Clear Sky Science · pl
Adaptacyjne przetwarzanie sygnałów na grafie dla odpornej fuzji multimodalnej z dynamicznym dopasowaniem semantycznym
Dlaczego łączenie obrazu, dźwięku i słów ma znaczenie
Współczesny świat cyfrowy w dużej mierze składa się ze złożonych mieszanin wideo, dźwięku i tekstu — od zwiastunów filmowych z napisami po krótkie klipy w mediach społecznościowych z komentarzami. Nauczenie komputerów rozumienia tego splątania jest kluczowe dla zadań takich jak rozpoznawanie emocji w rozmowach, wykrywanie zdarzeń w filmach czy rekomendowanie filmów. Dane w praktyce bywają jednak nieuporządkowane: czasem brakuje ścieżki dźwiękowej, obrazy są zaszumione, a tekst nieprecyzyjny. W artykule przedstawiono nowy sposób umożliwiający komputerom elastyczne łączenie różnych typów informacji, tak aby potrafiły zrozumieć sytuację nawet wtedy, gdy niektóre fragmenty są zawodna lub brakujące.
Przekształcanie mieszaniny mediów w połączone punkty
Autorzy proponują ramy nazwaną Adaptacyjne Przetwarzanie Sygnałów na Grafie z Dynamicznym Dopasowaniem Semantycznym (AGSP-DSA), która traktuje każdy fragment danych jako element sieci. Najpierw istniejące, wydajne narzędzia wyodrębniają cechy z każdej modalności: sieci obrazowe przetwarzają wizuale, sieci audio podsumowują dźwięki, a modele językowe analizują tekst. Zamiast po prostu