Clear Sky Science · ja
動的意味整合を伴う適応型グラフ信号処理によるロバストなマルチモーダル融合
視覚・音声・言葉を組み合わせる意義
今日のデジタル世界の多くは、字幕付き映画予告編やコメント付きソーシャルメディアクリップなど、映像・音声・テキストが入り混じったリッチな混合物でできています。会話中の感情認識、映像内イベント検出、映画の推薦といったタスクでコンピュータにこの複雑な混合情報を理解させることは重要です。しかし実際のデータは雑多で、音声が欠けることがあったり、画像がノイズを含んだり、テキストが曖昧だったりします。本論文は、こうした不確実性や欠損があっても、異なる種類の情報を柔軟に組み合わせて状況を把握できるようにする新しい手法を提示します。
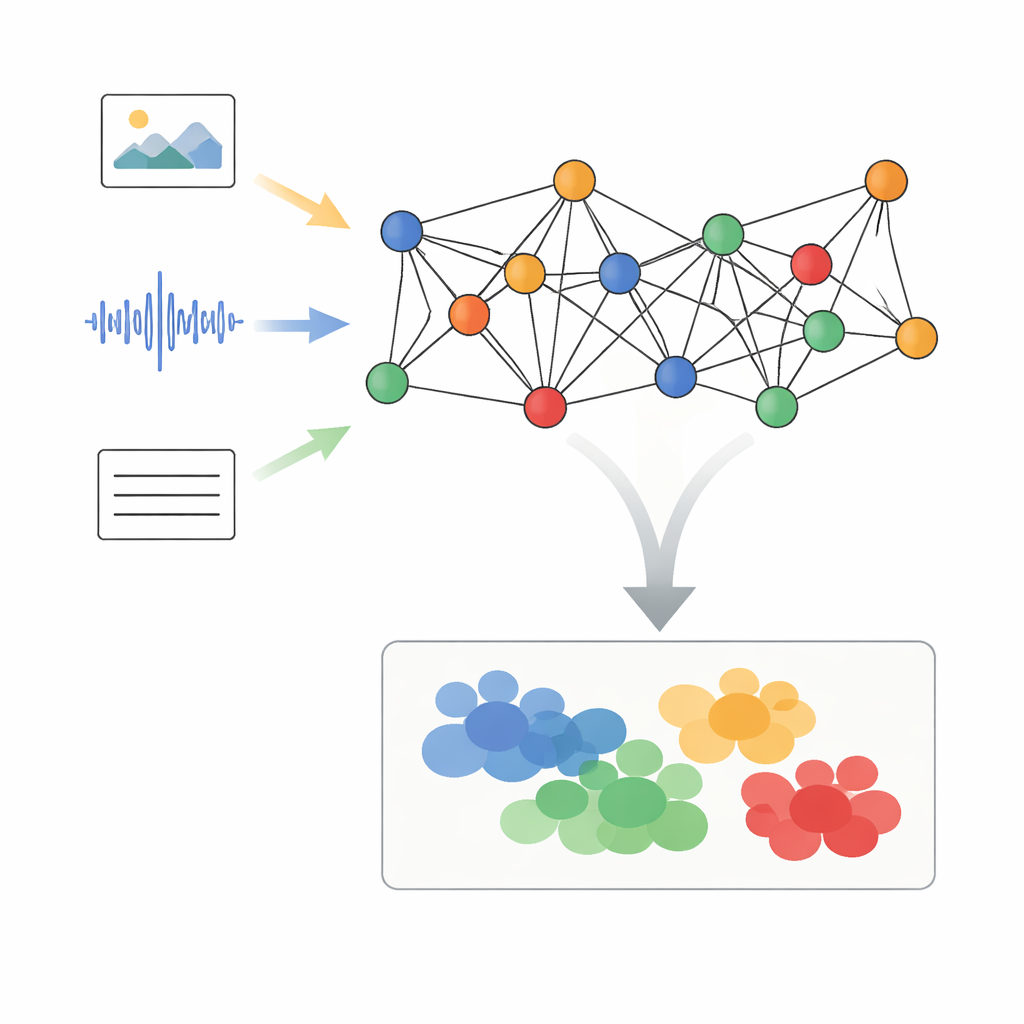
混合メディアをつながった点として表現する
著者らは、Adaptive Graph Signal Processing with Dynamic Semantic Alignment(AGSP-DSA)と呼ぶフレームワークを提案します。これは各データ片をネットワークの一部として扱うものです。まず既存の強力なツールが各モダリティから特徴を抽出します:画像ネットワークが視覚情報を要約し、音声ネットワークが音をまとめ、言語モデルがテキストを処理します。これらの特徴を単に積み上げるのではなく、AGSP-DSAはそれらを二つの関連するグラフのノードとして配置します。一方のグラフは同一モダリティ内で類似するサンプルをつなぎます—たとえば見た目が似ているビデオクリップ。同時にもう一方のグラフは、悲しげな声と陰鬱な表情のように意味を共有する異なるモダリティ間のサンプルを結びます。この二重のグラフ表現により、各データ型内の構造とそれらを横断する関係の両方を追跡できます。
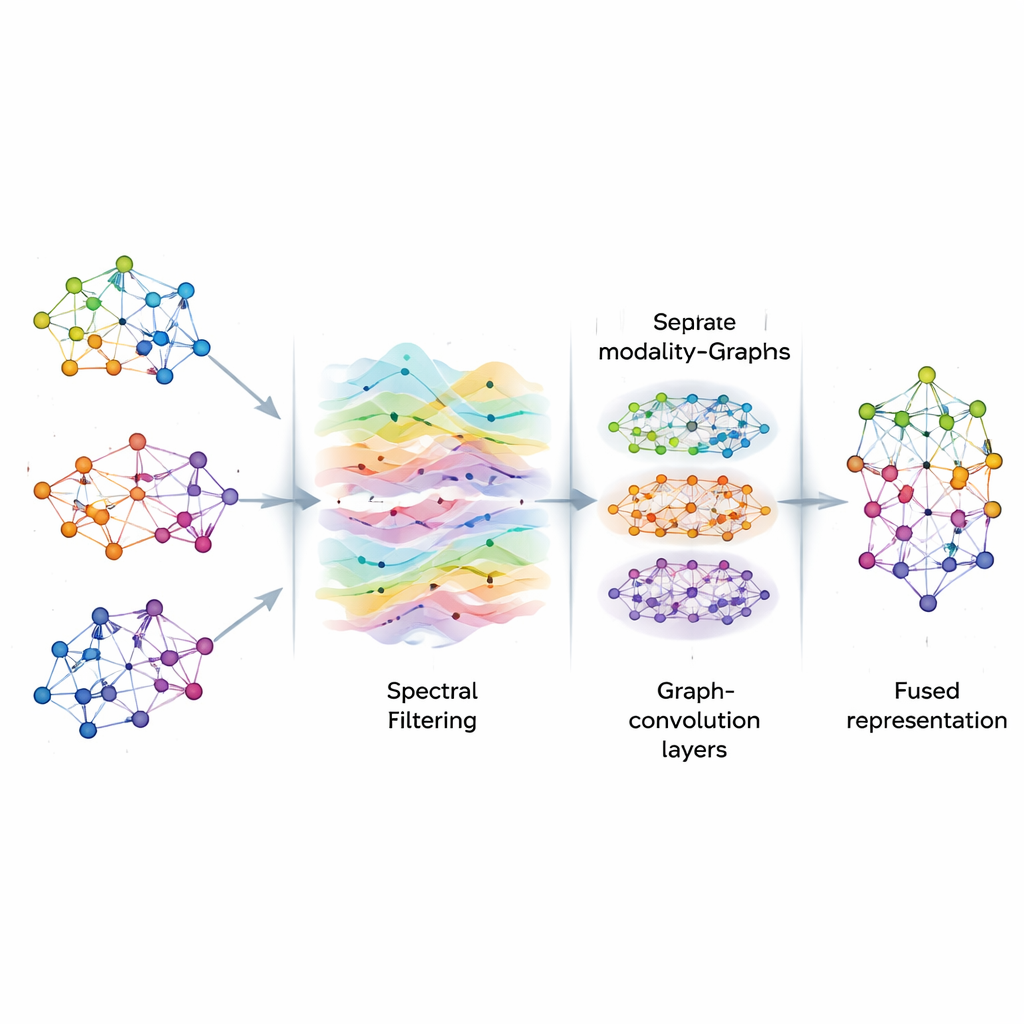
グラフ上の信号を洗練する
