Clear Sky Science · es
Procesamiento adaptativo de señales en grafos para fusión multimodal robusta con alineación semántica dinámica
Por qué importa combinar imágenes, sonidos y palabras
Gran parte del mundo digital actual está hecho de mezclas ricas de vídeo, audio y texto —desde tráilers con subtítulos hasta clips en redes sociales con comentarios. Enseñar a los ordenadores a entender esta mezcla enmarañada es crucial para tareas como reconocer emociones en conversaciones, detectar eventos en vídeos o recomendar películas. Pero los datos reales son desordenados: a veces falta el audio, las imágenes están ruidosas o el texto es ambiguo. Este artículo presenta una nueva forma de permitir que los ordenadores combinen de manera flexible distintos tipos de información para que puedan comprender lo que sucede incluso cuando algunas piezas son poco fiables o están ausentes.
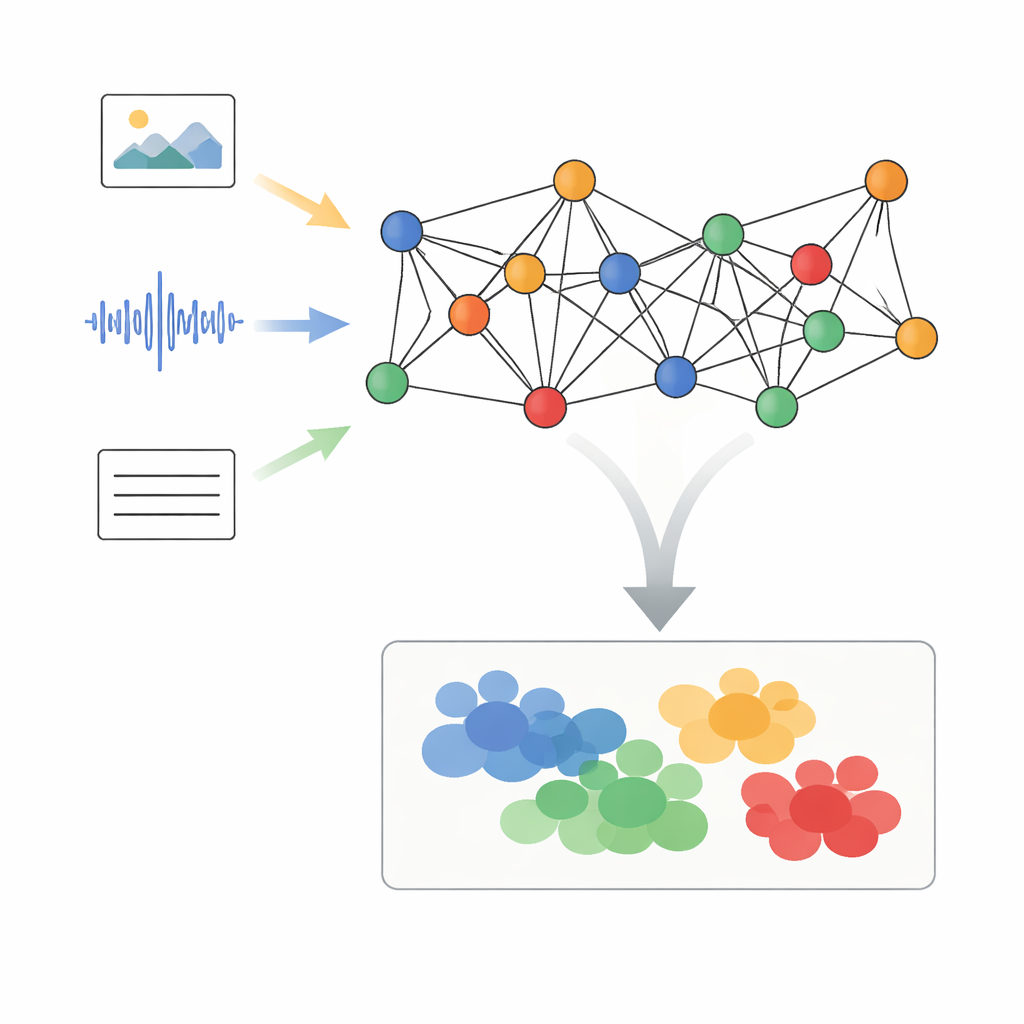
Convertir medios mixtos en puntos conectados
Los autores proponen un marco llamado Procesamiento Adaptativo de Señales en Grafos con Alineación Semántica Dinámica, o AGSP-DSA, que trata cada fragmento de datos como parte de una red. Primero, herramientas potentes ya existentes extraen características de cada modalidad: redes para imágenes procesan lo visual, redes de audio resumen los sonidos y modelos de lenguaje analizan el texto. En lugar de simplemente apilar estas características, AGSP-DSA las organiza como nodos en dos grafos relacionados. Un grafo conecta muestras que son similares dentro de la misma modalidad —por ejemplo, clips de vídeo que se parecen—. El otro grafo enlaza muestras entre modalidades que comparten significado, como una voz con tono triste emparejada con una expresión facial sombría. Esta visión de doble grafo permite al sistema mantener el seguimiento tanto de la estructura dentro de cada tipo de dato como de las relaciones que las atraviesan.
