Clear Sky Science · de
Adaptive Graph Signal Processing für robuste multimodale Fusion mit dynamischer semantischer Ausrichtung
Warum das Kombinieren von Bildern, Geräuschen und Worten wichtig ist
Ein Großteil der heutigen digitalen Welt besteht aus reichen Mischungen aus Video, Audio und Text – von Filmtrailern mit Untertiteln bis zu Social-Media-Clips mit Kommentaren. Computern beizubringen, dieses verwobene Material zu verstehen, ist entscheidend für Aufgaben wie das Erkennen von Emotionen in Gesprächen, das Erkennen von Ereignissen in Videos oder das Empfehlen von Filmen. Reale Daten sind jedoch unordentlich: Manchmal fehlt Audio, Bilder sind verrauscht oder Text ist ungenau. Dieses Papier stellt eine neue Methode vor, mit der Computer verschiedene Informationsarten flexibel kombinieren können, sodass sie den Inhalt auch dann noch verstehen, wenn Teile unzuverlässig oder nicht vorhanden sind.
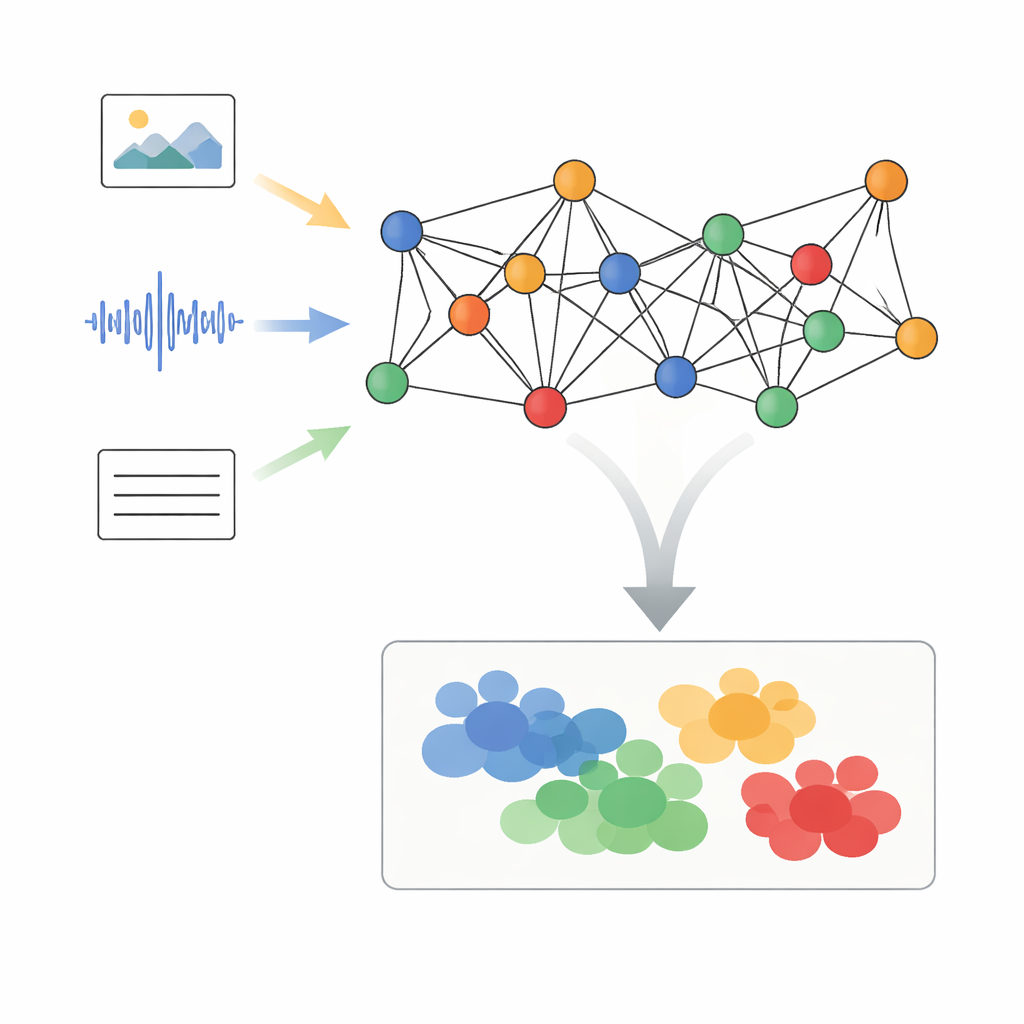
Gemischte Medien in vernetzte Punkte verwandeln
Die Autoren schlagen ein Framework namens Adaptive Graph Signal Processing mit Dynamic Semantic Alignment (AGSP-DSA) vor, das jedes Datenstück als Teil eines Netzwerks behandelt. Zunächst extrahieren leistungsfähige bestehende Werkzeuge Merkmale aus jeder Modalität: Bildnetzwerke verarbeiten visuelle Inhalte, Audionetze fassen Töne zusammen und Sprachmodelle analysieren Text. Statt diese Merkmale einfach zu stapeln, ordnet AGSP-DSA sie als Knoten in zwei verwandten Graphen an. Ein Graph verbindet Proben, die innerhalb derselben Modalität ähnlich sind – zum Beispiel visuell ähnliche Videoclips. Der andere Graph verknüpft Proben über Modalitätsgrenzen hinweg, die Bedeutung teilen, etwa eine traurig klingende Stimme und ein düsterer Gesichtsausdruck. Diese Dual-Graph-Perspektive erlaubt es dem System, sowohl die Struktur innerhalb jeder Datenart als auch die Beziehungen zwischen ihnen zu berücksichtigen.
