Clear Sky Science · tr
Video anı getirme için Mamba tabanlı modüle edilmiş füzyon modeli
Videoda doğru anı bulmanın önemi
Pişirme öğreticilerinden spor tekrarlarına kadar, genellikle “soğanları doğurduğu an” veya “son gol” gibi kısa bir tanımlamaya uyan uzun bir videoda doğrudan doğru anı atlamak isteriz. Bunu elle yapmak yavaş ve yorucudur. Bu makale, video uzun olsa ve açıklama olup bitenin sadece bir kısmına işaret etse bile, doğal dil temelinde bir videodaki doğru zaman aralığını bilgisayarların hızlıca bulmasına yardımcı olan yeni bir yöntem sunuyor.
Uzun videolar içinde aramanın zorluğu
Video Anı Getirme, işlenmemiş bir videoda verilen bir cümleyle en alakalı zaman segmentini bulma görevidir. Önceki sistemler videoyu birçok aday klibe bölüp bunları metinle sıralamaya çalışıyordu; bu da doğruluğun büyük ölçüde ilk tahminlerin kalitesine bağlı olmasına neden oldu. Yeni “uçtan uca” modeller bu iki aşamalı süreci ortadan kaldırıp dikkat tabanlı ağlarla doğrudan başlangıç ve bitiş zamanlarını tahmin ediyor. Bu yeni modeller kelimelerle kareleri iyi hizalıyor, ancak çok adımlı bir tarif veya karmaşık bir spor oyunu gibi olayların sırası ve akışının anlaşılmasının kritik olduğu uzun videolarda hâlâ zorlanıyorlar.
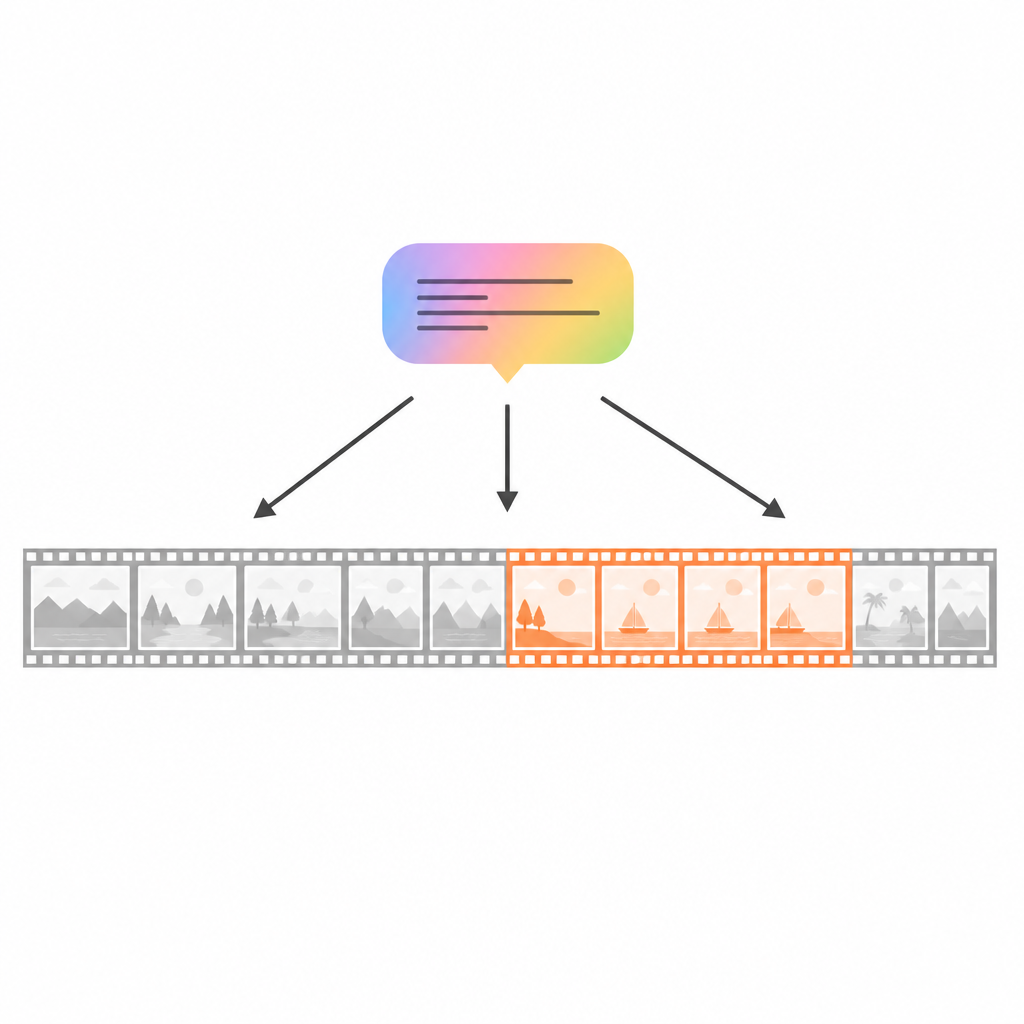
Neden sıradan dikkat yetersiz kalır
Dikkat tabanlı modeller bir videoyu kare torbası olarak ele alır; herhangi bir kare herhangi bir kareyle bağlanabilir. Bu, görsel eşleşmeleri yakalamada güçlü olsa da eylemlerin zaman içinde nasıl geliştiği konusundaki büyük resmi kaçırabilir. Örneğin, “Meyve sıkacağı çıkarıldıktan sonra, ilk portakal yarısını sıkıyor” gibi bir sorgu yalnızca ilk ve son adımlardan bahseder, oysa gerçek an aralarında birkaç küçük eylemi kapsar. Standart modeller en bariz karelere takılıp