bidirecional, a cross-attention e o pooled de contexto global — contribui significativamente para a performance final.
O que isso significa para a busca de vídeo no dia a dia
Em termos simples, esta pesquisa mostra que emparelhar um correspondência precisa entre palavras e quadros com um forte senso de fluxo narrativo ajuda computadores a entender e buscar melhor vídeos longos. O HM Net não apenas identifica os quadros que parecem corretos, ele também acompanha como as ações se acumulam e se encerram ao longo do tempo. Isso permite encontrar eventos longos e em vários passos que realmente importam para as pessoas, como uma demonstração completa em um tutorial ou a sequência-chave em um vlog, tornando futuras plataformas de vídeo mais responsivas a consultas em linguagem natural.
Citação: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Palavras-chave: recuperação de momentos em vídeo, aprendizado cross-modal, modelagem temporal, modelos de espaço de estados, compreensão de vídeo