Clear Sky Science · de
Mamba-basiertes moduliertes Fusionsmodell für Video-Moment-Retrieval
Warum es wichtig ist, den richtigen Moment im Video zu finden
Von Kochanleitungen bis zu Sport-Wiederholungen wollen wir oft direkt zu der exakten Stelle in einem langen Video springen, die zu einer kurzen Beschreibung passt, etwa „wenn sie die Zwiebeln hackt“ oder „das Tor in der Schlussphase“. Das manuell zu tun ist langsam und ermüdend. Dieses Paper stellt eine neue Methode vor, die Computern hilft, die passende Zeitspanne in einem Video schnell anhand natürlicher Sprache zu lokalisieren, selbst wenn das Video lang ist und die Beschreibung nur einen Teil dessen andeutet, was passiert.
Die Herausforderung beim Suchen in langen Videos
Video-Moment-Retrieval ist die Aufgabe, das relevanteste Zeitsegment in einem ungeschnittenen Video zu finden, das zu einem gegebenen Satz passt. Frühe Systeme teilten das Video zuerst in viele Kandidatenclips und versuchten dann, diese gegenüber dem Text zu ranken, wodurch die Genauigkeit stark von der Qualität dieser Vorab‑Vorschläge abhing. Neuere „End-to-End“-Modelle vermeiden diesen zweistufigen Prozess und sagen Start‑ und Endzeiten direkt mit auf Aufmerksamkeit basierenden Netzwerken voraus. Diese neueren Modelle stimmen Wörter und Frames zwar gut aufeinander ab, haben aber bei langen Videos Probleme, bei denen das Verständnis von Reihenfolge und Ablauf entscheidend ist — etwa bei mehrstufigen Rezepten oder komplexen Spielsituationen.
Warum herkömmliche Attention nicht ausreicht
Auf Attention basierende Modelle behandeln ein Video wie eine Menge von Frames, sodass sich jedes Frame mit jedem anderen verbinden kann. Das ist zwar mächtig, um visuelle Übereinstimmungen zu finden, kann aber das große Ganze darüber, wie Aktionen sich über die Zeit entfalten, verfehlen. Ein Query wie „Nachdem er den Entsafter herausgenommen hat, presst er die erste Orangenscheibe“ nennt etwa nur Anfang und Ende, obwohl der eigentliche Moment mehrere Zwischenschritte umfasst. Standardmodelle können sich an den offensichtlichsten Frames festhalten und die verborgenen Schritte ignorieren, was zu unvollständigen oder verschobenen Vorhersagen führt. Manche neueren Arbeiten versuchen, Videos zu verkürzen oder Frames in höhere Ereignisse zu gruppieren, doch das kann die natürliche Storyline zerstückeln und lässt dem Modell weiterhin nur einen lückenhaften Blick auf die gesamte Sequenz.
Eine neue Art, Text und Video über die Zeit zu verschmelzen
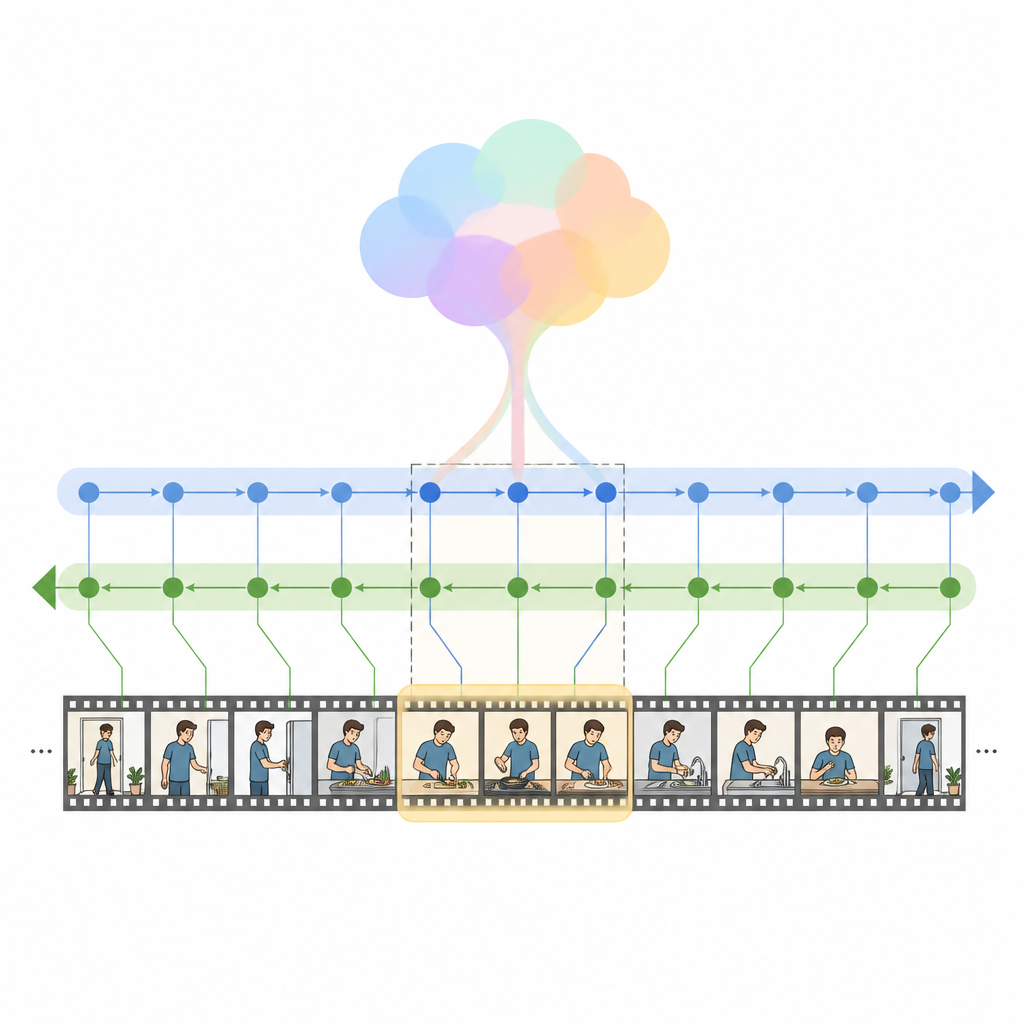
Die Autorinnen und Autoren führen HM Net ein, ein Hybrid Mamba Network, das die Stärken von Attention mit einer neueren Klasse von Sequenzmodellen kombiniert: Zustandsraum-Modellen. Im Kern steht der Hybrid Modulated Bi Mamba-Block, der zunächst Cross-Attention nutzt, um jedes Video-Frame mit den relevanten Wörtern abzugleichen, und diese verschmolzenen Informationen dann durch eine bidirektionale temporale Engine leitet, die das Video sowohl vorwärts als auch rückwärts liest. Eine globale Zusammenfassung der Abfrage lenkt diesen Prozess und steuert das Modell auf die Gesamtintention statt auf isolierte Wörter. Bei kürzeren Clips hilft ein zusätzlicher Positionshinweis, die Reihenfolge zu behalten, während das Modell bei langen Clips stärker auf sein erlerntes Gespür für zeitliche Struktur vertraut.