gizli adımları göz ardı edebilir, bu da eksik veya kaymış tahminlere yol açar. Bazı yeni çalışmalar videoları kısaltmaya veya kareleri daha yüksek düzeyli olaylarda gruplamaya çalışsa da bu, doğal hikâye akışını bozabilir ve modelin tüm diziyi bütünsel olarak görmesini engelleyebilir.
Metin ve videoyu zamana yayılarak birleştirmenin yeni yolu
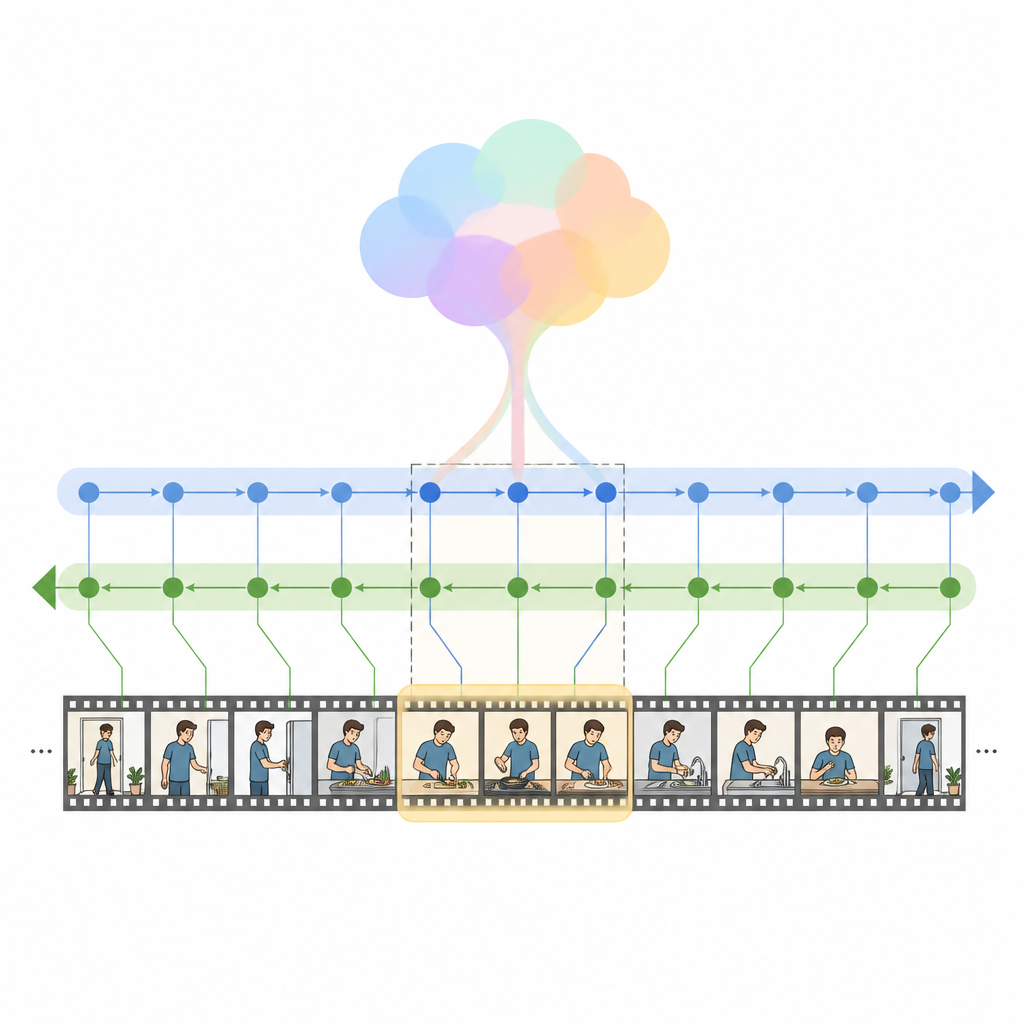
Yazarlar, dikkatin gücünü durum uzayı modelleri olarak adlandırılan daha yeni bir dizi model sınıfıyla birleştiren Hibrit Mamba Ağı HM Net’i tanıtıyor. Temelinde Hibrit Modüle Edilmiş Bi Mamba bloğu bulunuyor; bu blok önce çapraz dikkat kullanarak her video karesini ilgili kelimelerle hizalıyor, ardından bu birleşik bilgiyi videoyu hem ileri hem geri okuyan iki yönlü bir zamansal motor üzerinden geçiriyor. Sorgunun küresel bir özeti bu süreci yönlendiriyor ve modeli yalnızca izole kelimelere değil genel niyete doğru nazikçe çekiyor. Kısa klipler için ek bir konum sinyali sıralamayı takip etmeye yardımcı olurken, uzun kliplerde model daha çok öğrenilmiş zamansal yapı hissine dayanıyor.
Karmaşık anların adım adım anlaşılması
HM Net füzyonu iki aşamada gerçekleştirir. Birinci aşamada video özellikleri metinden gelen ipuçlarıyla zenginleştirilir, böylece her kare cümlenin hangi bölümlerinin en önemli olduğunu “bilir”. İkinci aşamada video ve metin birbirini simetrik bir şekilde tekrar tekrar rafine ederek ince ayrıntıları ve uzun menzilli bağlamı aynı anda yakalayan ortak bir temsil oluşturur. Son bir çözümleme modülü ise zaman çizelgesinin hangi segmentlerinin sorguyla en iyi örtüştüğünü tahmin eder. Model yalnızca doğru aralıkları bulmakla eğitilmez; eşleşen video-metin çiftlerini yanlış eşleşenlerden ayırt etmeyi ve segmentlerden daha yüksek düzeyli açıklamaları yeniden inşa etmeyi de öğrenir; bu da dil ile görsel olaylar arasındaki bağı güçlendirir.
