Clear Sky Science · nl
Mamba-gebaseerd gemoduleerd fusiemodel voor video momentopvraging
Waarom het vinden van het juiste moment in video ertoe doet
Van kooktutorials tot sportherhalingen: we willen vaak meteen naar het precieze moment in een lange video springen dat bij een korte beschrijving past, zoals “wanneer ze de uien snijdt” of “het laatste doelpunt.” Dit met de hand doen is traag en vermoeiend. Dit artikel presenteert een nieuwe methode die computers helpt snel het juiste tijdsinterval in een video te lokaliseren op basis van natuurlijke taal, zelfs wanneer de video lang is en de beschrijving maar een deel van wat gebeurt aangeeft.
De uitdaging van zoeken in lange video’s
Video Moment Retrieval is de taak om het meest relevante tijdsegment in een ongetrimde video te vinden dat overeenkomt met een gegeven zin. Eerdere systemen deelden de video eerst op in veel kandidaatclips en probeerden die vervolgens tegen de tekst te rangschikken, waardoor de nauwkeurigheid sterk van die initiële schattingen afhing. Nieuwere end-to-end modellen vermijden dit tweestappenproces en voorspellen direct begin- en eindtijden met op attention gebaseerde netwerken. Deze nieuwere modellen stemmen woorden en frames goed op elkaar af, maar hebben nog steeds moeite met lange video’s waarin het begrip van volgorde en de stroom van gebeurtenissen cruciaal is, zoals een meerstappenrecept of een ingewikkelde sportactie.
Waarom gebruikelijke attention tekortschiet
Attention-gebaseerde modellen behandelen een video als een zak met frames, waardoor elk frame met elk ander frame kan verbinden. Hoewel dit krachtig is voor het herkennen van visuele overeenkomsten, kan het het grotere geheel van hoe acties zich in de tijd ontvouwen missen. Een query als “Na het te hebben gehaald, knijpt hij de eerste sinaasappelhelft uit” noemt bijvoorbeeld alleen de eerste en laatste stap, terwijl het werkelijke moment meerdere tussenliggende acties omvat. Standaardmodellen kunnen zich vastklampen aan de meest voor de hand liggende frames en de verborgen stappen negeren, wat leidt tot onvolledige of verschoven voorspellingen. Sommige recente werken proberen video’s in te korten of frames te groeperen in hogere niveau gebeurtenissen, maar dat kan de natuurlijke verhaallijn verstoren en laat het model nog steeds met een gefragmenteerd beeld van de volledige sequentie zitten.
Een nieuwe manier om tekst en video in de tijd te fuseren
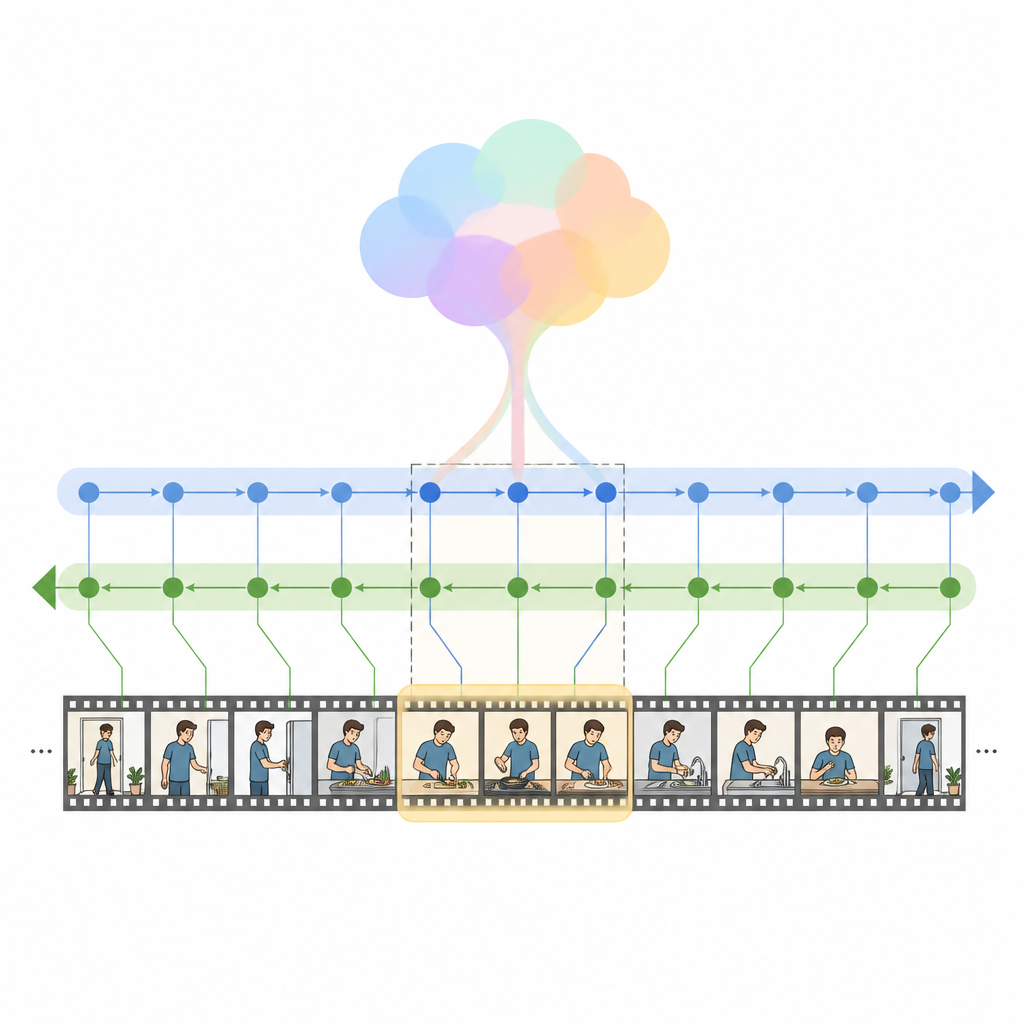
De auteurs introduceren HM Net, een Hybrid Mamba Network dat de sterke punten van attention combineert met een nieuwere klasse sequentiemodellen, zogenaamde staat-ruimtemodellen. Centraal staat het Hybrid Modulated Bi Mamba-blok, dat eerst cross-attention gebruikt om elk videoframe af te stemmen op de relevante woorden, en deze gefuseerde informatie vervolgens door een bidirectionele temporele motor stuurt die de video zowel vooruit als achteruit leest. Een globale samenvatting van de query begeleidt dit proces en stuurt het model subtiel richting de algemene intentie in plaats van alleen geïsoleerde woorden. Voor kortere clips helpt een extra positioneel signaal het systeem de volgorde bij te houden, terwijl het model bij langere clips meer leunt op zijn aangeleerde gevoel voor temporele structuur.
