Clear Sky Science · en
Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment
Why combining sights, sounds, and words matters
Much of today’s digital world is made of rich mixtures of video, audio, and text—from movie trailers with subtitles to social media clips with comments. Teaching computers to make sense of this tangled mix is crucial for tasks like recognizing emotions in conversations, detecting events in videos, or recommending movies. But real data are messy: sometimes audio is missing, images are noisy, or text is vague. This paper presents a new way to let computers flexibly combine different types of information so they can still understand what is going on even when some pieces are unreliable or absent.
Turning mixed media into connected points
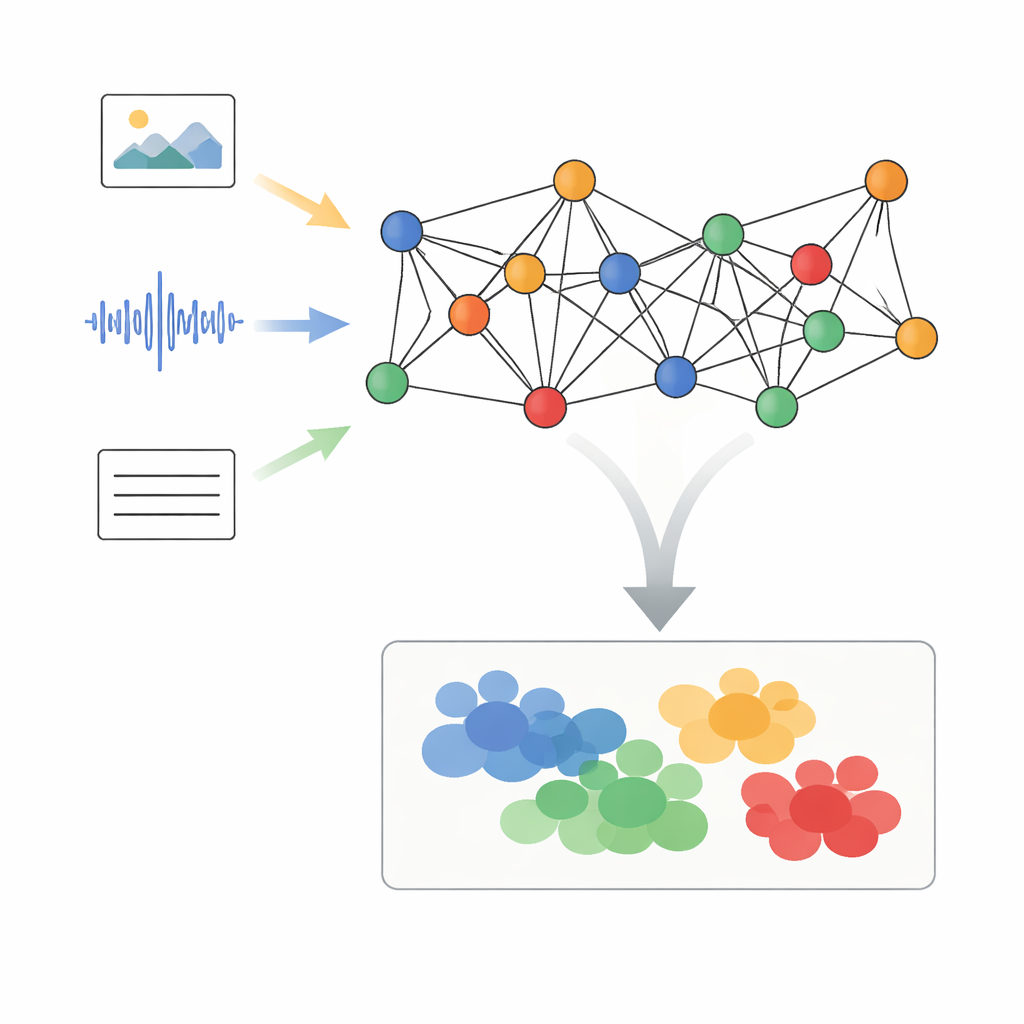
The authors propose a framework called Adaptive Graph Signal Processing with Dynamic Semantic Alignment, or AGSP-DSA, that treats each piece of data as part of a network. First, powerful existing tools extract features from each modality: image networks digest visuals, audio networks summarize sounds, and language models process text. Instead of simply stacking these features together, AGSP-DSA arranges them as nodes in two related graphs. One graph connects samples that are similar within the same modality—for example, video clips that look alike. The other graph links samples across modalities that share meaning, such as a sad-sounding voice paired with a gloomy facial expression. This dual-graph view lets the system keep track of both the structure inside each data type and the relationships that span across them.
