Clear Sky Science · it
Elaborazione adattativa di segnali su grafo per una fusione multimodale robusta con allineamento semantico dinamico
Perché combinare immagini, suoni e parole è importante
Gran parte del mondo digitale di oggi è fatta di miscele ricche di video, audio e testo — dai trailer con sottotitoli ai clip dei social con commenti. Insegnare ai computer a interpretare questo intreccio è cruciale per compiti come riconoscere emozioni nelle conversazioni, rilevare eventi nei video o suggerire film. Ma i dati reali sono disordinati: a volte l’audio manca, le immagini sono rumorose o il testo è vago. Questo articolo presenta un nuovo modo per permettere ai computer di combinare in modo flessibile diversi tipi di informazione, così da comprendere comunque cosa sta accadendo anche quando alcune parti sono inaffidabili o assenti.
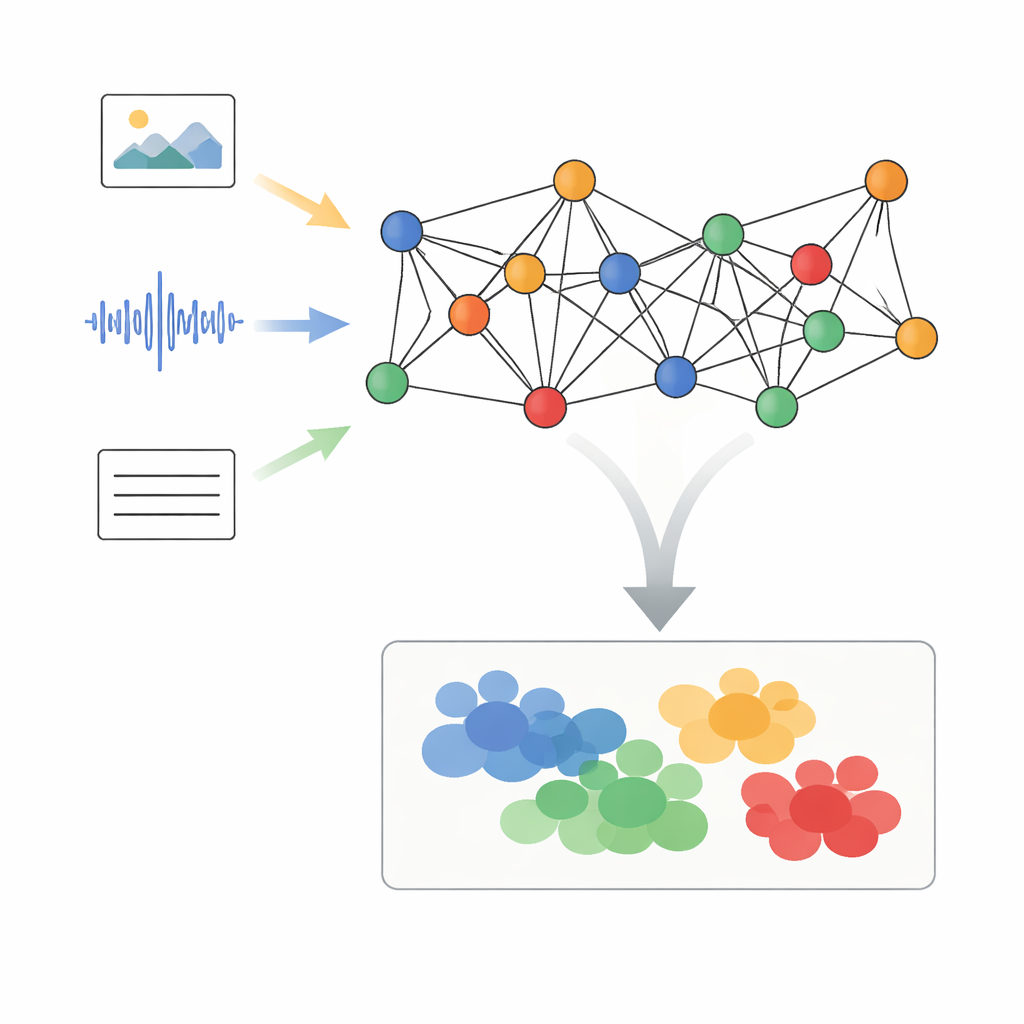
Trasformare i media misti in punti connessi
Gli autori propongono un framework chiamato Elaborazione Adattativa di Segnali su Grafo con Allineamento Semantico Dinamico, o AGSP-DSA, che tratta ogni elemento di dati come parte di una rete. Innanzitutto, potenti strumenti esistenti estraggono caratteristiche da ciascuna modalità: reti per le immagini elaborano il visivo, reti per l’audio sintetizzano i suoni e modelli linguistici processano il testo. Invece di limitarsi ad accodare queste caratteristiche, AGSP-DSA le dispone come nodi in due grafi correlati. Un grafo connette campioni simili all’interno della stessa modalità — per esempio clip video che si assomigliano. L’altro grafo collega campioni attraverso le modalità che condividono significato, come una voce dal tono triste associata a un’espressione facciale cupa. Questa visione a doppio grafo permette al sistema di tenere traccia sia della struttura interna a ciascun tipo di dato sia delle relazioni che le attraversano.
