Clear Sky Science · pt
Processamento adaptativo de sinais em grafos para fusão multimodal robusta com alinhamento semântico dinâmico
Por que combinar imagens, sons e palavras importa
Grande parte do mundo digital atual é formada por misturas ricas de vídeo, áudio e texto — de trailers de filmes com legendas a clipes de redes sociais com comentários. Ensinar computadores a entender essa combinação emaranhada é crucial para tarefas como reconhecer emoções em conversas, detectar eventos em vídeos ou recomendar filmes. Mas os dados reais são imperfeitos: às vezes o áudio está ausente, as imagens estão ruidosas ou o texto é vago. Este artigo apresenta uma nova forma de permitir que computadores combinem tipos diferentes de informação de maneira flexível para que ainda consigam compreender o que acontece mesmo quando alguns elementos são pouco confiáveis ou estão ausentes.
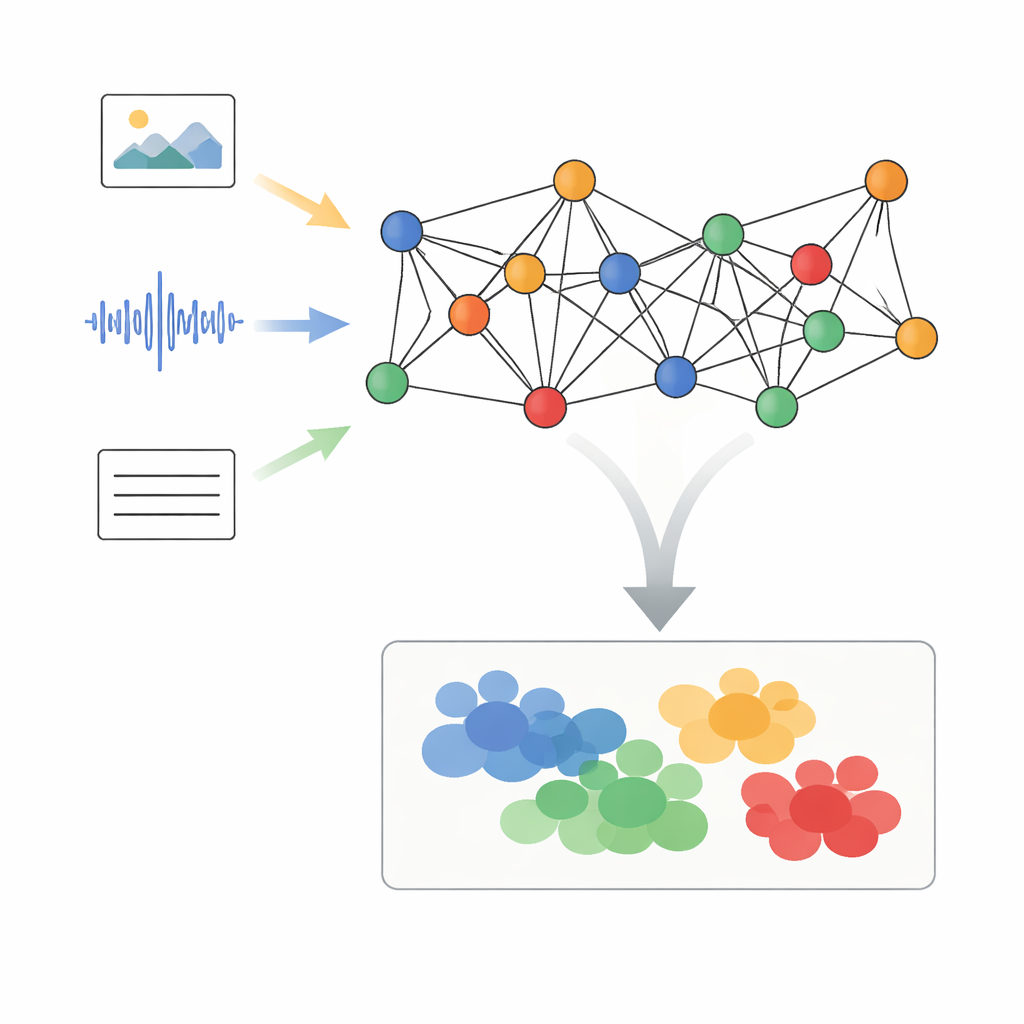
Transformando mídia mista em pontos conectados
Os autores propõem uma estrutura chamada Processamento Adaptativo de Sinais em Grafos com Alinhamento Semântico Dinâmico, ou AGSP-DSA, que trata cada pedaço de dado como parte de uma rede. Primeiro, ferramentas poderosas existentes extraem características de cada modalidade: redes para imagem resumem o visual, redes de áudio sintetizam sons e modelos de linguagem processam o texto. Em vez de simplesmente empilhar essas características, o AGSP-DSA as organiza como nós em dois grafos relacionados. Um grafo conecta amostras que são semelhantes dentro da mesma modalidade — por exemplo, clipes de vídeo que se parecem. O outro grafo liga amostras entre modalidades que compartilham significado, como uma voz com tom triste associada a uma expressão facial melancólica. Essa visão de grafos duais permite ao sistema acompanhar tanto a estrutura dentro de cada tipo de dado quanto as relações que os atravessam.