łączyć te cechy płasko, AGSP-DSA rozmieszcza je jako węzły w dwóch powiązanych grafach. Jeden graf łączy próbki podobne w obrębie tej samej modalności — na przykład klipy wideo o podobnym wyglądzie. Drugi graf wiąże próbki między modalnościami, które dzielą znaczenie, jak np. głos brzmiący smutno skojarzony z ponurą mimiką twarzy. Ten podwójny obraz grafowy pozwala systemowi śledzić zarówno strukturę wewnątrz każdego typu danych, jak i relacje rozciągające się pomiędzy nimi.
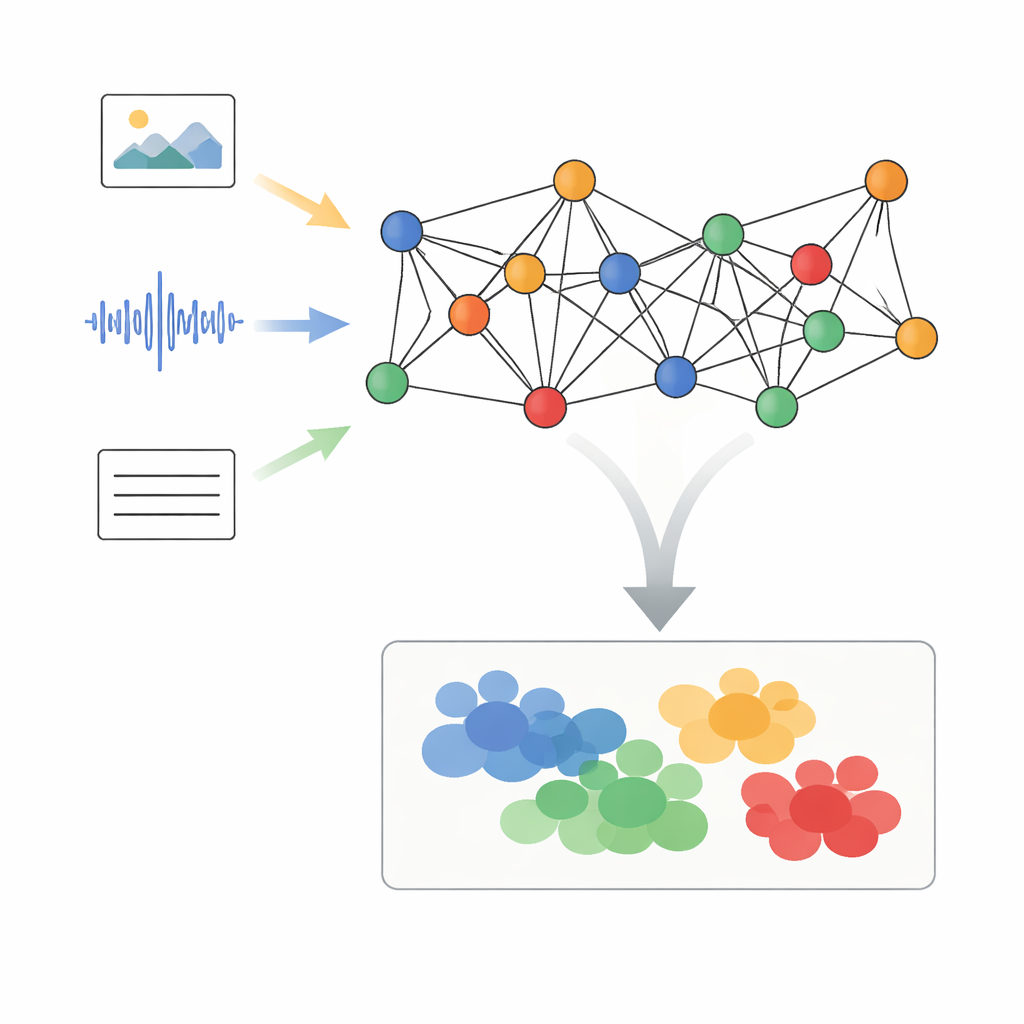
Oczyszczanie sygnałów na grafie
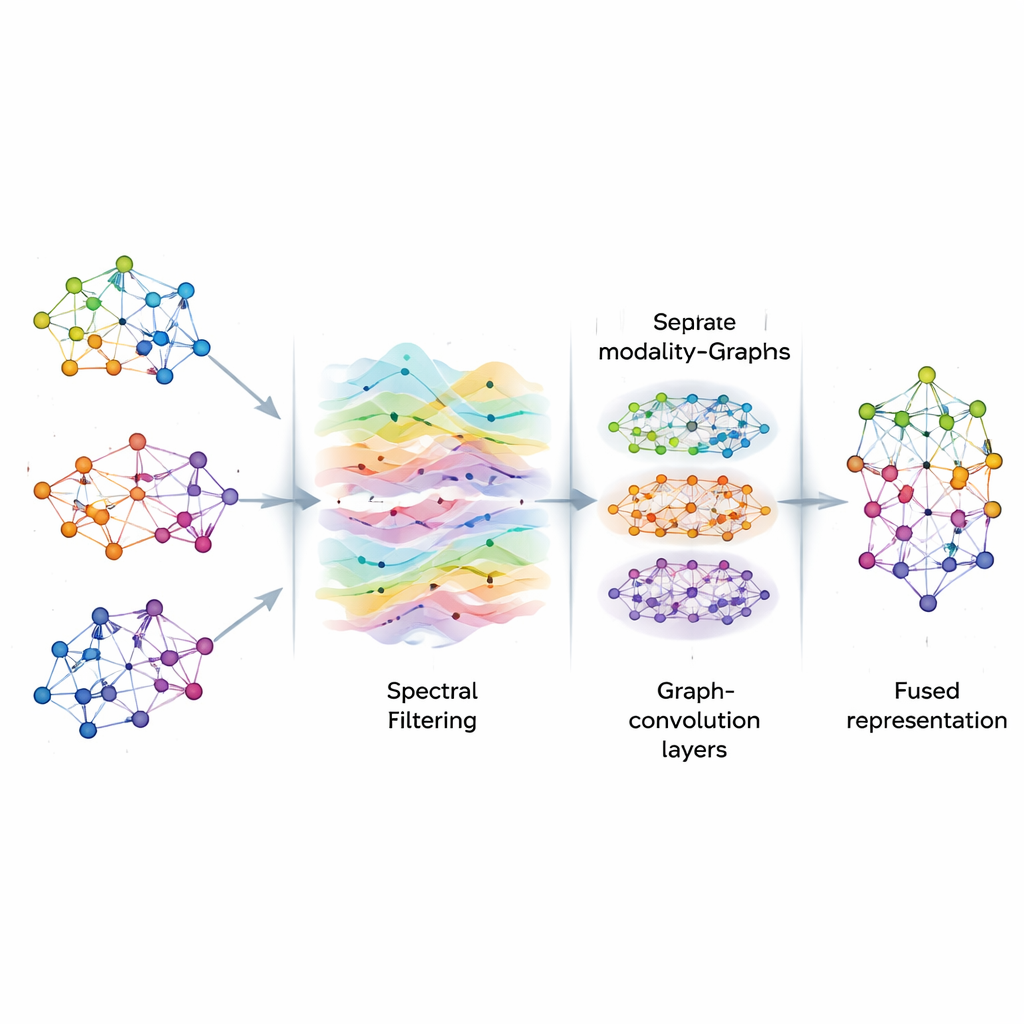
Gdy grafy są zbudowane, AGSP-DSA traktuje informacje na nich jak sygnały przepływające przez sieć, podobnie jak fale dźwiękowe poruszające się w powietrzu. Korzystając z narzędzi przetwarzania sygnałów na grafie, wykonuje rodzaj inteligentnego filtrowania, podkreślając użyteczne wzorce i redukując szum. Zamiast bezpośrednio obliczać kosztowne operacje macierzowe, metoda używa matematycznych skrótów opartych na wielomianach Czebyszewa, by przybliżyć sposób, w jaki sygnały powinny być wygładzone na grafie. Proces ten pomaga modelowi skupić się na spójnych, istotnych połączeniach między próbkami — na przykład powtarzających się wskazówkach emocjonalnych w różnych klipach — bez rozpraszania przez losowe fluktuacje czy brakujące dane.
