Clear Sky Science · zh
用于具有动态语义对齐的鲁棒多模态融合的自适应图信号处理
为何结合视觉、声音与文字至关重要
当今数字世界中大量内容由视频、音频和文本的丰富混合构成——从带字幕的电影预告片到配有评论的社交媒体短片。教会计算机理解这种错综复杂的混合信息,对识别对话中的情感、检测视频中的事件或推荐电影等任务至关重要。但真实数据往往很混乱:有时音频缺失,图像有噪声,文本含糊不清。本文提出了一种新方法,使计算机能够灵活地结合不同类型的信息,即便某些信息不可靠或缺失,也能仍然理解发生了什么。
把混合媒体转化为相互连接的点
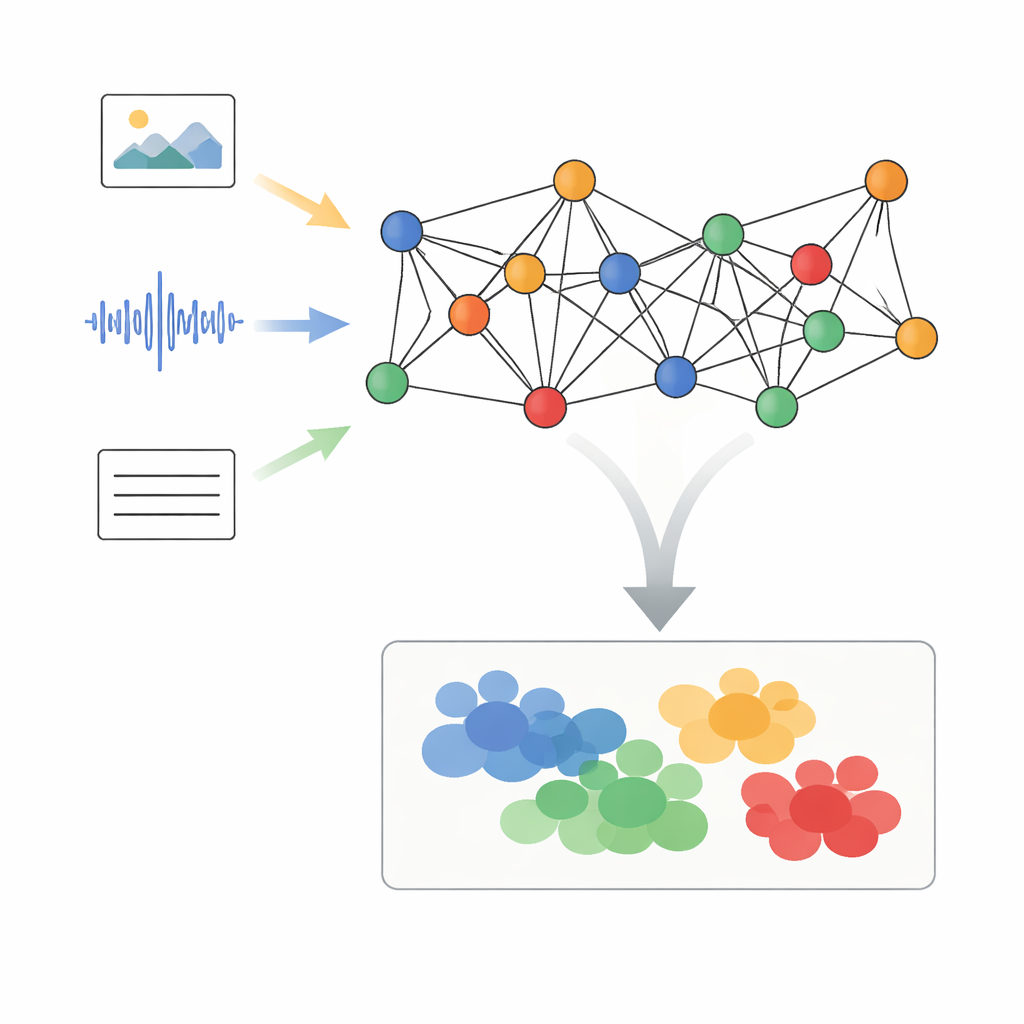
作者提出了一个名为“具有动态语义对齐的自适应图信号处理”(Adaptive Graph Signal Processing with Dynamic Semantic Alignment,简称 AGSP-DSA)的框架,将每一条数据视为网络的一部分。首先,利用现有的强大工具从每种模态中提取特征:图像网络处理视觉信息,音频网络概括声音,语言模型处理文本。不再简单地将这些特征堆叠在一起,AGSP-DSA 将它们作为节点安排在两个相关的图中。一个图连接同一模态内相似的样本——例如外观相似的视频片段;另一个图连接跨模态具有相同语义的样本,比如听起来悲伤的声音与阴郁的面部表情。这样的双图视角让系统既能把握每种数据类型内部的结构,也能管理跨模态的关系。
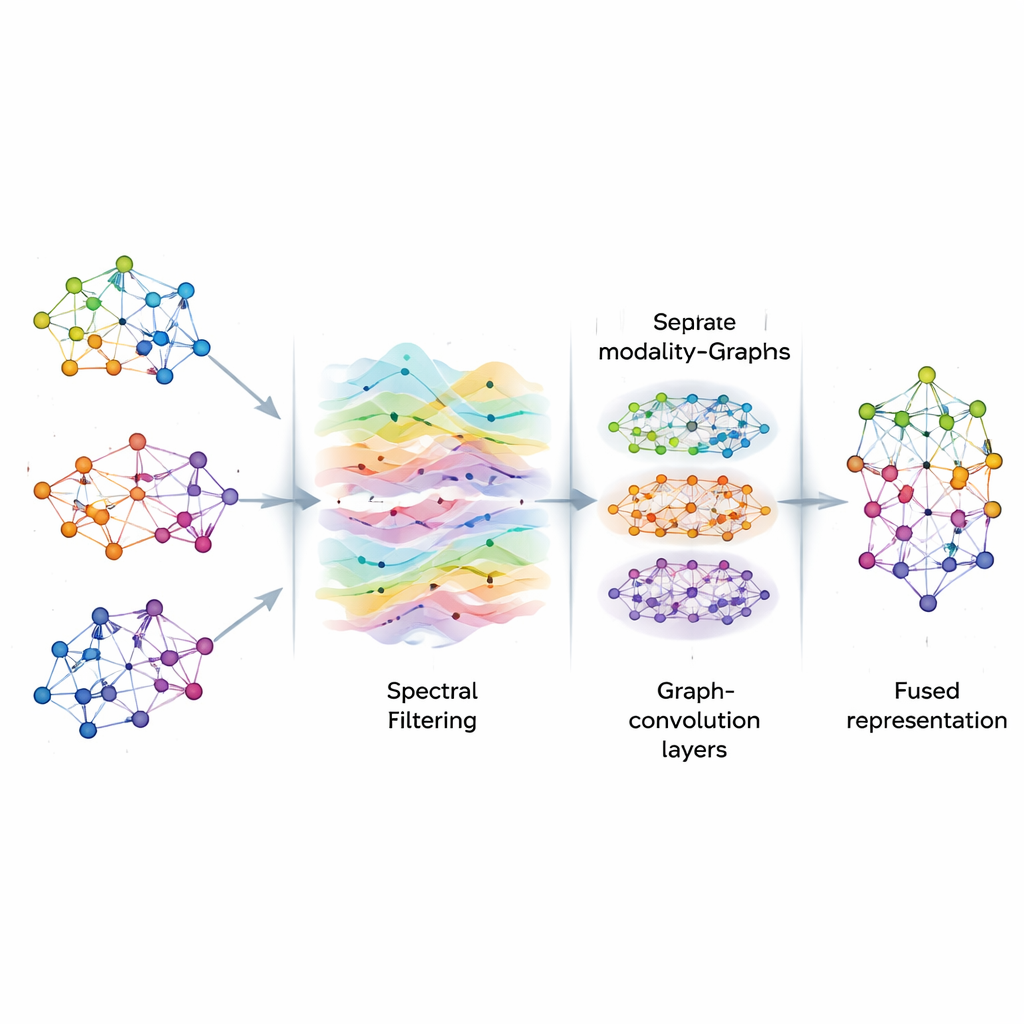
在图上清理信号
一旦图构建完成,AGSP-DSA 将其上的信息视为在网络中流动的信号,类似于声波在空气中的传播。利用图信号处理的工具,它进行一种智能滤波,强调有用模式同时减少噪声。该方法并不直接计算昂贵的矩阵运算,而是使用基于切比雪夫多项式的数学近似来逼近信号在图上应如何平滑。这个过程帮助模型专注于样本之间一致且有意义的连接——例如不同片段中重复出现的情感线索——而不被随机波动或缺失数据干扰。
在多尺度上学习模式
