Clear Sky Science · he
מודל מיזוג מוודל מבוסס ממבה למשיכת רגעים בווידאו
מדוע חשוב למצוא את הרגע המדויק בווידאו
מתוך מדריכי בישול ועד שידורי ספורט חוזרים, לעתים קרובות אנו רוצים לקפוץ ישירות לרגע המדויק בסרטון ארוך שמתאים לתיאור קצר, כגון «כשהיא קוצצת את הבצל» או «המטרה הסופית». עשייה זו ידנית איטית ומתישה. מאמר זה מציג שיטה חדשה שעוזרת למחשבים לאתר במהירות את קטע הזמן המתאים בווידאו על סמך שפה טבעית, אפילו כשהסרטון ארוך והתיאור מרמז רק על חלק ממה שקורה.
האתגר של חיפוש בתוך סרטונים ארוכים
Video Moment Retrieval (משיכת רגעים בווידאו) היא המשימה של מציאת קטע הזמן הרלוונטי ביותר בסרטון לא מטופל שמתאים למשפט נתון. מערכות מוקדמות עוד קודם חלקו את הווידאו להרבה קטעי מועמדים ואז ניסו לדרגם מול הטקסט, מה שהפך את הדיוק לתלוי מאוד באיכות ההשערות הראשוניות. דגמים חדשים יותר, בסגנון "קצה-לקצה", נמנעים מתהליך דו־השלבי הזה ומנבאים ישירות זמני התחלה וסיום באמצעות רשתות מבוססות תשומת לב. דגמים אלה מטיבים להתאים בין מילים למסגרות, אך עדיין מתקשים בסרטונים ארוכים שבהם הבנת הסדר וזרימת האירועים קריטית, כמו במתכון רב־שלבי או מהלך ספורט מסובך.
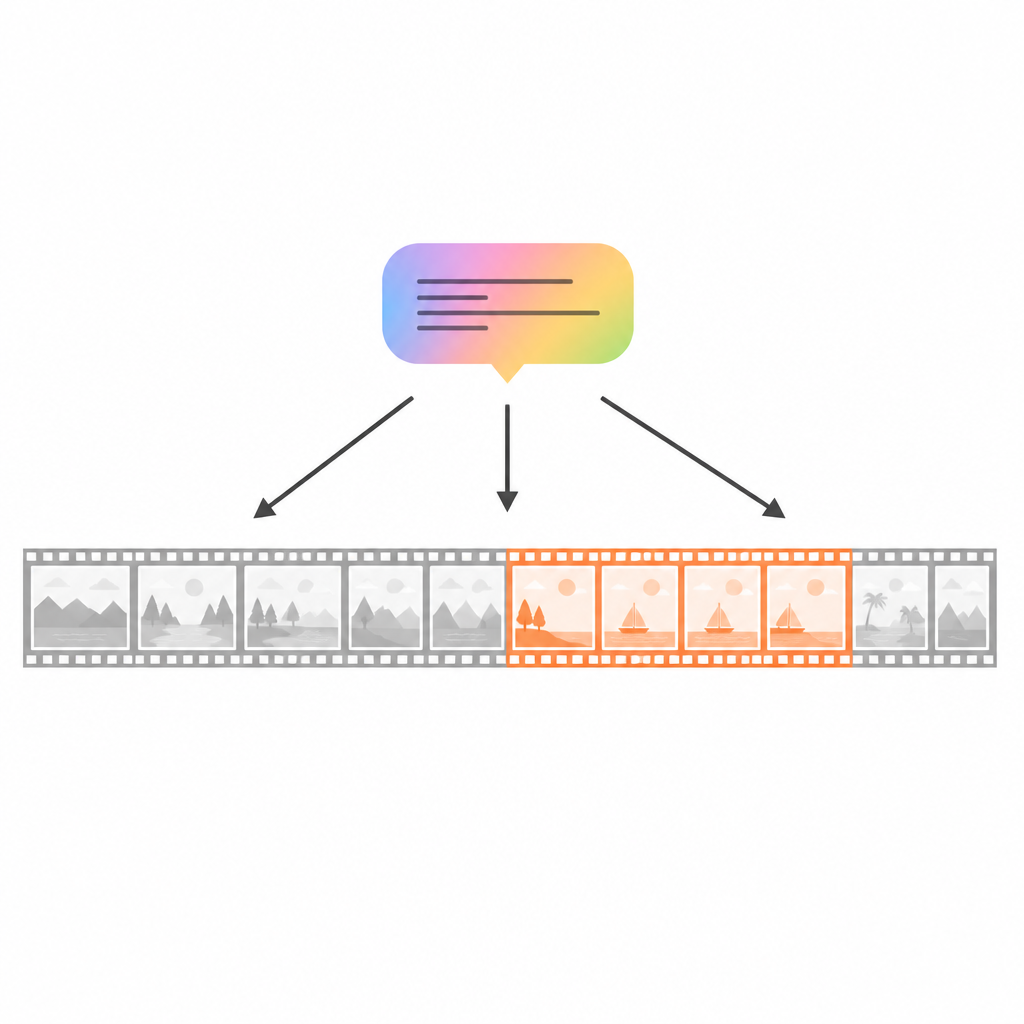
למה תשומת לב רגילה לא מספיקה
דגמי תשומת לב מתייחסים לווידאו כשק של מסגרות, ומאפשרים לכל מסגרת להתחבר לכל מסגרת אחרת. בעוד שזה חזק לזיהוי התאמות ויזואליות, זה עלול לפספס את התמונה הגדולה של איך פעולות מתפתחות לאורך הזמן. לדוגמה, שאילתה כמו «לאחר הוצאת הסחטת, הוא סוחט את חצי התפוז הראשון» מזכירה רק את הצעד הראשון והאחרון, אך הרגע האמיתי משתרע על פני כמה פעולות קטנות בין־ביניהן. דגמים סטנדרטיים