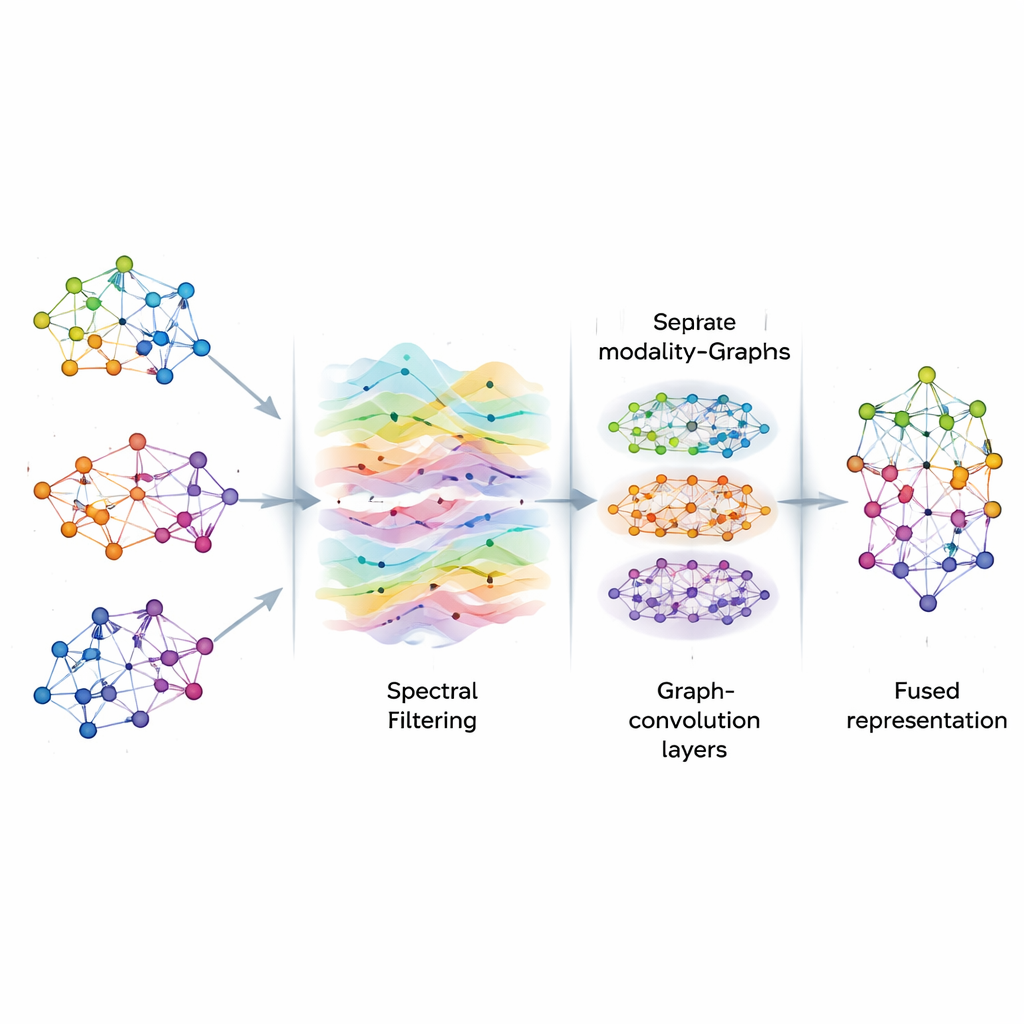
Purificando sinais no grafo
Uma vez construídos os grafos, o AGSP-DSA trata a informação neles como sinais fluindo por uma rede, de modo semelhante ao movimento de ondas sonoras no ar. Usando ferramentas de processamento de sinais em grafos, realiza uma espécie de filtragem inteligente, enfatizando padrões úteis enquanto reduz o ruído. Em vez de calcular diretamente operações matriciais caras, o método usa atalhos matemáticos baseados em polinômios de Chebyshev para aproximar como os sinais devem ser suavizados no grafo. Esse processo ajuda o modelo a focar em conexões consistentes e significativas entre amostras — como pistas emocionais repetidas em diferentes clipes — sem se distrair com flutuações aleatórias ou dados faltantes.