Cleaning up signals on the graph
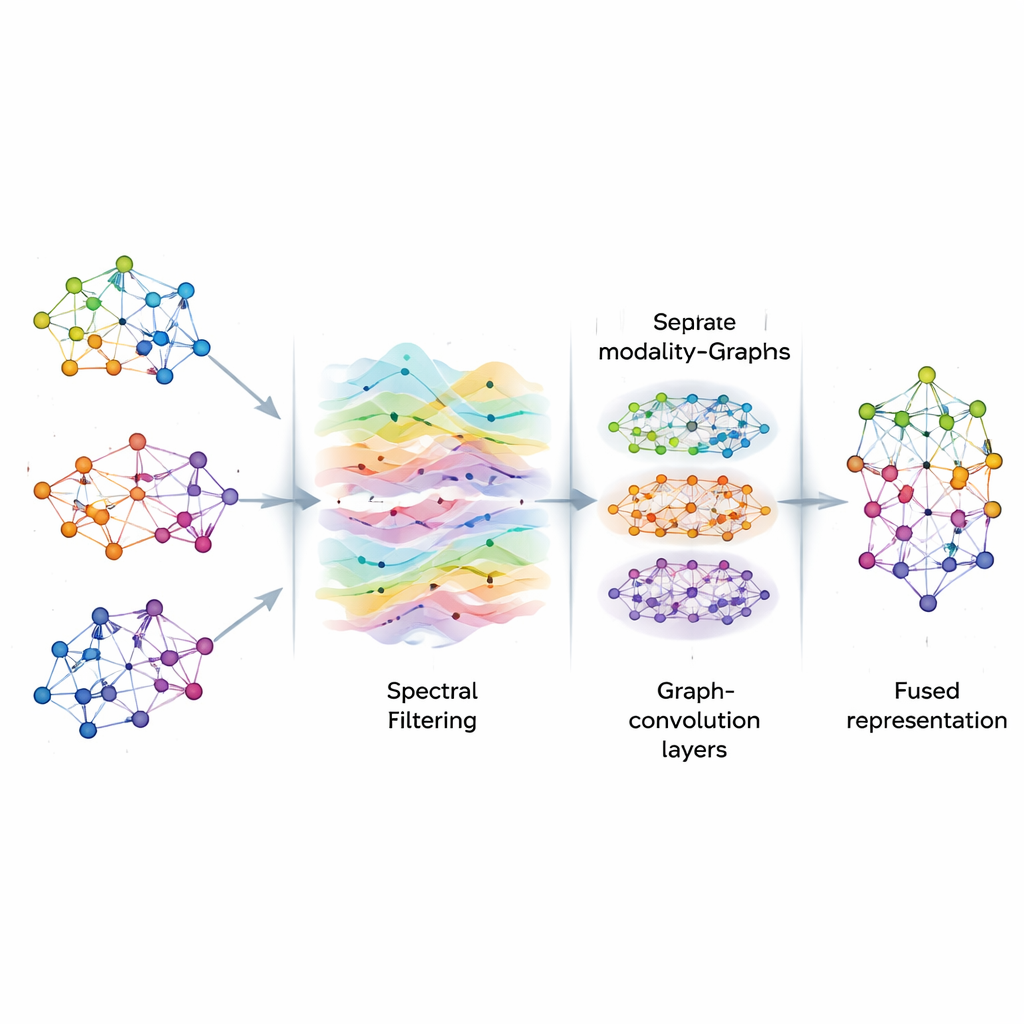
Once the graphs are built, AGSP-DSA treats the information on them like signals flowing through a network, similar to how sound waves move through the air. Using tools from graph signal processing, it performs a kind of smart filtering, emphasizing useful patterns while reducing noise. Instead of directly computing expensive matrix operations, the method uses mathematical shortcuts based on Chebyshev polynomials to approximate how signals should be smoothed on the graph. This process helps the model focus on consistent, meaningful connections between samples—such as repeated emotional cues across different clips—without being distracted by random fluctuations or missing data.
Learning patterns at multiple scales
After filtering, AGSP-DSA feeds the graph signals into a stack of Graph Convolutional Networks, which are specialized neural networks designed for graph-shaped data. Each layer lets a node update its representation by blending information from its neighbors, first from nearby points and then gradually from more distant ones. By stacking several layers, the system learns patterns at multiple scales: local details like subtle changes in tone, as well as broader trends spanning many samples. The outputs from the graph that lives within each modality and the graph that ties modalities together are combined, producing rich representations that encode both fine-grained and global relationships among images, sounds, and words.
Letting the data decide which modality matters most
A key challenge in multimodal learning is that not every source is equally useful all the time. Sometimes facial expressions carry the message; other times, tone of voice or text dominates. AGSP-DSA addresses this with a semantic-aware attention mechanism. For each sample, it compares the features from each modality against a semantic anchor, such as the target label or a summary of meaning, and assigns a weight that reflects how informative that modality is in context. A gating step then further adjusts these contributions, allowing the system to downplay unreliable or missing signals. The fused, attention-weighted representation is fed to a final prediction layer that can handle tasks like sentiment classification, event recognition, or movie genre tagging.
Performance in the real world
The framework is tested on three demanding benchmark datasets: a large collection of opinion videos for sentiment and emotion analysis (CMU-MOSEI), an audio-visual event dataset (AVE), and a movie collection that combines posters and plot summaries (MM-IMDb). Across all of them, AGSP-DSA outperforms both traditional fusion methods and modern transformer-based and graph-based competitors. It reaches over 95% accuracy on sentiment classification, and similarly strong gains for event detection and movie genre prediction. Importantly, the method remains robust when some modalities are partially missing or noisy, and does so without incurring prohibitive computational cost. Repeated experiments show that its performance is stable and does not hinge on lucky random choices during training.
What this means for everyday AI systems
In everyday terms, AGSP-DSA offers a smarter way for AI systems to listen, watch, and read at the same time, while staying resilient when one of those channels fails. By representing multimodal data as interconnected graphs, cleaning the signals that flow through them, and letting the model dynamically decide which modality to trust, the approach delivers more accurate and reliable decisions. This makes it a promising building block for future applications such as emotion-aware virtual assistants, robust video surveillance, richer content recommendation, and other systems that must make sense of complex, imperfect multimedia streams.
Citation: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Keywords: multimodal fusion, graph neural networks, sentiment analysis, audio-visual events, multimedia classification