עשויים להתבסס על המסגרות הברורות ביותר ולתעלם מהצעדים הנסתרים, מה שמוביל לניבויים חלקיים או משונים. עבודות עדכניות מנסות לקצר סרטונים או לקבץ מסגרות לאירועים ברמה גבוהה יותר, אך זה עלול לשבור את רצף הסיפור הטבעי ועדיין להשאיר את המודל עם מבט חלקי על הסדר המלא.
דרך חדשה למזג טקסט ווידאו לאורך זמן
המחברים מציגים את HM Net, Hybrid Mamba Network שמשלבת את יתרונות התשומת לב עם מחלקה חדשה של מודלים רצפים הנקראת מודלים של מרחב מצבים. בלב המערכת נמצא בלוק Hybrid Modulated Bi Mamba, שמשתמש תחילה בתשומת לב חוצת־מודאליות כדי ליישר כל מסגרת וידאו עם המילים הרלוונטיות, ולאחר מכן מעביר את המידע הממוזג דרך מנוע זמני כיווני־דו־כיווני שקורא את הווידאו גם קדימה וגם אחורה. סיכום גלובלי של השאילתא מנווט את התהליך הזה, מלווה בעדינות את המודל לכוונה הכוללת במקום להישאב רק למילים מבודדות. עבור קטעים קצרים יותר, אות מיקומי נוסף מסייע למערכת לשמור על סדר, בעוד שקטעים ארוכים יותר מסתמכים יותר על תחושת המבנה הזמני שנלמדה.
הבנה שלב־אחר־שלב של רגעים מורכבים
HM Net מבצע מיזוג בשני שלבים. בשלב הראשון, תכונות הווידאו מועשרו באיתותים מהטקסט כך שכל מסגרת "יודעת" אילו חלקי המשפט חשובים ביותר. בשלב השני, הווידאו והטקסט משכללים זה את זה באופן סימטרי וחוזר, וכך יוצרים ייצוג משותף שתופס פרטים דקים והקשר לטווח ארוך בו־זמנית. מודול דקודינג סופי מנבא אז אילו קטעי ציר הזמן מתאימים ביותר לשאילתא. המודל מאומן לא רק לאתר את ההיסקים הנכונים, אלא גם להבחין בין זוגות וידאו־טקסט תואמים לזוגות שאינם תואמים ולבנות תיאורים ברמה גבוהה מחתכים, מה שעוזר לחזק את הקשר בין השפה לאירועים הוויזואליים.
