Clear Sky Science · ru
Адаптивная обработка графовых сигналов для устойчивого мультимодального слияния с динамическим семантическим выравниванием
Почему важно сочетать визуальную, звуковую и текстовую информацию
Большая часть современного цифрового мира состоит из богатых смешанных потоков видео, аудио и текста — от трейлеров с субтитрами до клипов в социальных сетях с комментариями. Научить компьютеры понимать эту запутанную смесь необходимо для задач, таких как распознавание эмоций в разговоре, обнаружение событий в видео или рекомендация фильмов. Но реальные данные шумны: иногда отсутствует звук, изображения испорчены, а текст неясен. В этой статье предлагается новый способ гибкого объединения разных типов информации, который позволяет системам сохранять понимание происходящего даже когда некоторые составляющие ненадежны или отсутствуют.
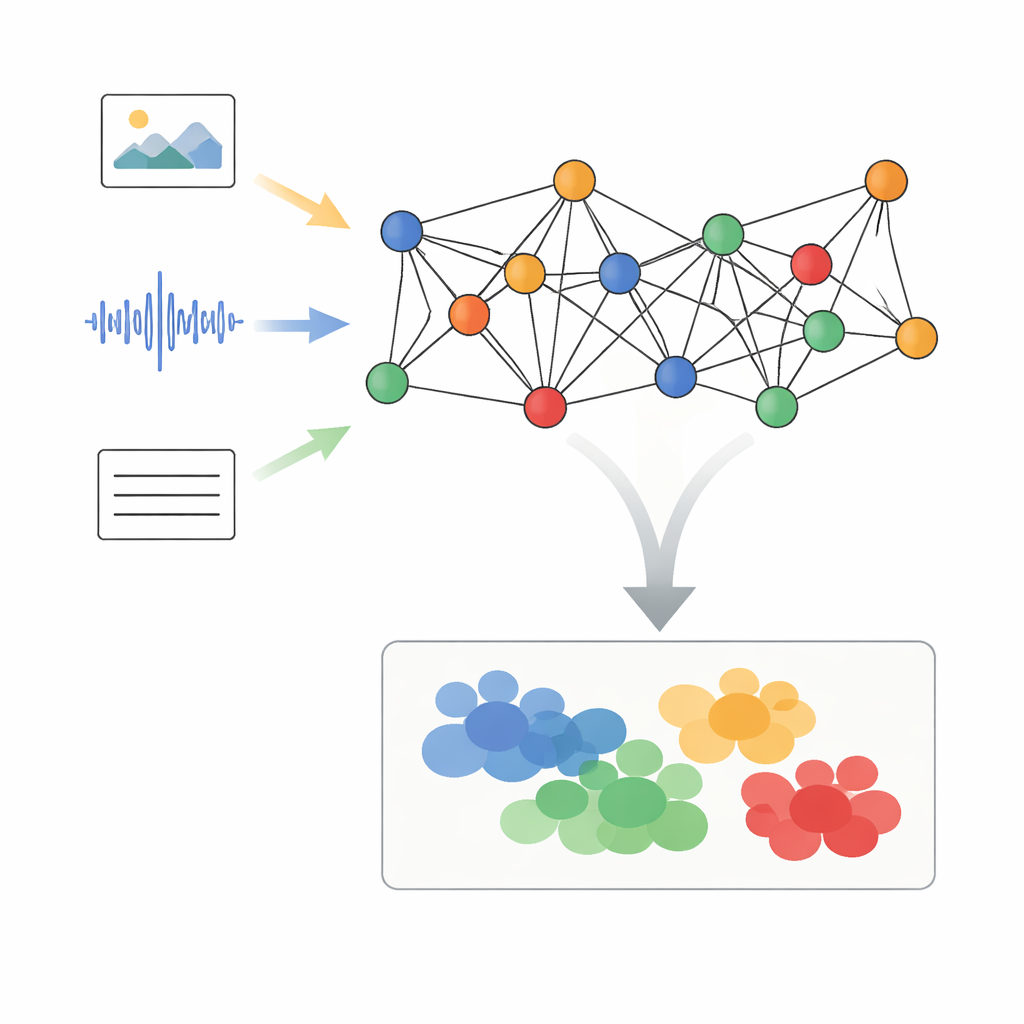
Преобразование смешанных данных в связанные узлы
Авторы предлагают фреймворк под названием Adaptive Graph Signal Processing with Dynamic Semantic Alignment (AGSP-DSA), который рассматривает каждый фрагмент данных как часть сети. Сначала существующие мощные инструменты извлекают признаки из каждой модальности: сети для изображений обрабатывают визуал, аудиосети суммируют звуки, а языковые модели анализируют текст. Вместо простого конкатенирования этих признаков AGSP-DSA располагает их в виде узлов в двух взаимосвязанных графах. Один граф связывает образцы, похожие внутри одной модальности — например, видеоклипы, которые выглядят похоже. Другой граф соединяет образцы разных модальностей, разделяющие смысл, например грустный голос, сопровождающийся мрачным выражением лица. Такой двойной графовый подход позволяет системе одновременно учитывать структуру внутри каждого типа данных и отношения, которые простираются между ними.