Nauka wzorców na wielu skalach
Po filtrowaniu AGSP-DSA przekazuje sygnały grafowe do stosu Grafowych Sieci Konwolucyjnych, które są wyspecjalizowanymi sieciami neuronowymi przeznaczonymi do danych w kształcie grafu. Każda warstwa pozwala węzłowi zaktualizować swoją reprezentację poprzez łączenie informacji od sąsiadów, najpierw z pobliskich punktów, a następnie stopniowo z dalszych. Dzięki zbudowaniu kilku warstw system uczy się wzorców na wielu skalach: lokalnych szczegółów, jak subtelne zmiany tonu, oraz szerszych trendów obejmujących wiele próbek. Wyjścia z grafu wewnątrz każdej modalności i grafu łączącego modalności są łączone, tworząc bogate reprezentacje kodujące zarówno drobnoziarniste, jak i globalne relacje między obrazami, dźwiękami i słowami.
Pozwalanie danym decydować, która modalność ma największe znaczenie
Kluczowym wyzwaniem w uczeniu multimodalnym jest to, że nie każde źródło jest równie użyteczne w każdej sytuacji. Czasem przekaz niesie mimika twarzy; innym razem dominuje ton głosu czy tekst. AGSP-DSA radzi sobie z tym za pomocą semantycznie świadomego mechanizmu uwagi. Dla każdej próbki porównuje cechy z każdej modalności z kotwicą semantyczną, taką jak docelowa etykieta lub streszczenie znaczenia, i przypisuje wagę odzwierciedlającą, jak informatywna jest dana modalność w kontekście. Etap bramkowania dodatkowo koryguje te wkłady, pozwalając systemowi przyciszyć sygnały zawodna lub brakujące. Zespolona, ważona uwagą reprezentacja trafia do końcowej warstwy predykcyjnej, która może obsługiwać zadania takie jak klasyfikacja sentymentu, rozpoznawanie zdarzeń czy przypisywanie gatunku filmowego.
Wyniki w warunkach rzeczywistych
Ramy zostały przetestowane na trzech wymagających zestawach benchmarkowych: dużej kolekcji wideo z opiniami do analizy sentymentu i emocji (CMU-MOSEI), zbiorze zdarzeń audio-wizualnych (AVE) oraz zbiorze filmów łączącym plakaty i streszczenia fabuły (MM-IMDb). We wszystkich przypadkach AGSP-DSA przewyższa zarówno tradycyjne metody fuzji, jak i nowoczesne konkurencyjne podejścia oparte na transformerach i grafach. Osiąga ponad 95% dokładności w klasyfikacji sentymentu oraz podobnie znaczące poprawy dla wykrywania zdarzeń i przewidywania gatunku filmowego. Co ważne, metoda pozostaje odporna, gdy niektóre modalności są częściowo brakujące lub zaszumione, i robi to bez ponoszenia nadmiernych kosztów obliczeniowych. Powtarzane eksperymenty pokazują, że jej wydajność jest stabilna i nie zależy od szczęśliwych losowych wyborów podczas treningu.
Co to oznacza dla codziennych systemów AI
Mówiąc prosto, AGSP-DSA oferuje inteligentniejszy sposób, aby systemy AI jednocześnie słuchały, oglądały i czytały, pozostając jednocześnie odporne, gdy jedno z tych kanałów zawodzi. Reprezentując dane multimodalne jako powiązane grafy, oczyszczając przepływające przez nie sygnały i pozwalając modelowi dynamicznie decydować, której modalności ufać, podejście dostarcza dokładniejsze i bardziej wiarygodne decyzje. To czyni je obiecującym elementem budulcowym dla przyszłych zastosowań, takich jak wirtualni asystenci rozpoznający emocje, odporna obserwacja wideo, bogatsze rekomendacje treści oraz inne systemy, które muszą interpretować złożone, niedoskonałe strumienie multimedialne.
Cytowanie: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Słowa kluczowe: fuzja multimodalna, sieć neuronowa na grafach, analiza sentymentu, zdarzenia audio-wizualne, klasyfikacja multimediów