Clear Sky Science · nl
Aanpasbare graaf-signaalverwerking voor robuuste multimodale fusie met dynamische semantische afstemming
Waarom het combineren van beelden, geluiden en woorden ertoe doet
Een groot deel van de digitale wereld van vandaag bestaat uit rijke mengsels van video, audio en tekst—van filmtreilers met ondertitels tot socialmediaklips met commentaren. Computers leren om deze ingewikkelde mix te interpreteren is cruciaal voor taken zoals het herkennen van emoties in gesprekken, het detecteren van gebeurtenissen in video’s of het aanbevelen van films. Maar echte data zijn rommelig: soms ontbreekt audio, zijn beelden ruiserig of is tekst vaag. Dit artikel presenteert een nieuwe manier waarop computers flexibel verschillende soorten informatie kunnen combineren zodat ze toch kunnen begrijpen wat er gebeurt, zelfs wanneer sommige onderdelen onbetrouwbaar of afwezig zijn.
Gemixt materiaal omzetten in verbonden punten
De auteurs stellen een raamwerk voor genaamd Adaptive Graph Signal Processing with Dynamic Semantic Alignment, of AGSP-DSA, dat elk datapunt als deel van een netwerk behandelt. Eerst halen krachtige bestaande tools kenmerken uit elke modaliteit: beeldnetwerken verwerken visuals, audionetwerken vatten geluiden samen en taalmodellen verwerken tekst. In plaats van deze kenmerken simpelweg naast elkaar te plaatsen, ordent AGSP-DSA ze