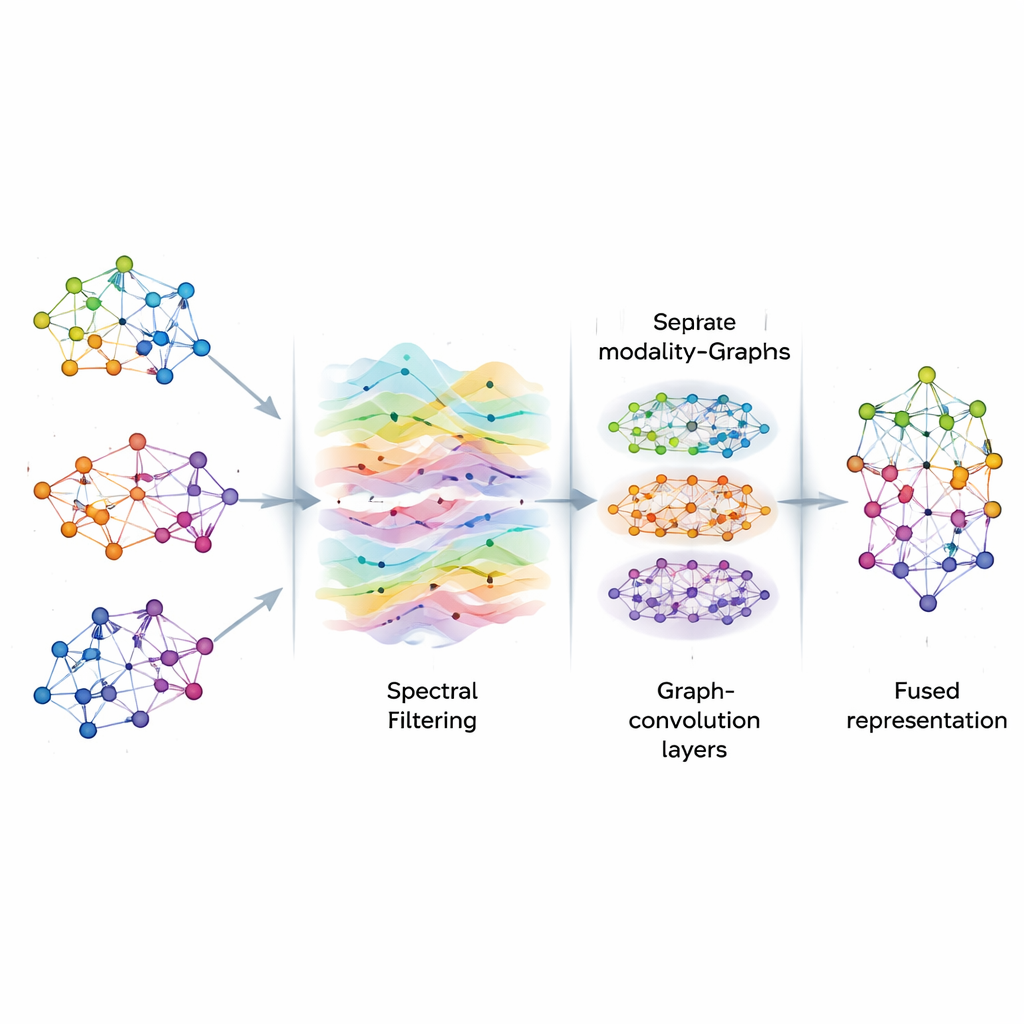
Signale im Graphen bereinigen
Sind die Graphen aufgebaut, behandelt AGSP-DSA die darauf liegenden Informationen wie Signale, die durch ein Netzwerk fließen, ähnlich dem Verhalten von Schallwellen in der Luft. Mit Werkzeugen aus der Graph-Signalverarbeitung führt es eine Art intelligentes Filtern durch, das nützliche Muster betont und Rauschen reduziert. Anstatt teure Matrixoperationen direkt zu berechnen, nutzt die Methode mathematische Abkürzungen auf Basis von Tschebyschev-Polynomen, um zu approximieren, wie Signale auf dem Graphen geglättet werden sollten. Dieser Prozess hilft dem Modell, sich auf konsistente, bedeutungsvolle Verbindungen zwischen Proben zu konzentrieren – etwa wiederkehrende emotionale Hinweise über verschiedene Clips hinweg – ohne sich von zufälligen Schwankungen oder fehlenden Daten ablenken zu lassen.
