Clear Sky Science · ru
Моделируемая на Mamba модульная модель для поиска моментов в видео
Почему важно находить нужный момент в видео
От кулинарных уроков до повторов спортивных моментов — часто хочется сразу перейти к точному фрагменту в длинном видео, который соответствует короткому описанию, например «когда она режет лук» или «финальный гол». Делать это вручную медленно и утомительно. В этой статье предлагается новый метод, который помогает компьютерам быстро находить нужный отрезок времени в видео по естественному языку, даже если видео длинное, а описание даёт лишь часть подсказок о происходящем.
Проблема поиска внутри длинных видео
Video Moment Retrieval — задача нахождения наиболее релевантного временного сегмента в необработанном видео, соответствующего заданному предложению. Ранние системы сначала делили видео на множество кандидатов-клипов и затем ранжировали их относительно текста, из‑за чего точность сильно зависела от качества этих первоначальных предположений. Более новые «end-to-end» модели избегают этого двухэтапного процесса и напрямую предсказывают времена начала и конца с помощью основанных на attention сетей. Такие модели хорошо выравнивают слова и кадры, но всё ещё с трудом работают с длинными видео, где важно понимать порядок и ход событий — например, многоэтапный рецепт или сложная спортивная комбинация.
Почему обычный механизм attention недостаточен
Модели на основе attention рассматривают видео как набор кадров, позволяя любому кадру соединяться с любым другим. Хотя это мощно для обнаружения визуальных соответствий, такой подход может упустить общую картину развития действий во времени. Например, запрос «После того как достал соковыжималку, он выжимает первую половину апельсина» упоминает только первый и последний шаги, в то время как истинный момент охватывает несколько промежуточных действий. Стандартные модели могут зациклиться на самых очевидных кадрах и игнорировать скрытые шаги, что приводит к неполным или смещённым предсказаниям. Некоторые недавние подходы пытаются укоротить видео или сгруппировать кадры в более высокоуровневые события, но это может разрушить естественный сюжет и всё ещё оставляет модель с фрагментарным представлением последовательности.
Новый способ объединения текста и видео во времени
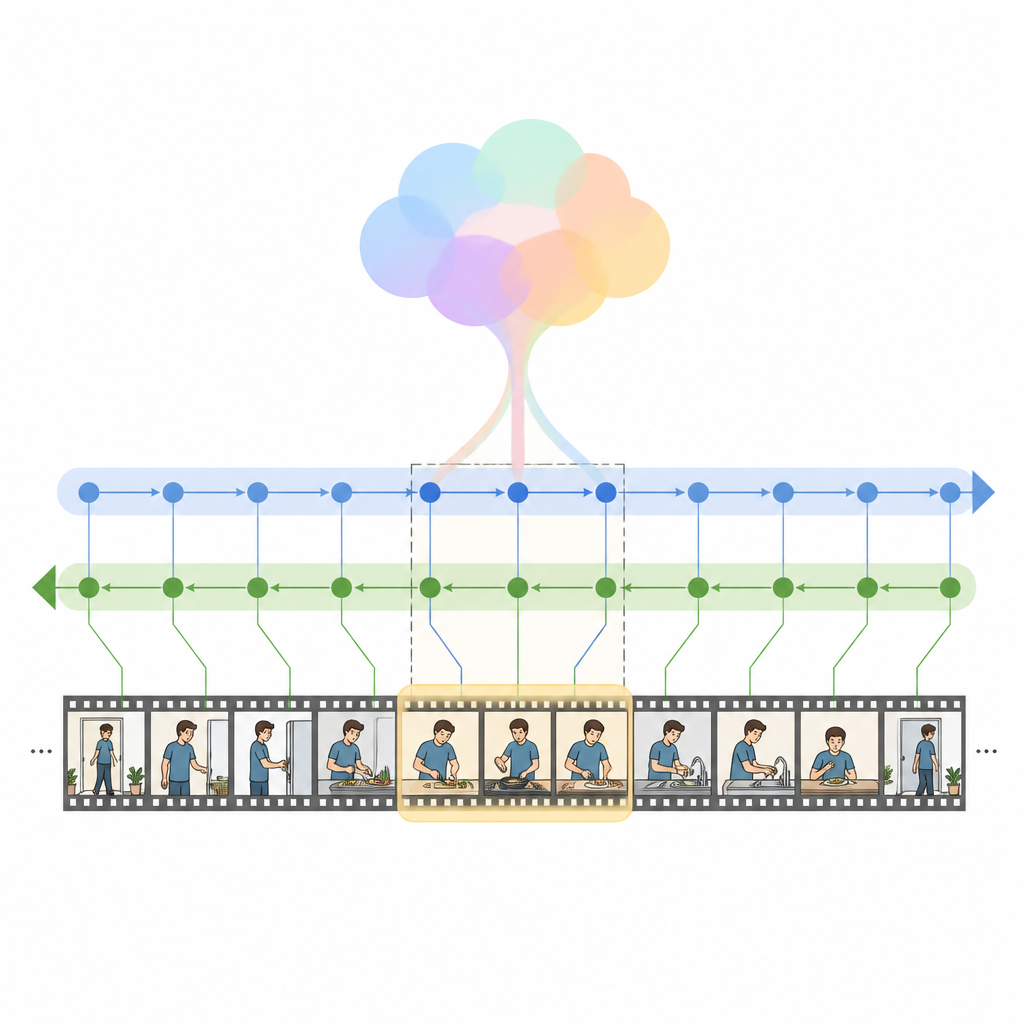
Авторы предлагают HM Net — Hybrid Mamba Network, которая сочетает сильные стороны attention с новым классом последовательностных моделей, называемых state space models. В центре стоит блок Hybrid Modulated Bi Mamba, который сначала использует кросс‑attention для выравнивания каждого видеокадра с релевантными словами, а затем пропускает это объединённое представление через двунаправленный временной движок, читающий видео вперёд и назад. Глобальное свёрнутое представление запроса направляет этот процесс, мягко направляя модель к общей интенции вместо изолированных слов. Для коротких клипов дополнительный позиционный сигнал помогает отслеживать порядок, а для длинных роликов модель больше полагается на выученную временную структуру.
