Clear Sky Science · fr
Traitement adaptatif des signaux sur graphe pour une fusion multimodale robuste avec alignement sémantique dynamique
Pourquoi combiner images, sons et mots est important
Une grande partie du monde numérique actuel mélange vidéos, audio et texte — des bandes-annonces avec sous-titres aux clips sur les réseaux sociaux accompagnés de commentaires. Apprendre aux ordinateurs à interpréter cet enchevêtrement d’informations est crucial pour des tâches comme la reconnaissance des émotions dans les conversations, la détection d’événements dans des vidéos ou la recommandation de films. Mais les données réelles sont souvent bruitées : l’audio peut manquer, les images être dégradées ou le texte imprécis. Cet article présente une nouvelle façon de permettre aux ordinateurs de combiner de manière flexible différents types d’information afin qu’ils puissent continuer à comprendre ce qui se passe même lorsque certaines composantes sont peu fiables ou absentes.
Transformer les médias mixtes en points connectés
Les auteurs proposent un cadre appelé Traitement Adaptatif des Signaux sur Graphe avec Alignement Sémantique Dynamique, ou AGSP-DSA, qui considère chaque élément de données comme partie d’un réseau. D’abord, des outils puissants existants extraient des caractéristiques pour chaque modalité : des réseaux d’images décrivent le visuel, des réseaux audio résument les sons et des modèles de langage traitent le texte. Plutôt que d’empiler simplement