Muster auf mehreren Skalen lernen
Nach der Filterung speist AGSP-DSA die Graphsignale in einen Stapel von Graph Convolutional Networks, spezialisierte neuronale Netze für graphförmige Daten. Jede Schicht erlaubt es einem Knoten, seine Repräsentation zu aktualisieren, indem er Informationen von seinen Nachbarn aufnimmt, zunächst von nahegelegenen Punkten und dann schrittweise von weiter entfernten. Durch das Stapeln mehrerer Schichten lernt das System Muster auf mehreren Skalen: lokale Details wie subtile Tonänderungen ebenso wie breitere Trends, die viele Proben umfassen. Die Ausgaben des Graphen, der innerhalb jeder Modalität lebt, und des Graphen, der Modalitäten verbindet, werden kombiniert und erzeugen reichhaltige Repräsentationen, die sowohl feingranulare als auch globale Beziehungen zwischen Bildern, Tönen und Worten kodieren.
Die Daten entscheiden lassen, welche Modalität am wichtigsten ist
Eine zentrale Herausforderung in der multimodalen Lernwelt ist, dass nicht jede Quelle jederzeit gleich nützlich ist. Manchmal tragen Gesichtsausdrücke die Botschaft, ein anderes Mal dominiert der Tonfall oder der Text. AGSP-DSA begegnet dem mit einem semantikbewussten Aufmerksamkeitsmechanismus. Für jede Probe vergleicht es die Merkmale jeder Modalität mit einem semantischen Anker, etwa dem Ziel-Label oder einer Bedeutungszusammenfassung, und vergibt ein Gewicht, das widerspiegelt, wie informativ diese Modalität im jeweiligen Kontext ist. Ein Gating-Schritt passt diese Beiträge weiter an und erlaubt dem System, unzuverlässige oder fehlende Signale zu dämpfen. Die fusionierte, auf Aufmerksamkeit gewichtete Repräsentation wird an eine finale Vorhersageschicht übergeben, die Aufgaben wie Sentimentklassifikation, Ereigniserkennung oder Filmgenre-Zuordnung bewältigen kann.
Leistung in der Praxis
Das Framework wird auf drei anspruchsvollen Benchmark-Datensätzen getestet: einer großen Sammlung von Meinungs-Videos für Sentiment- und Emotionsanalyse (CMU-MOSEI), einem audio-visuellen Ereignis-Datensatz (AVE) und einer Filmsammlung, die Poster und Handlungszusammenfassungen kombiniert (MM-IMDb). In allen Fällen übertrifft AGSP-DSA sowohl traditionelle Fusionsmethoden als auch moderne, transformer- und graphbasierte Konkurrenten. Es erreicht über 95% Genauigkeit bei der Sentimentklassifikation sowie ähnlich starke Verbesserungen bei Ereigniserkennung und Filmgenre-Vorhersage. Wichtig ist, dass die Methode robust bleibt, wenn einige Modalitäten teilweise fehlen oder verrauscht sind, und das ohne unvertretbare Rechenkosten. Wiederholte Experimente zeigen, dass die Leistung stabil ist und nicht von glücklichen Zufallsentscheidungen während des Trainings abhängt.
Was das für alltägliche KI-Systeme bedeutet
Alltagsbezogen bietet AGSP-DSA einen intelligenteren Weg, damit KI-Systeme gleichzeitig zuhören, zuschauen und lesen können und dabei widerstandsfähig bleiben, wenn einer dieser Kanäle ausfällt. Indem multimodale Daten als miteinander verbundene Graphen dargestellt, die durch sie fließenden Signale bereinigt und das Modell dynamisch entscheiden lässt, welcher Modalität zu vertrauen ist, liefert der Ansatz genauere und verlässlichere Entscheidungen. Das macht ihn zu einem vielversprechenden Baustein für zukünftige Anwendungen wie emotionsbewusste virtuelle Assistenten, robuste Videoüberwachung, reichhaltigere Inhaltsvorschläge und andere Systeme, die komplexe, unvollkommene Multimedia-Ströme verstehen müssen.
Zitation: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Schlüsselwörter: multimodale Fusion, Graph Neural Networks, Sentimentanalyse, audio-visuelle Ereignisse, Multimedia-Klassifikation