Clear Sky Science · pl
Model fuzji modulowanej oparty na Mamba do wyszukiwania momentów w wideo
Dlaczego odnajdywanie właściwego momentu w wideo ma znaczenie
Od tutoriali kulinarnych po powtórki sportowe — często chcemy od razu przejść do dokładnego momentu w długim wideo, który odpowiada krótkiemu opisowi, np. „gdy sieka cebulę” lub „ostatni gol”. Robienie tego ręcznie jest wolne i męczące. Niniejszy artykuł przedstawia nową metodę, która pomaga komputerom szybko zlokalizować właściwy fragment czasu w wideo na podstawie języka naturalnego, nawet gdy wideo jest długie, a opis jedynie sugeruje część zdarzeń.
Wyzwanie przeszukiwania długich wideo
Video Moment Retrieval to zadanie polegające na znalezieniu najbardziej odpowiedniego segmentu czasowego w nieprzyciętym wideo, który pasuje do podanego zdania. Wcześniejsze systemy najpierw dzieliły wideo na wiele kandydackich klipów, a potem próbowały je ocenić względem tekstu, przez co jakość zależała mocno od tych początkowych podziałów. Nowsze modele „end-to-end” unikają tego dwustopniowego procesu i bezpośrednio przewidują czasy rozpoczęcia i zakończenia przy użyciu sieci opartych na mechanizmie attention. Te nowsze modele dobrze dopasowują słowa do klatek, ale nadal mają trudności z długimi wideo, gdzie zrozumienie kolejności i przebiegu zdarzeń jest kluczowe — na przykład przy wieloetapowej recepturze czy skomplikowanej akcji sportowej.
Dlaczego standardowy attention nie wystarcza
Modele oparte na attention traktują wideo jako worek klatek, pozwalając, by każda klatka łączyła się z dowolną inną. Choć to potężne do wykrywania wizualnych dopasowań, może przeoczyć szerszy obraz, jak działania rozwijają się w czasie. Na przykład zapytanie „Po wyjęciu wyciskarki, wyciska pierwszą połówkę pomarańczy” wspomina tylko pierwszy i ostatni krok, podczas gdy prawdziwy moment obejmuje kilka mniejszych działań między nimi. Standardowe modele mogą skupić się na najbardziej oczywistych klatkach i zignorować ukryte kroki, prowadząc do niepełnych lub przesuniętych predykcji. Niektóre ostatnie prace próbują skrócić wideo lub grupować klatki w wyższe poziomy zdarzeń, ale może to zerwać naturalną narrację i dalej pozostawia model z fragmentarycznym widokiem całej sekwencji.
Nowy sposób łączenia tekstu i obrazu w czasie
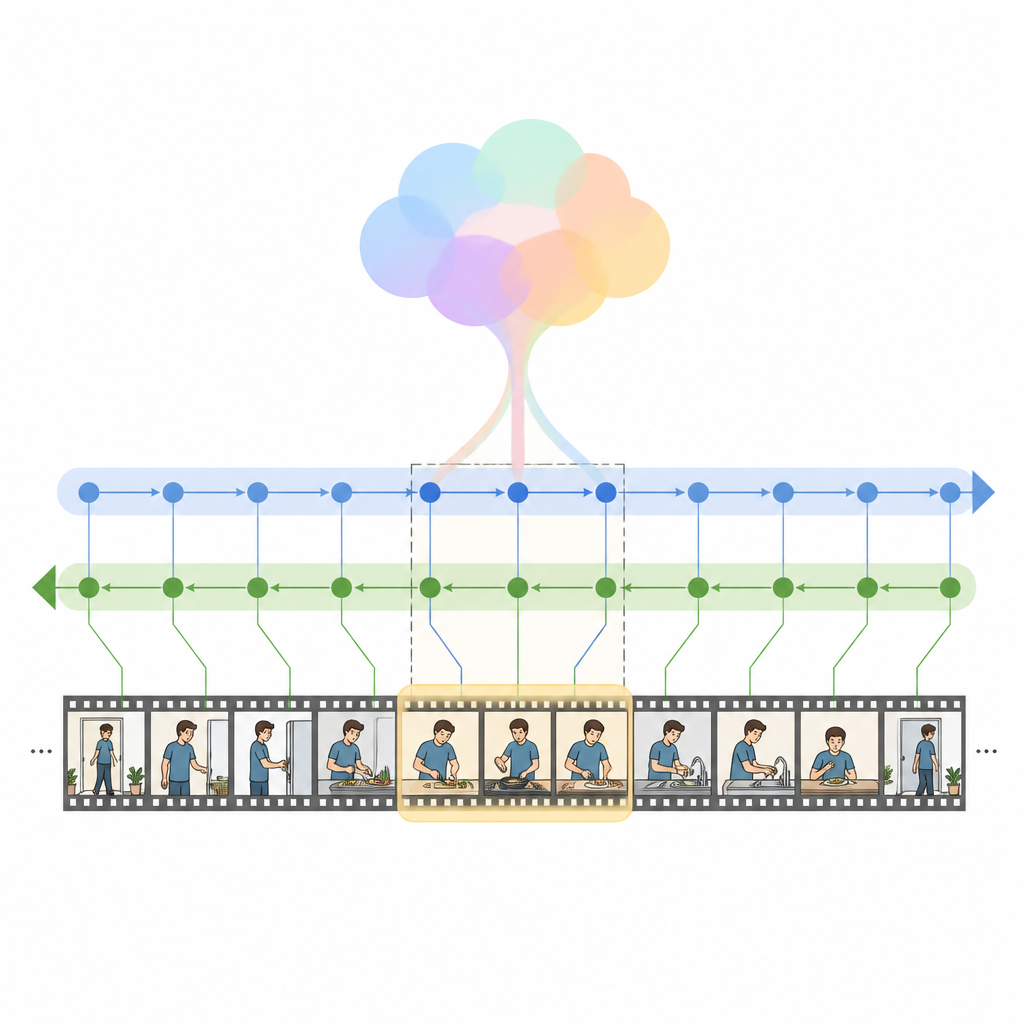
Autorzy wprowadzają HM Net, Hybrid Mamba Network, który łączy moc attention z nowszą klasą modeli sekwencyjnych zwanych modelami przestrzeni stanów. W jego rdzeniu znajduje się blok Hybrid Modulated Bi Mamba, który najpierw używa cross-attention, aby wyrównać każdą klatkę wideo z odpowiednimi słowami, a następnie przepuszcza tę sformatowaną informację przez dwukierunkowy silnik czasowy czytający wideo zarówno do przodu, jak i do tyłu. Globalne streszczenie zapytania kieruje tym procesem, delikatnie nakierowując model na ogólny zamiar zamiast tylko izolowanych słów. Dla krótszych klipów dodatkowy sygnał pozycyjny pomaga systemowi śledzić porządek, podczas gdy dla długich klipów model bardziej polega na wyuczonym zrozumieniu struktury czasowej.