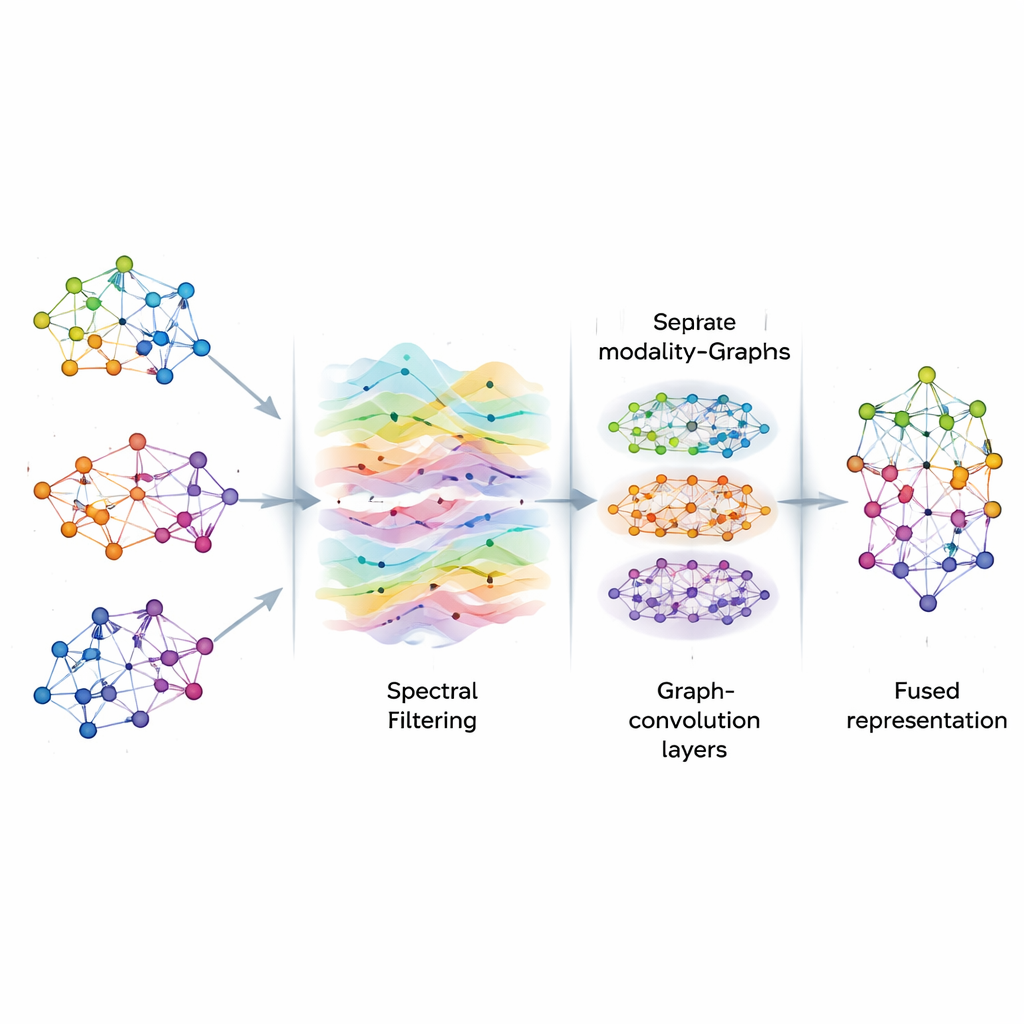
Limpiar las señales en el grafo
Una vez construidos los grafos, AGSP-DSA trata la información sobre ellos como señales que fluyen a través de una red, similar a cómo las ondas sonoras se propagan por el aire. Utilizando herramientas del procesamiento de señales en grafos, realiza una especie de filtrado inteligente que enfatiza patrones útiles mientras reduce el ruido. En lugar de computar directamente costosas operaciones matriciales, el método usa atajos matemáticos basados en polinomios de Chebyshev para aproximar cómo deben suavizarse las señales en el grafo. Este proceso ayuda al modelo a centrarse en conexiones consistentes y significativas entre muestras —como pistas emocionales repetidas en distintos clips— sin distraerse por fluctuaciones aleatorias o datos faltantes.
