Clear Sky Science · ar
معالجة إشارات الرسم البياني التكيفية للاندماج متعدد الوسائط القوي مع المحاذاة الدلالية الديناميكية
لماذا يهم الجمع بين المشاهد والأصوات والكلمات
جزء كبير من العالم الرقمي اليوم مكوَّن من مزيج غني من الفيديو والصوت والنص — من مقاطع إعلانات الأفلام مع ترجمات إلى مقاطع وسائل التواصل الاجتماعي مع تعليقات. تعليم الحواسيب على فهم هذا الخليط المعقَّد أمر أساسي لمهمات مثل التعرف على العواطف في المحادثات، واكتشاف الأحداث في الفيديوهات، أو توصية الأفلام. لكن البيانات الحقيقية فوضوية: أحيانًا يختفي الصوت، أو تكون الصور مشوشة، أو يكون النص غامضًا. تقدم هذه الورقة طريقة جديدة تتيح للحواسيب الجمع بين أنواع المعلومات المختلفة بشكل مرن بحيث تظل قادرة على فهم ما يحدث حتى عندما تكون بعض الأجزاء غير موثوقة أو مفقودة.
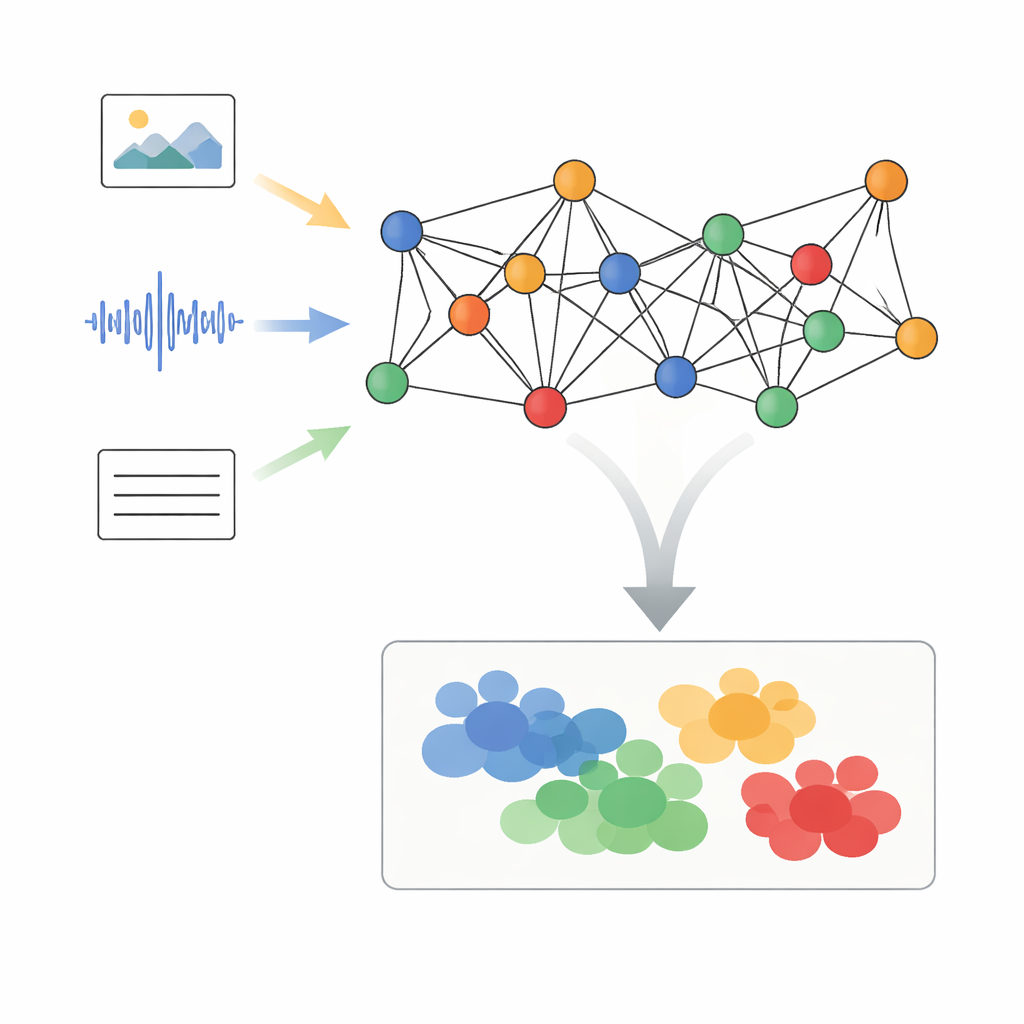
تحويل الوسائط المختلطة إلى نقاط متصلة
يقترح المؤلفون إطارًا يُسمى معالجة إشارات الرسم البياني التكيفية مع المحاذاة الدلالية الديناميكية، أو AGSP-DSA، يعامل كل جزء من البيانات كجزء من شبكة. أولًا، تستخرج أدوات قوية موجودة بالفعل ميزات كل أسلوب: شبكات الصور تُحلل المشاهد البصرية، وشبكات الصوت تلخّص الأصوات، ونماذج اللغة تعالج النصوص. بدلًا من تجميع هذه الميزات معًا بشكل بدائي، يرتب AGSP-DSA هذه الميزات كعقد في رسمين مرتبطين. يربط أحد الرسوم عينات متشابهة داخل نفس النمط — مثل مقاطع فيديو تبدو متشابهة. يربط الرسم الآخر عينات عبر الأنماط التي تشترك في المعنى، مثل صوت حزين مقرون بتعبير وجه كئيب. تتيح هذه النظرة ذات الرسمين للنظام تتبع كل من البنية داخل كل نوع من البيانات والعلاقات التي تمتد عبرها.