Stap-voor-stap begrip van complexe momenten
HM Net voert de fusie in twee fasen uit. In de eerste fase worden de videofeatures verrijkt met aanwijzingen uit de tekst zodat elk frame “weet” welke delen van de zin het meest relevant zijn. In de tweede fase verfijnen video en tekst herhaaldelijk elkaar op een symmetrische manier, waardoor een gedeelde representatie ontstaat die tegelijkertijd fijne details en lang bereik context vastlegt. Een uiteindelijke decodeermodule voorspelt dan welke segmenten van de tijdlijn het beste bij de query passen. Het model wordt niet alleen getraind om de juiste intervallen te lokaliseren, maar ook om overeenkomende video-tekstparen te onderscheiden van niet-overeenkomende en om hogereniveau beschrijvingen uit segmenten te reconstrueren, wat helpt de band tussen taal en visuele gebeurtenissen te versterken.
Bewijs uit kookvideo’s en alledaagse clips
Het team test HM Net op twee belangrijke benchmarks: TACoS, dat lange, gedetailleerde kookvideo’s bevat, en QVHighlights, een verzameling kortere, realistische clips met highlight‑achtige queries. Op TACoS, waar video’s lang zijn en acties zich langzaam ontvouwen, presteert het nieuwe model duidelijk beter dan eerdere toonaangevende methoden, zowel qua nauwkeurigheid als rangschikkingskwaliteit. Het is vooral sterk bij zeer lange of complexe queries die minuten in plaats van seconden beslaan. Op QVHighlights, waar veel clips korter zijn, zijn de winstpunten kleiner maar nog steeds consistent, wat aantoonde dat het hybride ontwerp ook helpt wanneer temporeel redeneren minder veeleisend is. Ablatiestudies bevestigen dat elk ingrediënt — de bidirectionele Mamba-kern, cross‑attention en globale contextpooling — een wezenlijke bijdrage levert aan de uiteindelijke prestatie.
Wat dit betekent voor alledaagse videozoekopdrachten
Kort gezegd laat dit onderzoek zien dat het combineren van nauwkeurige woord‑frame‑matching met een sterk gevoel voor verhaallijn computers helpt langere video’s beter te begrijpen en doorzoeken. HM Net richt zich niet alleen op frames die visueel kloppen, maar volgt ook hoe acties zich opbouwen en aflopen in de tijd. Daardoor kan het langere, meerstapsgebeurtenissen vinden die mensen werkelijk belangrijk vinden, zoals een volledige demonstratie in een tutorial of de sleutelsequentie in een vlog, waardoor toekomstige videoplatforms responsiever worden voor natuurlijke taalvragen.
Bronvermelding: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Trefwoorden: video momentopvraging, crossmodaal leren, temporele modellering, staat-ruimtemodellen, video begrip