Aprender patrones a múltiples escalas
Tras el filtrado, AGSP-DSA alimenta las señales del grafo a una pila de Redes de Convolución en Grafos, que son redes neuronales especializadas para datos con estructura de grafo. Cada capa permite a un nodo actualizar su representación combinando información de sus vecinos, primero de puntos cercanos y luego gradualmente de más lejanos. Al apilar varias capas, el sistema aprende patrones a múltiples escalas: detalles locales como cambios sutiles en el tono, así como tendencias más amplias que abarcan muchas muestras. Las salidas del grafo que existe dentro de cada modalidad y del grafo que enlaza modalidades se combinan, produciendo representaciones ricas que codifican tanto relaciones finas como globales entre imágenes, sonidos y palabras.
Dejar que los datos decidan qué modalidad importa más
Un reto clave en el aprendizaje multimodal es que no todas las fuentes son igualmente útiles en todo momento. A veces las expresiones faciales transmiten el mensaje; otras veces domina el tono de voz o el texto. AGSP-DSA aborda esto con un mecanismo de atención consciente de la semántica. Para cada muestra, compara las características de cada modalidad frente a un anclaje semántico, como la etiqueta objetivo o un resumen del significado, y asigna un peso que refleja cuán informativa es esa modalidad en contexto. Un paso de enmascaramiento (gating) ajusta aún más estas contribuciones, permitiendo que el sistema minimice señales poco fiables o ausentes. La representación fusionada y ponderada por atención se envía a una capa final de predicción que puede encargarse de tareas como clasificación de sentimiento, reconocimiento de eventos o etiquetado de géneros cinematográficos.
Rendimiento en el mundo real
El marco se prueba en tres conjuntos de datos de referencia exigentes: una gran recopilación de vídeos de opinión para análisis de sentimiento y emoción (CMU-MOSEI), un conjunto de eventos audio-visuales (AVE) y una colección de películas que combina carteles y resúmenes de trama (MM-IMDb). En todos ellos, AGSP-DSA supera tanto a métodos tradicionales de fusión como a competidores modernos basados en transformadores y grafos. Alcanzó más del 95% de exactitud en clasificación de sentimiento y ganancias igualmente fuertes en detección de eventos y predicción de géneros de películas. Es importante destacar que el método se mantiene robusto cuando algunas modalidades están parcialmente ausentes o ruidosas, y lo hace sin incurrir en un coste computacional prohibitivo. Experimentos repetidos muestran que su rendimiento es estable y no depende de elecciones aleatorias favorables durante el entrenamiento.
Qué significa esto para los sistemas de IA cotidianos
En términos cotidianos, AGSP-DSA ofrece una forma más inteligente para que los sistemas de IA escuchen, miren y lean al mismo tiempo, manteniéndose resilientes cuando uno de esos canales falla. Al representar los datos multimodales como grafos interconectados, limpiar las señales que fluyen por ellos y permitir que el modelo decida dinámicamente en qué modalidad confiar, el enfoque ofrece decisiones más precisas y fiables. Esto lo convierte en un bloque de construcción prometedor para aplicaciones futuras como asistentes virtuales sensibles a la emoción, vigilancia de vídeo robusta, recomendaciones de contenido más ricas y otros sistemas que deben interpretar flujos multimedia complejos e imperfectos.
Cita: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Palabras clave: fusión multimodal, redes neuronales de grafos, análisis de sentimiento, eventos audio-visuales, clasificación multimedia