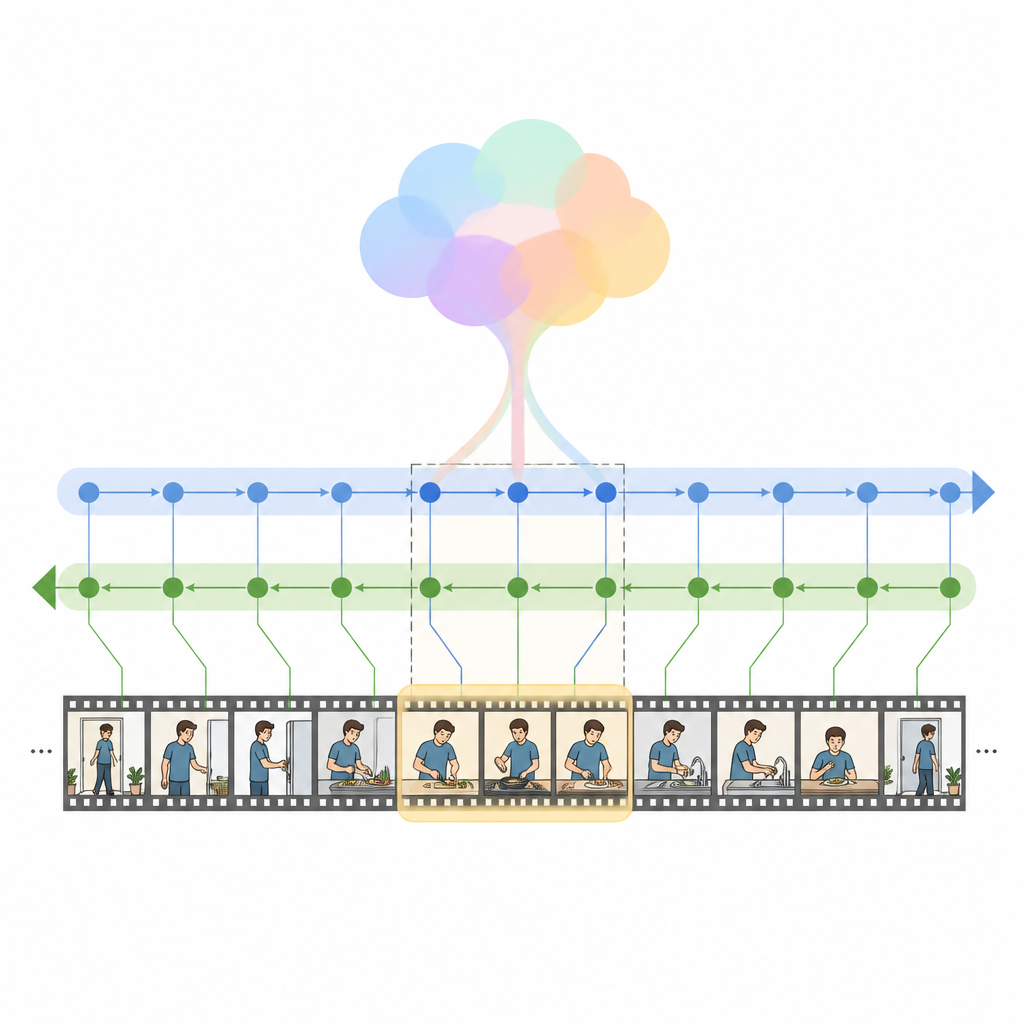
עדויות ממדריכי בישול וקליפים יומיומיים
הצוות בוחן את HM Net על שני מדדי־בוחן עיקריים: TACoS, שמכיל סרטוני בישול ארוכים ומפורטים, ו‑QVHighlights, אוסף של קליפים יומיומיים קצרים יותר עם שאילתות בסגנון היילייט. ב‑TACoS, שבו הסרטונים ארוכים והפעולות מתפתחות לאט, המודל החדש מפגין ביצועים עדיפים באופן ברור על פני השיטות המובילות הקודמות הן בדיוק והן באיכות הדירוג. הוא חזק במיוחד בשאילתות ארוכות או מורכבות שמתרחבות על פני דקות במקום שניות. ב‑QVHighlights, שבו רבים מהקליפים קצרים יותר, השיפורים קטנים יותר אך עקביים, מה שמעיד שהעיצוב ההיברידי מועיל גם כשהחשיבה הזמנית פחות תובענית. מחקרי אבֵלציה מאשרים שכל מרכיב — ליבת ממבה דו‑כיוונית, תשומת לב חוצת־מודאליות ושקילת הקשר גלובלי — תורם משמעותית לתוצאה הסופית.
מה זה אומר לגבי חיפוש וידאו יומיומי
באופן פשוט, המחקר מראה ששילוב התאמה מדויקת בין מילים למסגרות יחד עם תחושת זרימת הסיפור עוזר למחשבים להבין ולחפש סרטונים ארוכים בצורה טובה יותר. HM Net לא רק ננעץ במסגרות שנראות מתאימות, אלא גם עוקב אחר האופן שבו פעולות בונות ומתפוגגות עם הזמן. זאת מאפשרת לו לאתר אירועים ארוכים ורב־שלביים שאנשים באמת מעוניינים בהם, כגון הדגמה מלאה במדריך או רצף מפתח בולוג, ולהפוך פלטפורמות וידאו עתידיות לרגישות יותר לשאילתות בשפה טבעית.
ציטוט: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
מילות מפתח: משיכת רגעים בווידאו, למידה חוצת-מודאליות, מְודֵלִיזַצְיָה זמנית, מודלים של מרחב מצבים, הבנת וידאו