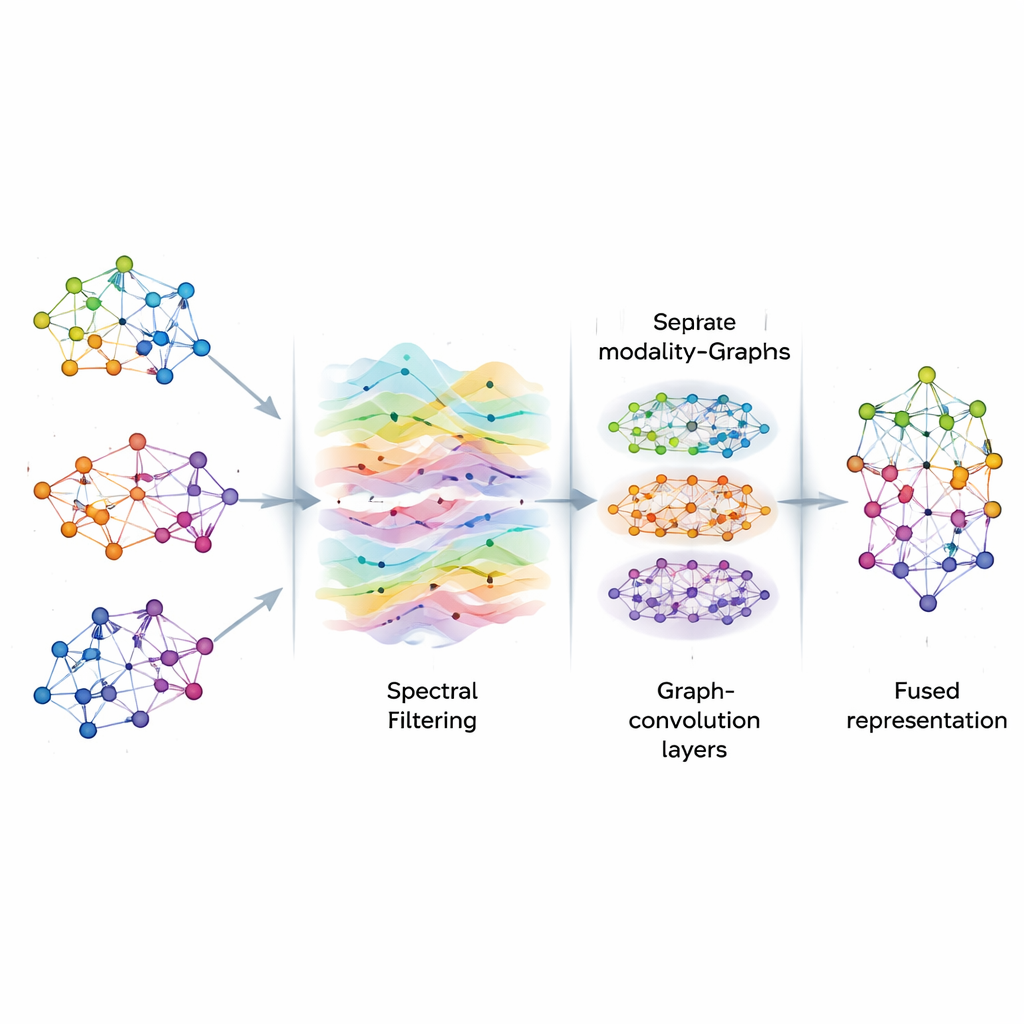
تنقية الإشارات على الرسم البياني
بمجرد بناء الرسوم، يتعامل AGSP-DSA مع المعلومات عليها كأنها إشارات تتدفق عبر شبكة، على نحو مشابه لحركة موجات الصوت في الهواء. باستخدام أدوات من معالجة إشارات الرسم البياني، ينفذ نوعًا من التصفية الذكية، مؤكِّدًا الأنماط المفيدة بينما يقلل الضوضاء. بدلًا من إجراء عمليات مصفوفية مكلفة مباشرة، يستخدم الأسلوب اختصارات رياضية قائمة على متعددة حدود تشيبيشيف لتقريب كيفية تنعيم الإشارات على الرسم البياني. تساعد هذه العملية النموذج على التركيز على الاتصالات المتسقة والمهمة بين العينات — مثل الإشارات العاطفية المتكررة عبر مقاطع مختلفة — دون التشتت بتقلبات عشوائية أو بيانات مفقودة.