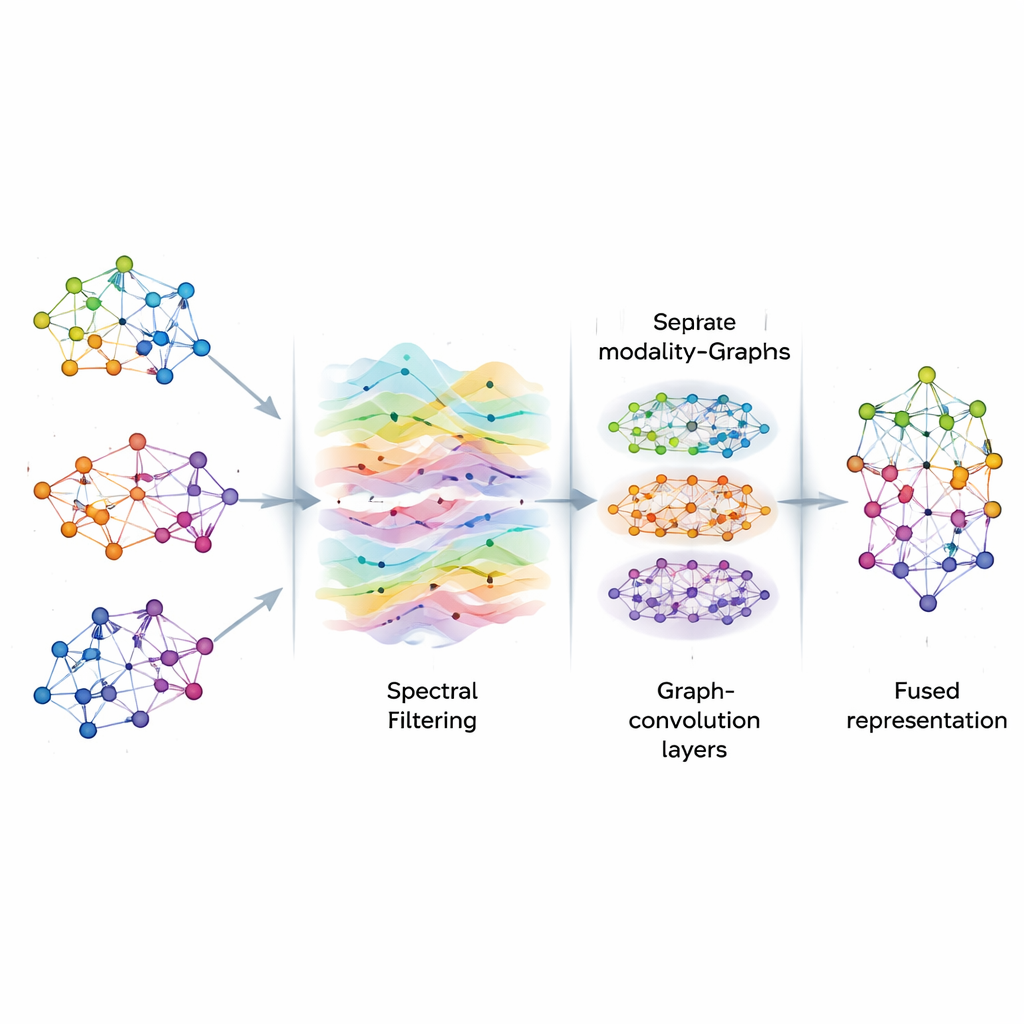
Pulire i segnali sul grafo
Una volta costruiti i grafi, AGSP-DSA tratta le informazioni su di essi come segnali che scorrono attraverso una rete, in modo analogo a come le onde sonore si propagano nell’aria. Usando strumenti dell’elaborazione di segnali su grafo, esegue una sorta di filtraggio intelligente, enfatizzando pattern utili e riducendo il rumore. Invece di calcolare direttamente costose operazioni matriciali, il metodo usa scorciatoie matematiche basate sui polinomi di Chebyshev per approssimare come i segnali dovrebbero essere levigati sul grafo. Questo processo aiuta il modello a concentrarsi su connessioni coerenti e significative tra i campioni — come indizi emotivi ripetuti attraverso diversi clip — senza lasciarsi distrarre da fluttuazioni casuali o dati mancanti.