グラフが構築されると、AGSP-DSAはその上の情報をネットワーク内を流れる信号のように扱います。これは音波が空気中を伝わる様子に似ています。グラフ信号処理のツールを用いて、役に立つパターンを強調しノイズを低減するスマートなフィルタリングを行います。高価な行列演算を直接計算する代わりに、チェビシェフ多項式に基づく数式的な近似を用いて、グラフ上で信号をどのように平滑化すべきかを効率的に推定します。この処理により、ランダムな変動や欠損データに惑わされず、異なるクリップ間で繰り返し現れる感情の手がかりのような一貫した有意なつながりにモデルが注目できるようになります。
多重スケールでパターンを学ぶ
フィルタリングの後、AGSP-DSAはグラフ信号を複数の層からなるグラフ畳み込みネットワーク(GCN)に入力します。GCNはグラフ構造化データ向けに設計された特殊なニューラルネットワークです。各層でノードは近隣からの情報を混ぜて自身の表現を更新し、まずは局所の点から始まり、次第により遠い点からの情報を取り入れます。複数の層を積むことで、微細な音調の変化のような局所的な詳細から、多くのサンプルにまたがる広範な傾向まで、複数のスケールでパターンを学習します。各モダリティ内に存在するグラフからの出力とモダリティ間を結ぶグラフからの出力を組み合わせることで、画像・音声・言葉の間の細かな関係性と全体的な関係性の両方を符号化した豊かな表現が得られます。
どのモダリティが重要かをデータに決めさせる
マルチモーダル学習の重要な課題は、すべての情報源が常に同じように有用とは限らない点です。時には表情が主要な手がかりとなり、別の時は声のトーンやテキストが支配的になることがあります。AGSP-DSAは意味認識型のアテンション機構でこれに対処します。各サンプルについて、各モダリティの特徴を目標ラベルや意味の要約といった意味的アンカーと比較し、そのコンテクストにおいてどれだけ情報を与えるかを反映する重みを割り当てます。さらにゲーティング段階でこれらの寄与を調整し、不確実または欠落した信号を抑えることができます。こうして融合されアテンションで重み付けされた表現は、感情分類、イベント認識、映画のジャンル分類などのタスクを扱う最終的な予測層に入力されます。