ces caractéristiques, AGSP-DSA les organise en nœuds répartis dans deux graphes liés. Un graphe connecte des échantillons similaires au sein de la même modalité — par exemple des extraits vidéo qui se ressemblent. L’autre relie des échantillons entre modalités qui partagent un sens, comme une voix au timbre triste associée à une expression faciale morose. Cette vue duale permet au système de garder trace à la fois de la structure interne à chaque type de données et des relations qui les relient entre eux.
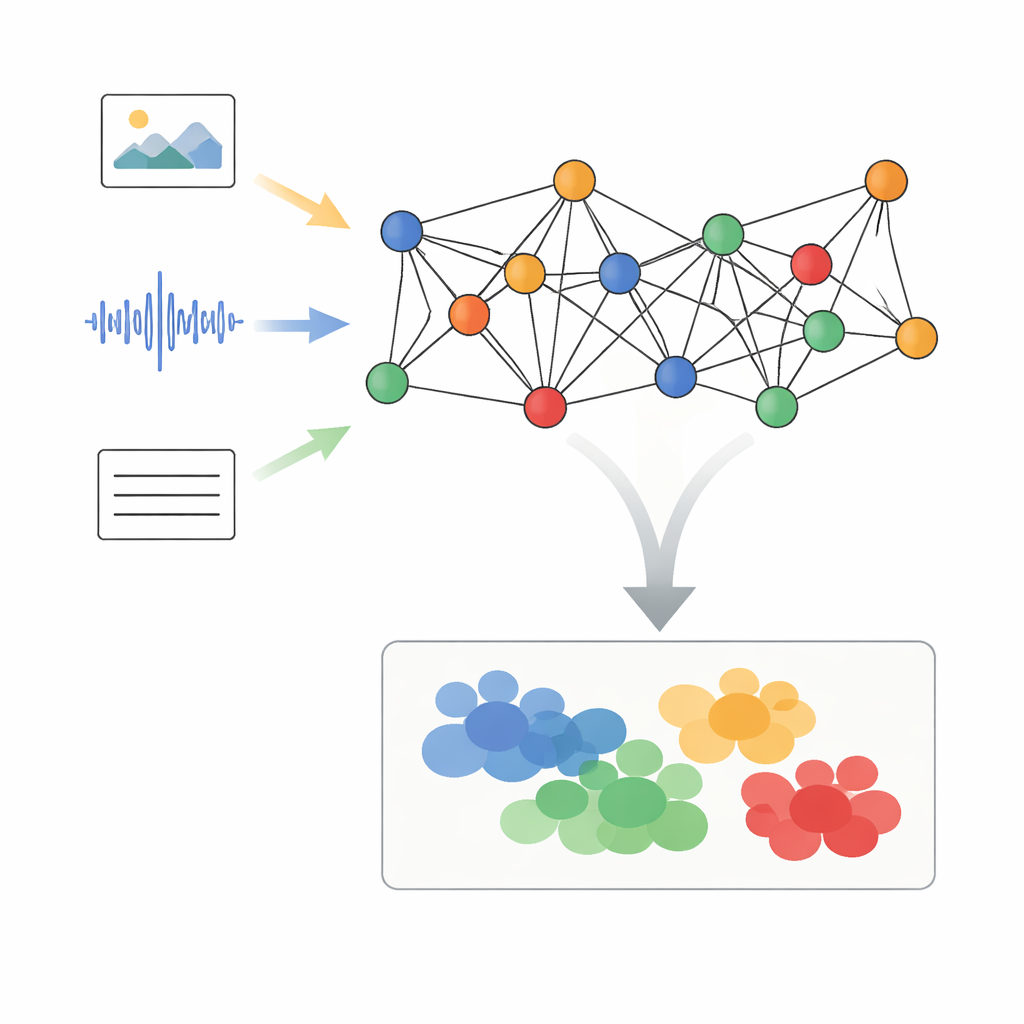
Épurer les signaux sur le graphe
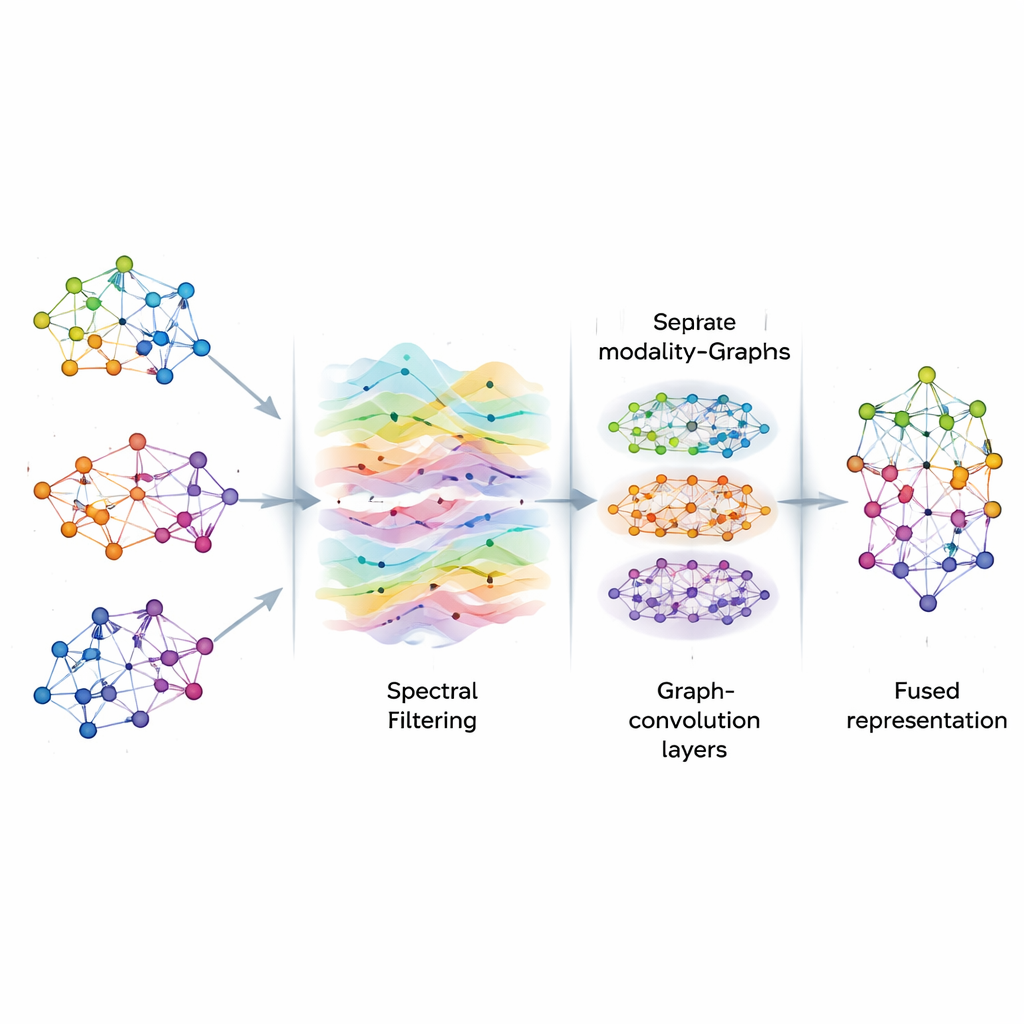
Une fois les graphes construits, AGSP-DSA considère l’information qui y circule comme des signaux se propageant dans un réseau, à la manière d’ondes sonores dans l’air. En utilisant des outils du traitement des signaux sur graphe, il réalise une sorte de filtrage intelligent, mettant en valeur les motifs utiles tout en réduisant le bruit. Plutôt que de calculer directement des opérations matricielles coûteuses, la méthode emploie des approximations mathématiques fondées sur les polynômes de Chebyshev pour estimer comment les signaux doivent être lissés sur le graphe. Ce processus aide le modèle à se concentrer sur des connexions cohérentes et significatives entre les échantillons — comme des indices émotionnels récurrents à travers différents extraits — sans se laisser distraire par des fluctuations aléatoires ou des données manquantes.