Apprendere pattern a più scale
Dopo il filtraggio, AGSP-DSA alimenta i segnali del grafo in una pila di Reti Convoluzionali su Grafo (Graph Convolutional Networks), reti neurali specializzate per dati con struttura a grafo. Ogni strato permette a un nodo di aggiornare la propria rappresentazione fondendo informazioni dai suoi vicini, prima da punti prossimi e poi gradualmente da punti più distanti. Impilando diversi strati, il sistema apprende pattern a più scale: dettagli locali come sottili variazioni di tono, e tendenze più ampie che coinvolgono molti campioni. Le uscite del grafo che vive all’interno di ciascuna modalità e del grafo che collega le modalità vengono combinate, producendo rappresentazioni ricche che codificano sia relazioni fini sia globali tra immagini, suoni e parole.
Lasciare che siano i dati a decidere quale modalità conta di più
Una sfida chiave nell’apprendimento multimodale è che non tutte le fonti sono ugualmente utili in ogni momento. A volte a trasmettere il messaggio è l’espressione facciale; altre volte domina il tono di voce o il testo. AGSP-DSA affronta questo con un meccanismo di attenzione sensibile alla semantica. Per ogni campione, confronta le caratteristiche di ciascuna modalità rispetto a un ancora semantico, come l’etichetta target o un riassunto di significato, e assegna un peso che riflette quanto quella modalità sia informativa nel contesto. Un passaggio di gating poi regola ulteriormente questi contributi, consentendo al sistema di attenuare segnali inaffidabili o assenti. La rappresentazione fusa, pesata dall’attenzione, viene fornita a un livello finale di predizione che può gestire compiti come classificazione del sentimento, riconoscimento di eventi o assegnazione di generi cinematografici.
Prestazioni nel mondo reale
Il framework è testato su tre impegnativi dataset di riferimento: una grande raccolta di video di opinione per analisi del sentimento e delle emozioni (CMU-MOSEI), un dataset di eventi audio-visivi (AVE) e una collezione cinematografica che combina poster e riassunti della trama (MM-IMDb). Su tutti, AGSP-DSA supera sia i metodi tradizionali di fusione sia concorrenti moderni basati su transformer e grafi. Raggiunge oltre il 95% di accuratezza nella classificazione del sentimento, con guadagni altrettanto rilevanti per il rilevamento di eventi e la predizione del genere cinematografico. È importante che il metodo rimanga robusto quando alcune modalità sono parzialmente assenti o rumorose, e lo faccia senza incorrere in costi computazionali proibitivi. Esperimenti ripetuti mostrano che le sue prestazioni sono stabili e non dipendono da scelte casuali fortunate durante l’addestramento.
Cosa significa per i sistemi AI di tutti i giorni
In termini pratici, AGSP-DSA offre un modo più intelligente per far sì che i sistemi AI ascoltino, guardino e leggano contemporaneamente, restando resilienti quando uno di questi canali fallisce. Rappresentando i dati multimodali come grafi interconnessi, ripulendo i segnali che li attraversano e permettendo al modello di decidere dinamicamente quale modalità fidarsi, l’approccio fornisce decisioni più accurate e affidabili. Questo lo rende un elemento promettente per applicazioni future come assistenti virtuali sensibili alle emozioni, videosorveglianza robusta, raccomandazioni di contenuti più ricche e altri sistemi che devono interpretare flussi multimediali complessi e imperfetti.
Citazione: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Parole chiave: fusione multimodale, reti neurali su grafo, analisi del sentimento, eventi audio-visivi, classificazione multimediale