Pişirme videoları ve günlük kliplerden kanıt
Araştırma ekibi HM Net’i iki önemli kıyas setinde test ediyor: uzun, ayrıntılı pişirme videolarını içeren TACoS ve öne çıkarma tarzı sorgulara sahip daha kısa, gerçek dünya kliplerinden oluşan QVHighlights. TACoS’ta videolar uzun ve eylemler yavaş geliştiği için yeni model doğruluk ve sıralama kalitesi açısından önceki önde gelen yöntemleri belirgin şekilde geride bırakıyor. Özellikle saniyeler yerine dakikalar süren çok uzun veya karmaşık sorgularda güçlü. QVHighlights’ta, birçok klibin daha kısa olduğu durumlarda kazanımlar daha küçük fakat yine de tutarlı; bu da hibrit tasarımın zamansal akıl yürütmenin daha az talep edildiği durumlarda bile fayda sağladığını gösteriyor. Ablasyon çalışmalarının her bir bileşenin — iki yönlü Mamba çekirdeği, çapraz dikkat ve küresel bağlam havuzlama — nihai performansa anlamlı katkıda bulunduğunu doğruluyor.
Günlük video araması için anlamı
Basitçe söylemek gerekirse, bu araştırma hassas kelime–kare eşleştirmesini güçlü bir hikâye akışı hissiyle eşleştirmenin bilgisayarların uzun videoları daha iyi anlamasına ve aramasına yardımcı olduğunu gösteriyor. HM Net yalnızca görünüşte doğru karelere kilitlenmekle kalmıyor, aynı zamanda eylemlerin zaman içinde nasıl birikip sona erdiğini de izliyor. Bu, öğreticide tam bir gösterim veya vlog’daki ana dizilim gibi insanların gerçekten önem verdiği daha uzun, çok adımlı olayları bulmasına olanak tanıyor ve gelecekteki video platformlarını doğal dil sorgularına karşı daha duyarlı hale getiriyor.
Atıf: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Anahtar kelimeler: video anı getirme, çapraz modal öğrenme, zamansal modelleme, durum uzayı modelleri, video anlama