滤波之后,AGSP-DSA 将图信号输入到一系列图卷积网络(Graph Convolutional Networks)中,这类网络专为图形数据设计。每一层允许一个节点通过融合来自邻居的信息来更新其表示,先从近邻点开始,随后逐步涵盖更远的节点。通过堆叠多层,系统能学习到多尺度的模式:本地细节如语调的微妙变化,以及跨越许多样本的更广泛趋势。来自模态内图与跨模态图的输出被组合,生成编码了图像、声音与文字之间细粒度与全局关系的丰富表征。
让数据决定哪个模态最重要
多模态学习的一个关键挑战是并非所有来源在任何时候都同样有用。有时面部表情传递主要信息;有时语气或文本占主导。AGSP-DSA 通过语义感知注意力机制来应对这一点。对于每个样本,它将各模态的特征与语义锚(例如目标标签或意义摘要)进行比较,并分配一个权重,反映该模态在特定语境下的信息量。随后通过门控步骤进一步调整这些贡献,使系统能够弱化不可靠或缺失的信号。融合后、经注意力加权的表示被送入最终的预测层,可用于情感分类、事件识别或电影类型标注等任务。
在真实世界中的表现
该框架在三个具有挑战性的基准数据集上进行了测试:用于情感与情绪分析的大型观点视频集(CMU-MOSEI)、视听事件数据集(AVE)以及结合海报与剧情简介的电影集合(MM-IMDb)。在所有这些数据集上,AGSP-DSA 的表现都优于传统的融合方法以及基于变换器和图的方法的现代竞争者。在情感分类上准确率超过95%,在事件检测和电影类型预测上也取得了类似的显著提升。重要的是,该方法在部分模态缺失或噪声存在的情况下仍保持鲁棒性,且不会带来过高的计算代价。多次实验表明其性能稳定,不依赖训练过程中的偶然随机性。
对日常 AI 系统的意义
通俗地说,AGSP-DSA 为 AI 系统提供了一种更智能的同时“听、看、读”的方式,并在其中一条通道失效时保持韧性。通过将多模态数据表征为相互连接的图、清理流经其中的信号,并让模型动态决定信任哪个模态,该方法能够做出更准确、更可靠的决策。这使其成为未来应用的有希望的构建模块,例如具有情感感知能力的虚拟助理、鲁棒的视频监控、更丰富的内容推荐,以及其他需理解复杂、不完美多媒体流的系统。
引用: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
关键词: 多模态融合, 图神经网络, 情感分析, 视听事件, 多媒体分类