Пошаговое понимание сложных моментов
HM Net выполняет объединение в два этапа. На первом этапе признаки видео обогащаются подсказками из текста, так что каждый кадр «знает», какие части предложения важны. На втором этапе видео и текст многократно уточняют друг друга симметрично, создавая общее представление, которое одновременно захватывает детальные признаки и дальний контекст. Финальный декодер затем предсказывает, какие сегменты временной шкалы лучше всего соответствуют запросу. Модель обучают не только локализовать правильные отрезки, но и отличать совпадающие пары видео‑текст от несовпадающих, а также восстанавливать более высокоуровневые описания из сегментов — это укрепляет связь между языком и визуальными событиями.
Доказательства на кулинарных и бытовых видеозаписях
Команда протестировала HM Net на двух основных бенчмарках: TACoS, содержащем длинные подробные кулинарные видео, и QVHighlights, наборе более коротких реальных клипов с запросами в стиле хайлайтов. На TACoS, где видео длительные и действия разворачиваются медленно, новая модель существенно превосходит предыдущие ведущие методы как по точности, так и по качеству ранжирования. Она особенно сильна на очень длинных или сложных запросах, охватывающих минуты, а не секунды. На QVHighlights, где многие клипы короче, приросты меньше, но устойчивы, что показывает: гибридная архитектура помогает даже когда временное рассуждение менее требовательно. Абляционные исследования подтверждают, что каждый компонент — двунаправленное ядро Mamba, кросс‑attention и глобальное пуллинг‑представление — вносит значимый вклад в итоговую производительность.
Что это значит для повседневного поиска по видео
Проще говоря, исследование показывает, что сочетание точного сопоставления слов и кадров с сильным чувством хода сюжета помогает компьютерам лучше понимать и искать в длинных видео. HM Net не только находит кадры, которые визуально соответствуют запросу, но и отслеживает, как действия накапливаются и затухают во времени. Это позволяет обнаруживать более длинные, многошаговые события, которые действительно важны людям — например, полную демонстрацию в уроке или ключевую последовательность в влоге — делая будущие видео‑платформы более отзывчивыми к запросам на естественном языке.
Цитирование: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Ключевые слова: поиск моментов в видео, кросс-модальное обучение, временное моделирование, модели состояния пространства, понимание видео