Clear Sky Science · fr
Modèle de fusion modulée basé sur Mamba pour la recherche de moments vidéo
Pourquoi il est important de trouver le bon moment dans une vidéo
Des tutoriels de cuisine aux ralentis sportifs, nous voulons souvent aller directement au moment précis d’une longue vidéo qui correspond à une courte description, par exemple « quand elle coupe les oignons » ou « le but final ». Le faire manuellement est lent et fatigant. Cet article présente une nouvelle méthode qui aide les ordinateurs à localiser rapidement la bonne période dans une vidéo à partir d’un langage naturel, même lorsque la vidéo est longue et que la description n’évoque qu’une partie de ce qui se passe.
Le défi de chercher à l’intérieur de longues vidéos
La recherche de moments vidéo consiste à trouver le segment temporel le plus pertinent dans une vidéo non tronquée qui correspond à une phrase donnée. Les systèmes antérieurs découpaient d’abord la vidéo en nombreux clips candidats puis tentaient de les classer par rapport au texte, ce qui rendait la précision très dépendante de la qualité de ces hypothèses initiales. Les modèles « de bout en bout » plus récents évitent ce processus en deux temps et prédisent directement les temps de début et de fin en utilisant des réseaux basés sur l’attention. Ces modèles alignent bien mots et images, mais ont encore du mal avec les longues vidéos où la compréhension de l’ordre et du déroulé des événements est cruciale, comme pour une recette en plusieurs étapes ou une action sportive complexe.
Pourquoi l’attention classique est insuffisante
Les modèles basés sur l’attention traitent la vidéo comme un sac de frames, permettant à n’importe quelle image de se connecter à n’importe quelle autre. Si cela est puissant pour repérer des correspondances visuelles, cela peut faire manquer la vision d’ensemble sur la façon dont les actions se déroulent dans le temps. Par exemple, une requête comme « Après avoir sorti la centrifugeuse, il presse la première moitié d’orange » ne mentionne que les étapes initiale et finale, alors que le véritable moment s’étend sur plusieurs actions intermédiaires. Les modèles standards peuvent se fixer sur les images les plus évidentes et ignorer les étapes cachées, conduisant à des prédictions incomplètes ou décalées. Certains travaux récents tentent de raccourcir les vidéos ou de regrouper les frames en événements de plus haut niveau, mais cela peut rompre la continuité naturelle de l’histoire et laisser le modèle avec une vision morcelée de la séquence complète.
Une nouvelle façon de fusionner texte et vidéo dans le temps
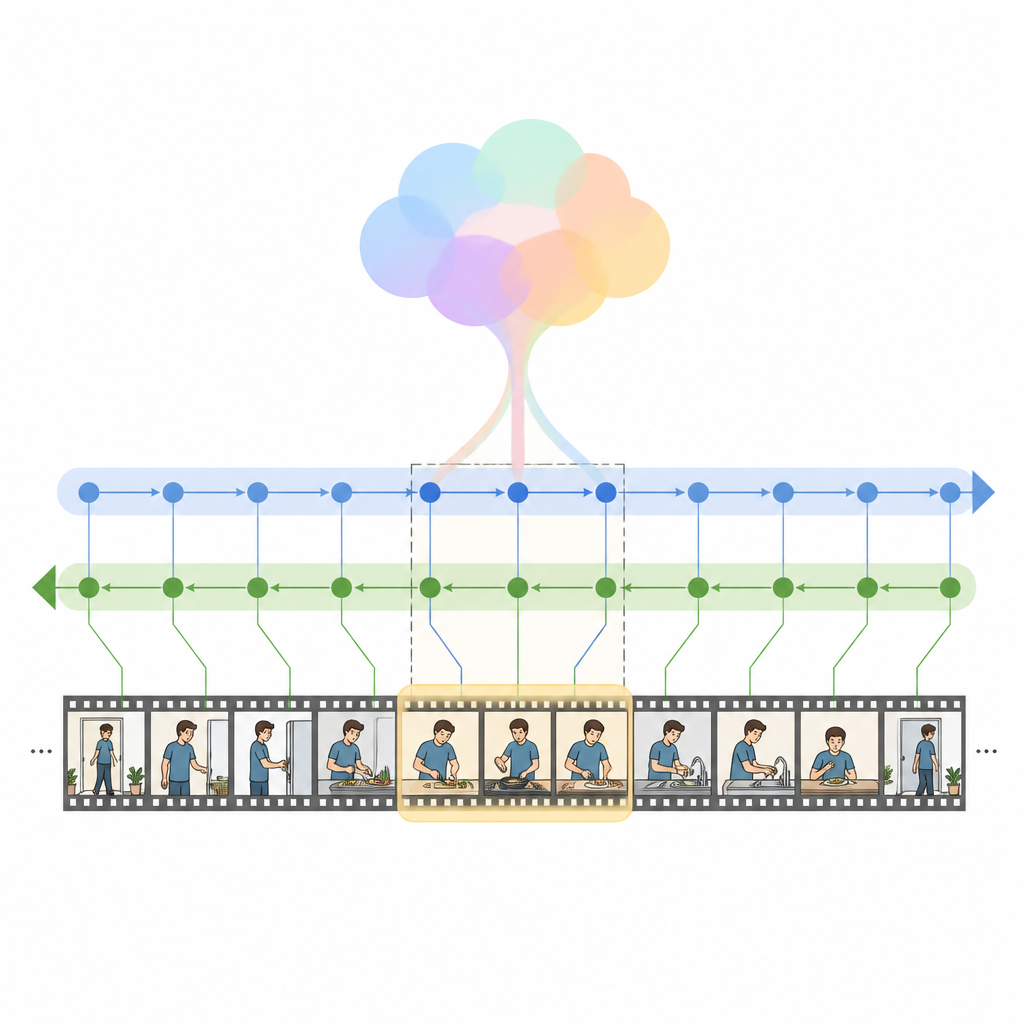
Les auteurs présentent HM Net, un Hybrid Mamba Network qui combine les forces de l’attention avec une classe plus récente de modèles de séquence appelés modèles d’espace d’état. Au cœur se trouve le bloc Hybrid Modulated Bi Mamba, qui commence par utiliser une attention croisée pour aligner chaque image vidéo avec les mots pertinents, puis fait passer cette information fusionnée dans un moteur temporel bidirectionnel qui lit la vidéo à la fois vers l’avant et vers l’arrière. Un résumé global de la requête guide ce processus, orientant le modèle vers l’intention générale plutôt que vers des mots isolés. Pour les clips courts, un signal positionnel supplémentaire aide le système à garder la trace de l’ordre, tandis que pour les clips longs le modèle s’appuie davantage sur son sens temporel appris.