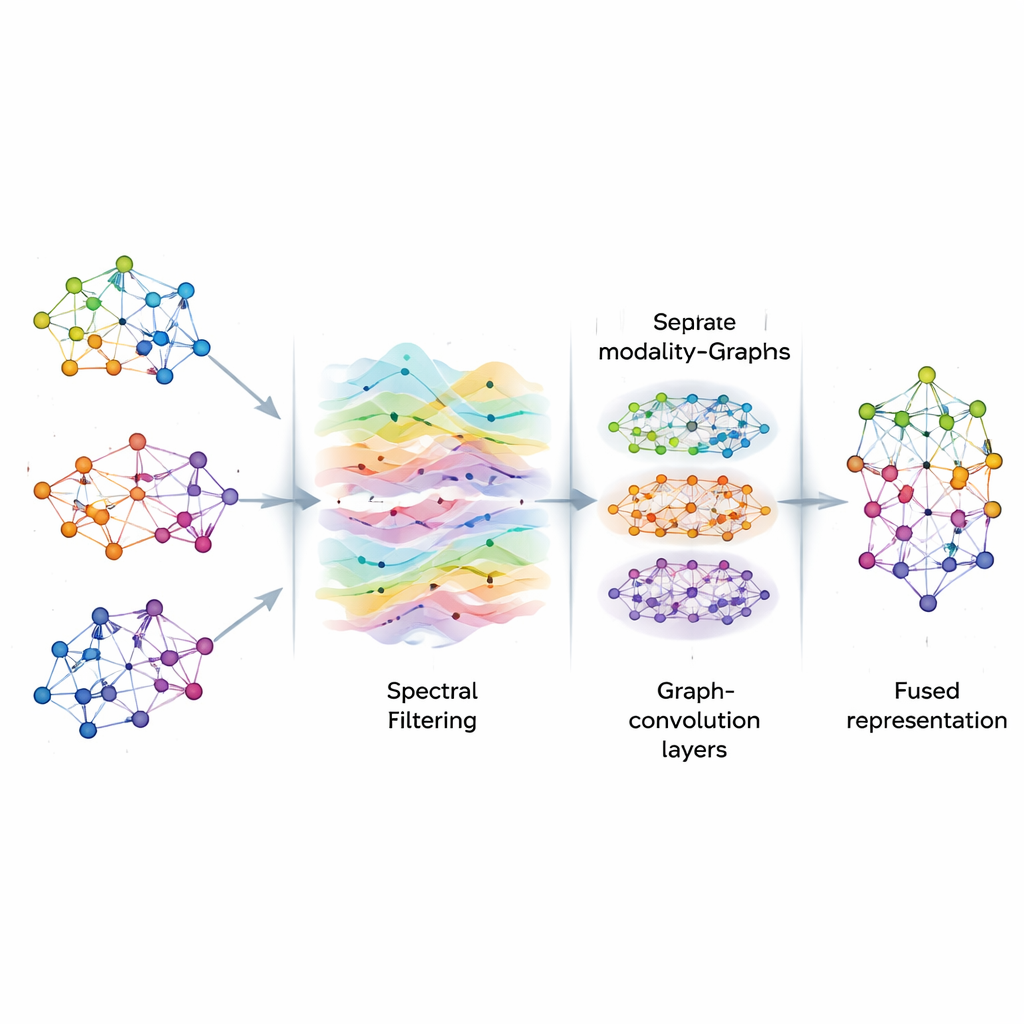
Очищение сигналов на графе
После построения графов AGSP-DSA рассматривает информацию на них как сигналы, протекающие по сети, аналогично распространению звуковых волн в воздухе. С помощью инструментов обработки графовых сигналов выполняется своего рода интеллектуальная фильтрация, подчеркивающая полезные закономерности и уменьшающая шум. Вместо прямого вычисления дорогостоящих матричных операций метод использует математические приближения на основе многочленов Чебышёва, чтобы аппроксимировать, как сигналы должны сглаживаться на графе. Этот процесс помогает модели сосредоточиться на устойчивых, значимых связях между образцами — например, на повторяющихся эмоциональных признаках в разных клипах — не отвлекаясь на случайные флуктуации или отсутствующие данные.