Aprendendo padrões em múltiplas escalas
Após a filtragem, o AGSP-DSA alimenta os sinais do grafo em uma pilha de Redes Convolucionais em Grafos, que são redes neurais especializadas para dados em formato de grafo. Cada camada permite que um nó atualize sua representação combinando informações de seus vizinhos, primeiro de pontos próximos e então gradualmente de pontos mais distantes. Ao empilhar várias camadas, o sistema aprende padrões em múltiplas escalas: detalhes locais como mudanças sutis de entonação, bem como tendências mais amplas que abrangem muitas amostras. As saídas do grafo que vive dentro de cada modalidade e do grafo que conecta as modalidades são combinadas, produzindo representações ricas que codificam tanto relações de grão fino quanto relações globais entre imagens, sons e palavras.
Deixando os dados decidirem qual modalidade importa mais
Um desafio chave na aprendizagem multimodal é que nem toda fonte é igualmente útil o tempo todo. Às vezes a expressão facial carrega a mensagem; em outras ocasiões, o tom de voz ou o texto dominam. O AGSP-DSA aborda isso com um mecanismo de atenção sensível ao semântico. Para cada amostra, ele compara as características de cada modalidade com uma âncora semântica, como o rótulo alvo ou um resumo de significado, e atribui um peso que reflete o quão informativa aquela modalidade é no contexto. Uma etapa de gating então ajusta ainda mais essas contribuições, permitindo que o sistema reduza a influência de sinais pouco confiáveis ou ausentes. A representação fundida, ponderada por atenção, é enviada a uma camada de predição final que pode lidar com tarefas como classificação de sentimento, reconhecimento de eventos ou rotulação de gêneros de filmes.
Desempenho no mundo real
A estrutura é testada em três conjuntos de referência exigentes: uma grande coleção de vídeos de opiniões para análise de sentimento e emoção (CMU-MOSEI), um conjunto de eventos áudio-visuais (AVE) e uma coleção de filmes que combina pôsteres e resumos de enredo (MM-IMDb). Em todos eles, o AGSP-DSA supera tanto métodos tradicionais de fusão quanto concorrentes modernos baseados em transformers e grafos. Alcança mais de 95% de acurácia na classificação de sentimento, e ganhos igualmente fortes para detecção de eventos e previsão de gêneros de filmes. Importante, o método permanece robusto quando algumas modalidades estão parcialmente ausentes ou ruidosas, e faz isso sem incorrer em custo computacional proibitivo. Experimentos repetidos mostram que seu desempenho é estável e não depende de escolhas aleatórias favoráveis durante o treinamento.
O que isso significa para sistemas de IA do dia a dia
Em termos cotidianos, o AGSP-DSA oferece uma maneira mais inteligente para sistemas de IA ouvirem, olharem e lerem ao mesmo tempo, mantendo-se resilientes quando um desses canais falha. Ao representar dados multimodais como grafos interconectados, limpar os sinais que fluem por eles e permitir que o modelo decida dinamicamente em qual modalidade confiar, a abordagem entrega decisões mais precisas e confiáveis. Isso a torna um bloco de construção promissor para aplicações futuras, como assistentes virtuais sensíveis a emoções, vigilância de vídeo robusta, recomendações de conteúdo mais ricas e outros sistemas que precisam interpretar fluxos multimídia complexos e imperfeitos.
Citação: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Palavras-chave: fusão multimodal, redes neurais em grafos, análise de sentimento, eventos áudio-visuais, classificação multimídia