Apprendre des motifs à plusieurs échelles
Après le filtrage, AGSP-DSA injecte les signaux du graphe dans une pile de Réseaux de Convolution sur Graphes, des réseaux neuronaux spécialement conçus pour des données en forme de graphe. Chaque couche permet à un nœud de mettre à jour sa représentation en combinant l’information de ses voisins, d’abord à partir de points proches puis progressivement à partir de nœuds plus éloignés. En empilant plusieurs couches, le système apprend des motifs à plusieurs échelles : des détails locaux comme des variations subtiles de ton, ainsi que des tendances plus larges couvrant de nombreux échantillons. Les sorties issues du graphe interne à chaque modalité et du graphe qui relie les modalités sont combinées, produisant des représentations riches encodant à la fois des relations fines et globales entre images, sons et mots.
Laisser les données décider quelle modalité compte le plus
Un défi clé en apprentissage multimodal est que toutes les sources ne sont pas également utiles tout le temps. Parfois, ce sont les expressions faciales qui véhiculent le message ; d’autres fois, le ton de la voix ou le texte dominent. AGSP-DSA aborde cela avec un mécanisme d’attention sensible à la sémantique. Pour chaque échantillon, il compare les caractéristiques de chaque modalité à une ancre sémantique, comme l’étiquette cible ou un résumé de sens, et attribue un poids reflétant l’utilité de cette modalité dans le contexte. Une étape de gating ajuste ensuite ces contributions, permettant au système d’atténuer les signaux peu fiables ou manquants. La représentation fusionnée et pondérée par l’attention est transmise à une couche de prédiction finale capable de gérer des tâches comme la classification des sentiments, la reconnaissance d’événements ou l’identification des genres cinématographiques.
Performances dans des conditions réelles
Le cadre est évalué sur trois jeux de données de référence exigeants : une large collection de vidéos d’opinion pour l’analyse des sentiments et des émotions (CMU-MOSEI), un jeu de données d’événements audio-visuels (AVE) et une collection de films combinant affiches et résumés de scénario (MM-IMDb). Sur l’ensemble de ces ensembles, AGSP-DSA surpasse à la fois les méthodes de fusion traditionnelles et des concurrents modernes basés sur des transformers ou des graphes. Il atteint plus de 95 % de précision en classification des sentiments, et montre des gains comparables pour la détection d’événements et la prédiction de genres de films. Fait important, la méthode reste robuste lorsque certaines modalités sont partiellement manquantes ou bruitées, et ce sans entraîner de coûts de calcul prohibitifs. Des expériences répétées montrent que ses performances sont stables et ne dépendent pas de choix aléatoires chanceux lors de l’entraînement.
Ce que cela signifie pour les systèmes d’IA du quotidien
Concrètement, AGSP-DSA propose une manière plus intelligente pour les systèmes d’IA d’écouter, regarder et lire simultanément, tout en restant résilients lorsqu’un de ces canaux fait défaut. En représentant les données multimodales comme des graphes interconnectés, en nettoyant les signaux qui y circulent et en laissant le modèle décider dynamiquement quelle modalité privilégier, l’approche fournit des décisions plus précises et fiables. Cela en fait un composant prometteur pour des applications futures telles que des assistants virtuels sensibles aux émotions, une vidéosurveillance robuste, des recommandations de contenu plus riches et d’autres systèmes devant interpréter des flux multimédias complexes et imparfaits.
Citation: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Mots-clés: fusion multimodale, réseaux de neurones sur graphes, analyse des sentiments, événements audio-visuels, classification multimédia