Schrittweises Verstehen komplexer Momente
HM Net führt die Fusion in zwei Stufen aus. In der ersten Stufe werden die Video-Features mit Hinweisen aus dem Text angereichert, sodass jedes Frame „weiß“, welche Teile des Satzes am wichtigsten sind. In der zweiten Stufe verfeinern sich Video und Text wechselseitig und symmetrisch, wodurch eine gemeinsame Repräsentation entsteht, die zugleich feine Details und langfristigen Kontext erfasst. Ein abschließendes Decodier‑Modul sagt dann voraus, welche Abschnitte der Zeitachse am besten zur Abfrage passen. Das Modell wird nicht nur darauf trainiert, die korrekten Zeitspannen zu lokalisieren, sondern auch passende Video‑Text‑Paare von nicht passenden zu unterscheiden und aus Segmenten höherstufige Beschreibungen wiederherzustellen, was die Verbindung zwischen Sprache und visuellen Ereignissen stärkt.
Belege aus Kochvideos und Alltagsclips
Das Team testet HM Net auf zwei wichtigen Benchmarks: TACoS, das lange, detaillierte Kochvideos enthält, und QVHighlights, eine Sammlung kürzerer Alltagsclips mit Highlight‑artigen Abfragen. Auf TACoS, wo Videos lang sind und Aktionen sich langsam entfalten, übertrifft das neue Modell frühere Spitzenmethoden deutlich sowohl in Genauigkeit als auch in Ranking‑Qualität. Besonders stark ist es bei sehr langen oder komplexen Abfragen, die Minuten statt Sekunden umfassen. Auf QVHighlights, wo viele Clips kürzer sind, sind die Verbesserungen kleiner, aber konsistent, was zeigt, dass das hybride Design auch dann hilft, wenn die zeitliche Argumentation weniger gefordert ist. Ablationsstudien bestätigen, dass jede Komponente — der bidirektionale Mamba‑Kern, Cross‑Attention und globales Kontext‑Pooling — maßgeblich zur Endleistung beiträgt.
Was das für die alltägliche Videosuche bedeutet
Kurz gesagt zeigt diese Forschung, dass die Kombination aus präziser Wort‑Frame‑Zuordnung und einem starken Gespür für Handlungsverlauf Computern hilft, lange Videos besser zu verstehen und zu durchsuchen. HM Net fixiert sich nicht nur auf die optisch passenden Frames, sondern verfolgt auch, wie sich Aktionen über die Zeit aufbauen und abklingen. So kann es längere, mehrstufige Ereignisse finden, die für Menschen relevant sind — etwa eine vollständige Demonstration in einem Tutorial oder die entscheidende Sequenz in einem Vlog — und macht künftige Videoplattformen reaktionsfähiger gegenüber natürlichsprachlichen Anfragen.
Zitation: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Schlüsselwörter: Video-Moment-Retrieval, crossmodales Lernen, temporale Modellierung, Zustandsraum-Modelle, Videoverstehen