als knopen in twee verwante grafen. De ene graaf verbindt voorbeelden die binnen dezelfde modaliteit op elkaar lijken—bijvoorbeeld videoclips die er gelijkend uitzien. De andere graaf koppelt voorbeelden over modaliteiten heen die betekenis delen, zoals een verdrietig klinkende stem gecombineerd met een sombere gezichtsuitdrukking. Dit dubbele-graafperspectief stelt het systeem in staat zowel de structuur binnen elk datatype als de relaties eroverheen bij te houden.
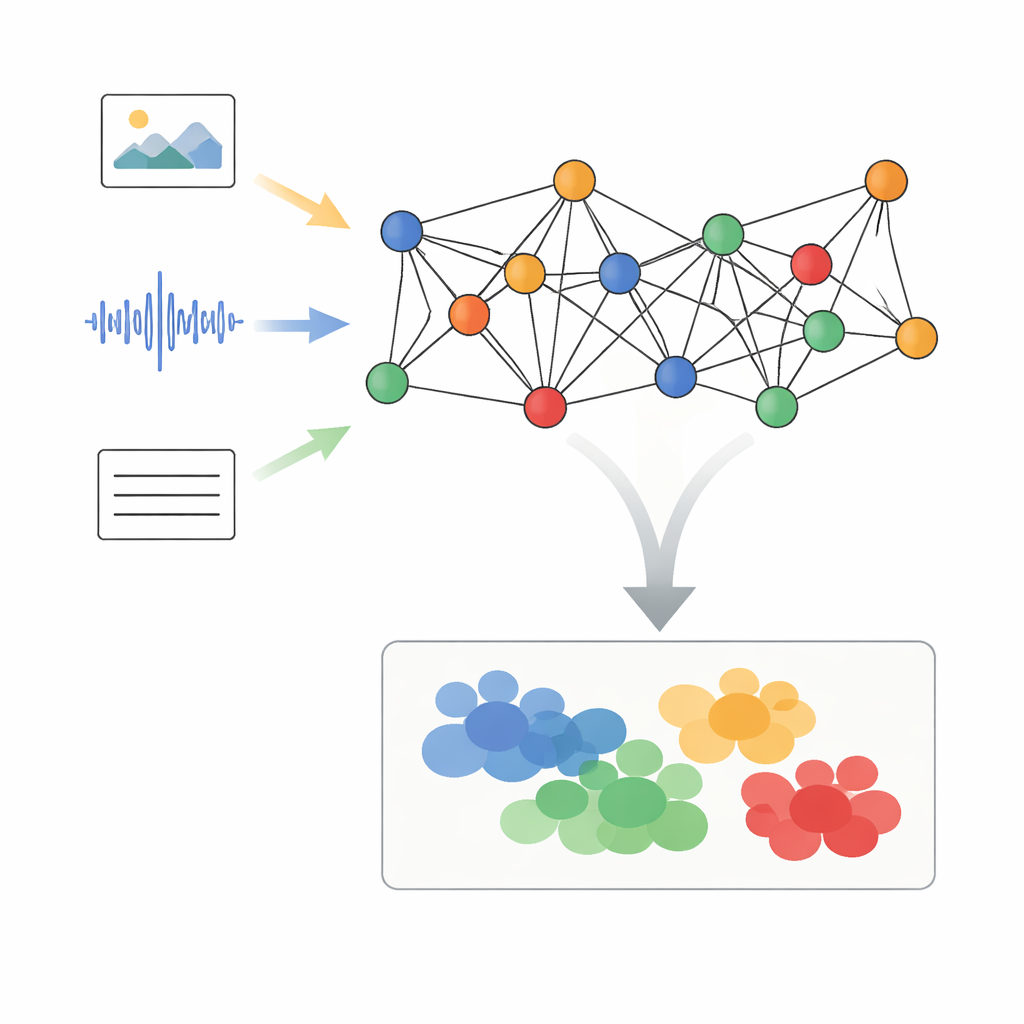
Signalenschoonmaak op de graaf
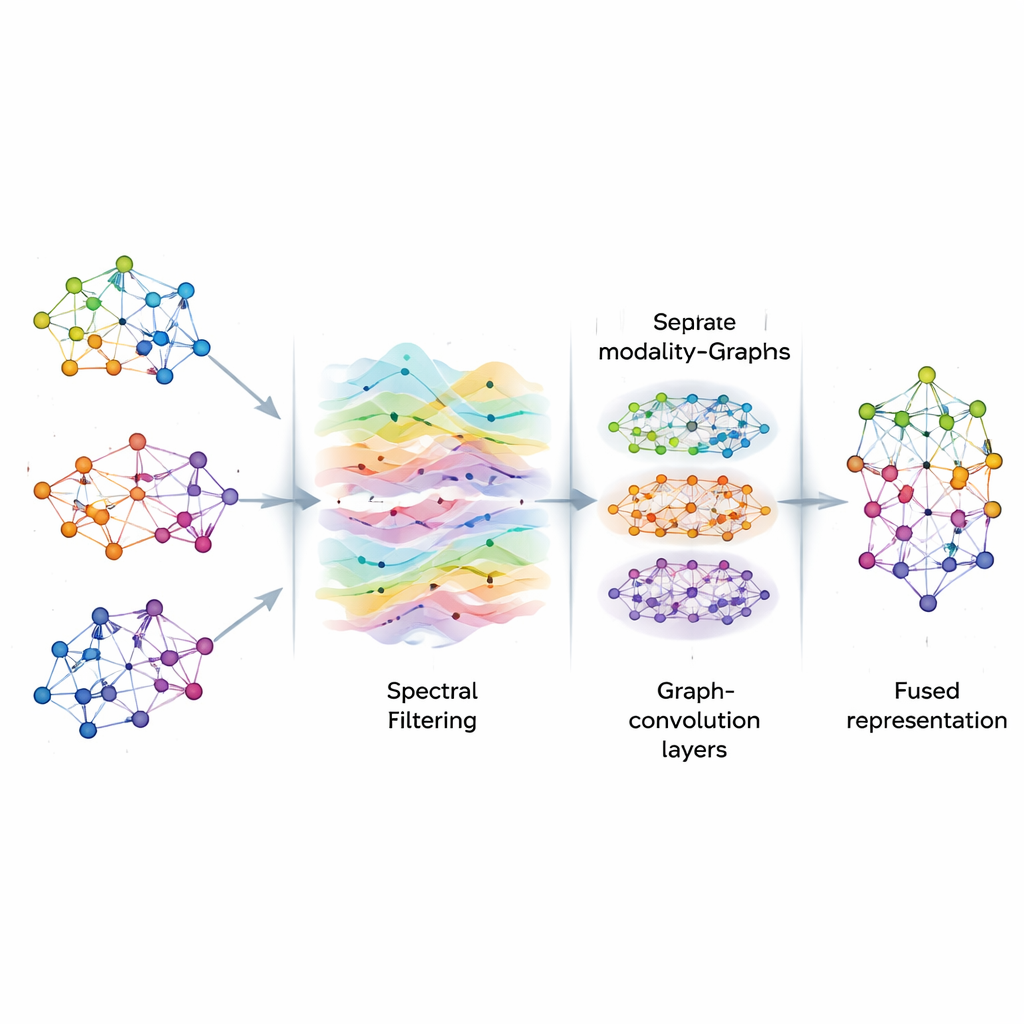
Zodra de grafen gebouwd zijn, behandelt AGSP-DSA de informatie erop als signalen die door een netwerk stromen, vergelijkbaar met hoe geluidsgolven zich door de lucht verplaatsen. Met hulpmiddelen uit de graaf-signaalverwerking voert het een soort intelligente filtering uit, waarbij nuttige patronen worden benadrukt en ruis wordt verminderd. In plaats van direct dure matrixbewerkingen te berekenen, gebruikt de methode wiskundige kortere wegen op basis van Chebyshev-polynomen om te benaderen hoe signalen op de graaf gesmooth moeten worden. Dit proces helpt het model zich te concentreren op consistente, betekenisvolle verbanden tussen voorbeelden—zoals herhaalde emotionele aanwijzingen in verschillende clips—zonder te worden afgeleid door willekeurige fluctuaties of ontbrekende data.