Обучение шаблонам на нескольких масштабах
После фильтрации AGSP-DSA передаёт графовые сигналы в стек графовых сверточных сетей — специализированных нейросетей для данных в форме графа. Каждый слой позволяет узлу обновлять своё представление, объединяя информацию от соседей: сначала от близких точек, а затем постепенно от более удалённых. Накопление нескольких слоёв позволяет системе выявлять закономерности на разных масштабах: локальные детали, такие как тонкие изменения интонации, а также более широкие тенденции, охватывающие множество образцов. Выходы из графа, построенного внутри каждой модальности, и из графа, связывающего модальности, объединяются, формируя богатые представления, кодирующие как мелкомасштабные, так и глобальные отношения между изображениями, звуками и словами.
Дать данным решать, какая модальность важнее
Ключевая проблема в мультимодальном обучении — не каждый источник одинаково полезен во всех ситуациях. Порой основную информацию несёт мимика; иногда важна интонация или текст. AGSP-DSA решает это с помощью семантически чувствительного механизма внимания. Для каждого образца он сравнивает признаки каждой модальности с семантическим якорем, таким как целевая метка или сводка смысла, и присваивает вес, отражающий информативность этой модальности в данном контексте. Шаг «шлюза» (gating) дополнительно регулирует эти вклады, позволяя системе ослаблять влияние ненадёжных или отсутствующих сигналов. Объединённое представление с учётом внимания подаётся в финальный предсказательный слой, который может решать задачи вроде классификации настроений, распознавания событий или назначения жанров фильмов.
Результаты в реальных условиях
Фреймворк протестирован на трёх требовательных эталонных наборах данных: большой коллекции видео-отзывов для анализа настроений и эмоций (CMU-MOSEI), наборе аудиовизуальных событий (AVE) и киноколлекции, объединяющей постеры и аннотации к сюжетам (MM-IMDb). Во всех них AGSP-DSA превосходит как традиционные методы слияния, так и современные методы на базе трансформеров и графов. Он достигает более 95% точности в классификации настроений, а также даёт сопоставимые существенные улучшения для обнаружения событий и предсказания жанров фильмов. Важно, что метод остаётся устойчивым при частичной потере или зашумлении некоторых модальностей и при этом не требует чрезмерных вычислительных ресурсов. Повторные эксперименты показывают стабильность результатов и отсутствие зависимости от «удачных» случайных инициализаций при обучении.
Что это значит для прикладных систем ИИ
Проще говоря, AGSP-DSA предлагает более умный способ одновременно слушать, смотреть и читать при сохранении устойчивости, если один из каналов выходит из строя. Представляя мультимодальные данные в виде взаимосвязанных графов, очищая сигналы, протекающие по ним, и позволяя модели динамически решать, каким модальностям доверять, подход обеспечивает более точные и надёжные решения. Это делает метод многообещающим строительным блоком для будущих приложений: эмоционально-чувствительных виртуальных ассистентов, надёжного видеонаблюдения, более содержательных рекомендаций контента и других систем, которым нужно интерпретировать сложные, несовершенные мультимедийные потоки.
Цитирование: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Ключевые слова: мультимодальное слияние, графовые нейронные сети, анализ настроений, аудиовизуальные события, классификация мультимедиа