Krok po kroku: zrozumienie złożonych momentów
HM Net wykonuje fuzję w dwóch etapach. W pierwszym etapie cechy wideo są wzbogacane o wskazówki z tekstu, tak że każda klatka „wie”, które części zdania są najważniejsze. W drugim etapie wideo i tekst wielokrotnie się wzajemnie dopracowują w symetryczny sposób, tworząc wspólną reprezentację, która jednocześnie uchwyca szczegóły i długodystansowy kontekst. Końcowy moduł dekodujący przewiduje następnie, które segmenty osi czasu najlepiej pasują do zapytania. Model jest trenowany nie tylko do lokalizowania poprawnych przedziałów, ale też do odróżniania pasujących par wideo-tekst od niepasujących oraz do odtwarzania opisów wyższego poziomu z segmentów, co pomaga wzmocnić powiązanie między językiem a zdarzeniami wizualnymi.
Dowody na przykładzie filmów kulinarnych i codziennych klipów
Zespół testuje HM Net na dwóch ważnych benchmarkach: TACoS, zawierającym długie, szczegółowe filmy kulinarne, oraz QVHighlights, zbiorze krótszych, rzeczywistych klipów z zapytaniami w stylu highlightów. Na TACoS, gdzie filmy są obszerne, a akcje rozwijają się powoli, nowy model wyraźnie przewyższa wcześniejsze czołowe metody zarówno pod względem dokładności, jak i jakości rankingów. Jest szczególnie silny przy bardzo długich lub złożonych zapytaniach, obejmujących minuty, a nie sekundy. Na QVHighlights, gdzie wiele klipów jest krótszych, zyski są mniejsze, lecz nadal spójne, co pokazuje, że hybrydowa konstrukcja pomaga nawet tam, gdzie rozumowanie czasowe jest mniej wymagające. Badania ablacyjne potwierdzają, że każdy składnik — dwukierunkowe jądro Mamba, cross-attention i globalne poolowanie kontekstu — wnosi istotny wkład do końcowej wydajności.
Co to oznacza dla codziennego wyszukiwania wideo
Mówiąc prościej, badanie to pokazuje, że połączenie precyzyjnego dopasowania słów do klatek z silnym wyczuciem przebiegu historii pomaga komputerom lepiej rozumieć i przeszukiwać długie wideo. HM Net nie tylko odnajduje klatki, które wyglądają odpowiednio, ale też śledzi, jak akcje narastają i wygasają w czasie. Dzięki temu potrafi znaleźć dłuższe, wieloetapowe zdarzenia, które rzeczywiście interesują ludzi — jak pełna demonstracja w tutorialu czy kluczowa sekwencja w vlogu — sprawiając, że przyszłe platformy wideo będą bardziej responsywne na zapytania w języku naturalnym.
Cytowanie: Yu, B., Li, J., Di, Y. et al. Mamba-based modulated fusion model for video moment retrieval. Sci Rep 16, 15847 (2026). https://doi.org/10.1038/s41598-026-44804-x
Słowa kluczowe: wyszukiwanie momentów w wideo, uczenie krzyżowo-modalne, modelowanie czasowe, modele przestrzeni stanów, rozumienie wideo