Patronen leren op meerdere schalen
Na filtering voert AGSP-DSA de graafsignalen in een stapel Graph Convolutional Networks, gespecialiseerde neurale netwerken die zijn ontworpen voor graafvormige data. Elke laag laat een knoop zijn representatie bijwerken door informatie van zijn buren te mengen, eerst van nabijgelegen punten en vervolgens geleidelijk van verderafgelegen knopen. Door meerdere lagen te stapelen leert het systeem patronen op meerdere schalen: lokale details zoals subtiele toonveranderingen, evenals bredere trends die veel voorbeelden overspannen. De output van de graaf die binnen elke modaliteit leeft en van de graaf die modaliteiten met elkaar verbindt worden gecombineerd, waardoor rijke representaties ontstaan die zowel fijnmazige als globale relaties tussen beelden, geluiden en woorden coderen.
Het aan de data overlaten welke modaliteit het belangrijkst is
Een belangrijke uitdaging in multimodaal leren is dat niet elke bron altijd even nuttig is. Soms dragen gezichtsuitdrukkingen de boodschap; andere keren overheerst de stemtoon of de tekst. AGSP-DSA pakt dit aan met een semantisch-bewust attentie-mechanisme. Voor elk voorbeeld vergelijkt het de kenmerken van elke modaliteit met een semantische ankerpunt, zoals het doellabel of een samenvatting van de betekenis, en kent het een gewicht toe dat weerspiegelt hoe informatief die modaliteit in die context is. Een poortstap past deze bijdragen vervolgens verder aan, waardoor het systeem onbetrouwbare of ontbrekende signalen kan neerwaarts bijstellen. De gefuseerde, attentie-gewogen representatie wordt gevoed naar een eindlaag voor voorspelling die taken aankan zoals sentimentclassificatie, gebeurtenisherkenning of het toewijzen van filmgenres.
Prestaties in de echte wereld
Het raamwerk is getest op drie veeleisende benchmarkdatasets: een grote verzameling opinievideo’s voor sentiment- en emotieanalyse (CMU-MOSEI), een audio-visuele gebeurtenisdataset (AVE) en een filmcollectie die posters en plot-samenvattingen combineert (MM-IMDb). Over al deze datasets presteert AGSP-DSA beter dan zowel traditionele fusie-methoden als moderne transformer- en graafgebaseerde concurrenten. Het bereikt meer dan 95% nauwkeurigheid bij sentimentclassificatie, en vergelijkbare sterke verbeteringen voor gebeurtenisdetectie en filmgenrevoorspelling. Belangrijk is dat de methode robuust blijft wanneer sommige modaliteiten gedeeltelijk ontbreken of ruis bevatten, en dat zonder onaanvaardbare rekenkosten. Herhaalde experimenten tonen dat de prestaties stabiel zijn en niet afhankelijk van geluk bij willekeurige keuzes tijdens training.
Wat dit betekent voor alledaagse AI-systemen
In alledaagse bewoordingen biedt AGSP-DSA een slimere manier voor AI-systemen om tegelijk te luisteren, kijken en lezen, terwijl ze veerkrachtig blijven wanneer een van die kanalen faalt. Door multimodale data te representeren als onderling verbonden grafen, de signalen die erdoorheen stromen te zuiveren en het model dynamisch te laten beslissen welke modaliteit te vertrouwen, levert de aanpak nauwkeurigere en betrouwbaardere beslissingen. Dit maakt het tot een veelbelovend bouwblok voor toekomstige toepassingen zoals emotie-gevoelige virtuele assistenten, robuuste videobewaking, rijkere contentaanbevelingen en andere systemen die complexe, onvolmaakte multimediastromen moeten begrijpen.
Bronvermelding: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Trefwoorden: multimodale fusie, graaf neurale netwerken, sentimentanalyse, audio-visuele gebeurtenissen, multimediaclassificatie