実世界での性能
このフレームワークは、感情・情動解析向けの大規模意見ビデオコレクション(CMU-MOSEI)、音声・映像イベントデータセット(AVE)、ポスターとあらすじを組み合わせた映画コレクション(MM-IMDb)という三つの厳しいベンチマークで評価されました。いずれのデータセットでも、AGSP-DSAは従来の融合方法や最新のトランスフォーマー系・グラフ系の競合手法を上回りました。感情分類では95%以上の精度を達成し、イベント検出や映画ジャンル予測でも同様に大きな向上を示しています。重要なのは、いくつかのモダリティが部分的に欠けているかノイズがある場合でも手法が堅牢であり、また過度な計算コストを伴わない点です。繰り返しの実験により、その性能は安定しており、学習時の運の良い乱択に依存しないことが示されています。
日常のAIシステムにとっての意味
日常的な観点から見ると、AGSP-DSAはAIシステムが同時に聞き、見、読み取るためのより賢い方法を提供し、いずれかのチャネルが失敗しても耐性を保ちます。マルチモーダルデータを相互接続されたグラフとして表現し、それらを流れる信号を洗練し、どのモダリティを信頼するかをモデルが動的に判断できるようにすることで、より正確で信頼できる意思決定をもたらします。これは感情に配慮する仮想アシスタント、堅牢な映像監視、より豊かなコンテンツ推薦、複雑で不完全なマルチメディアストリームを理解する必要があるその他のシステムなど、将来の応用にとって有望な構成要素となります。
引用: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
キーワード: マルチモーダル融合, グラフニューラルネットワーク, 感情分析, 音声・映像イベント, マルチメディア分類