تعلّم الأنماط على مقاييس متعددة
بعد التصفية، يُدخل AGSP-DSA إشارات الرسم البياني في طبقة من شبكات الالتفاف البياني، وهي شبكات عصبية متخصصة مصممة للبيانات ذات شكل الرسم البياني. تتيح كل طبقة للعقدة تحديث تمثيلها بخلط معلومات من جيرانها، بداية من النقاط القريبة ثم تدريجيًا من الأبعد. من خلال تكديس عدة طبقات، يتعلم النظام أنماطًا على مقاييس متعددة: تفاصيل محلية مثل تغيّرات دقيقة في النبرة، وكذلك اتجاهات أوسع تمتد عبر العديد من العينات. تدمج المخرجات من الرسم الذي يعيش داخل كل نمط ومن الرسم الذي يربط الأنماط معًا، منتجة تمثيلات غنية ترمز للعلاقات الدقيقة والعامة بين الصور والأصوات والكلمات.
ترك البيانات تحدد أي نمط أكثر أهمية
تتمثل تحديات رئيسية في التعلم متعدد الوسائط في أن كل مصدر ليس مفيدًا بالقدر نفسه طوال الوقت. أحيانًا تعبر التعابير الوجهية عن الرسالة؛ وأحيانًا تهيمن نبرة الصوت أو النص. يتعامل AGSP-DSA مع هذا من خلال آلية انتباه واعية دلاليًا. لكل عينة، يقارن ميزات كل نمط بمِرسى دلالي، مثل تسمية الهدف أو ملخص المعنى، ويمنح وزنًا يعكس مدى إفادة ذلك النمط في السياق. ثم خطوة بوّابة تضبط هذه المساهمات أكثر، مما يسمح للنظام بتقليل شأن الإشارات غير الموثوقة أو المفقودة. يُغذى التمثيل المندمج والموزون بالانتباه إلى طبقة تنبؤ نهائية يمكنها التعامل مع مهام مثل تصنيف المشاعر، والتعرف على الأحداث، أو وسم نوع الفيلم.
الأداء في العالم الحقيقي
اختُبر الإطار على ثلاث مجموعات بيانات معيارية متطلبة: مجموعة كبيرة من فيديوهات الرأي لتحليل المشاعر والعاطفة (CMU-MOSEI)، ومجموعة بيانات للأحداث الصوتية البصرية (AVE)، ومجموعة أفلام تجمع بين الملصقات وملخصات الحبكة (MM-IMDb). عبر جميعها، يتفوق AGSP-DSA على طرق الاندماج التقليدية والمنافسين الحديثين القائمين على المحولات أو الرسم البياني. يصل إلى أكثر من 95% دقة في تصنيف المشاعر، ومكاسب قوية مماثلة في كشف الأحداث وتوقع نوع الفيلم. والأهم أن الطريقة تظل قوية عندما تكون بعض الأنماط مفقودة جزئيًا أو مطعّمة بالضجيج، وتفعل ذلك دون تكبُّد تكلفة حسابية مفرطة. تُظهر التجارب المتكررة أن أدائها مستقر ولا يعتمد على اختيارات عشوائية محظوظة أثناء التدريب.
ماذا يعني هذا لأنظمة الذكاء الاصطناعي اليومية
بالمعنى العملي، يقدم AGSP-DSA وسيلة أذكى لأنظمة الذكاء الاصطناعي للاستماع والمشاهدة والقراءة في آن واحد، مع البقاء مرنة عندما يفشل أحد هذه القنوات. من خلال تمثيل البيانات متعددة الوسائط كرُسوم مترابطة، وتنقية الإشارات التي تتدفق عبرها، وترك النموذج يقرر ديناميكيًا أي نمط يَستحق الثقة، يوفر هذا النهج قرارات أكثر دقة وموثوقية. يجعل ذلك منه لبنة واعدة لتطبيقات مستقبلية مثل المساعدين الافتراضيين الواعيين بالمشاعر، والمراقبة الفيديوية القوية، وتوصية المحتوى الأكثر ثراء، وأنظمة أخرى يجب أن تفهم تدفقات وسائط متعددة معقدة وغير كاملة.
الاستشهاد: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
الكلمات المفتاحية: الاندماج متعدد الوسائط, شبكات الرسم البياني العصبية, تحليل المشاعر, الأحداث الصوتية البصرية, تصنيف الوسائط المتعددة