Compréhension étape par étape de moments complexes
HM Net réalise la fusion en deux étapes. Dans la première étape, les caractéristiques vidéo sont enrichies par des indices issus du texte afin que chaque image « sache » quelles parties de la phrase importent le plus. Dans la seconde étape, la vidéo et le texte se raffinencent mutuellement de manière symétrique, créant une représentation partagée qui capture à la fois les détails fins et le contexte à longue portée. Un module de décodage final prédit ensuite quels segments de la chronologie correspondent le mieux à la requête. Le modèle est entraîné non seulement pour localiser les plages correctes, mais aussi pour distinguer les paires vidéo-texte correspondant de celles non correspondantes et pour reconstruire des descriptions de haut niveau à partir de segments, ce qui renforce le lien entre le langage et les événements visuels.
Preuves issues de vidéos de cuisine et de clips du quotidien
L’équipe teste HM Net sur deux grands benchmarks : TACoS, qui contient de longues vidéos de cuisine détaillées, et QVHighlights, une collection de clips du monde réel plus courts avec des requêtes de type highlights. Sur TACoS, où les vidéos sont longues et les actions se déploient lentement, le nouveau modèle surpasse nettement les méthodes précédentes en termes de précision et de qualité de classement. Il est particulièrement performant sur les requêtes très longues ou complexes qui s’étendent sur des minutes plutôt que des secondes. Sur QVHighlights, où de nombreux clips sont plus courts, les gains sont plus modestes mais constants, montrant que la conception hybride aide même lorsque le raisonnement temporel est moins exigeant. Des études d’ablation confirment que chaque ingrédient — le noyau Mamba bidirectionnel, l’attention croisée et le pool global de contexte — contribue de façon significative à la performance finale.
Ce que cela signifie pour la recherche vidéo quotidienne
En termes simples, cette recherche montre que l’association d’un appariement précis mot-image et d’un solide sens du déroulé narratif aide les ordinateurs à mieux comprendre et rechercher les longues vidéos. HM Net ne se contente pas de cibler les images qui paraissent pertinentes, il suit aussi la façon dont les actions s’enchaînent et s’achèvent dans le temps. Cela lui permet de trouver des événements longs et en plusieurs étapes qui intéressent réellement les utilisateurs, comme une démonstration complète dans un tutoriel ou la séquence clé d’un vlog, rendant les futures plateformes vidéo plus réactives aux requêtes en langage naturel.
Citation: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Mots-clés: recherche de moments vidéo, apprentissage cross-modal, modélisation temporelle, modèles d’espace d’état, compréhension vidéo