Clear Sky Science · tr
Dinamik anlamsal hizalamayla sağlam çok modlu füzyon için uyarlanabilir grafik sinyal işleme
Neden görüntüleri, sesleri ve kelimeleri birleştirmek önemli
Bugünün dijital dünyasının çoğu, altyazılı film fragmanlarından yorumlu sosyal medya kliplerine kadar video, ses ve metnin zengin karışımlarından oluşuyor. Bilgisayarlara bu karmaşık karışımı anlamayı öğretmek, konuşmalardaki duyguları tanımak, videolardaki olayları tespit etmek veya film önermek gibi görevler için kritik önemde. Ancak gerçek veriler düzensizdir: bazen ses eksik olur, görüntüler gürültülüdür veya metin belirsizdir. Bu makale, bazı parçalar güvenilmez veya yok olduğunda bile bilgisayarların ne olduğunu esnek biçimde anlayabilmesini sağlayan yeni bir yöntem sunuyor.
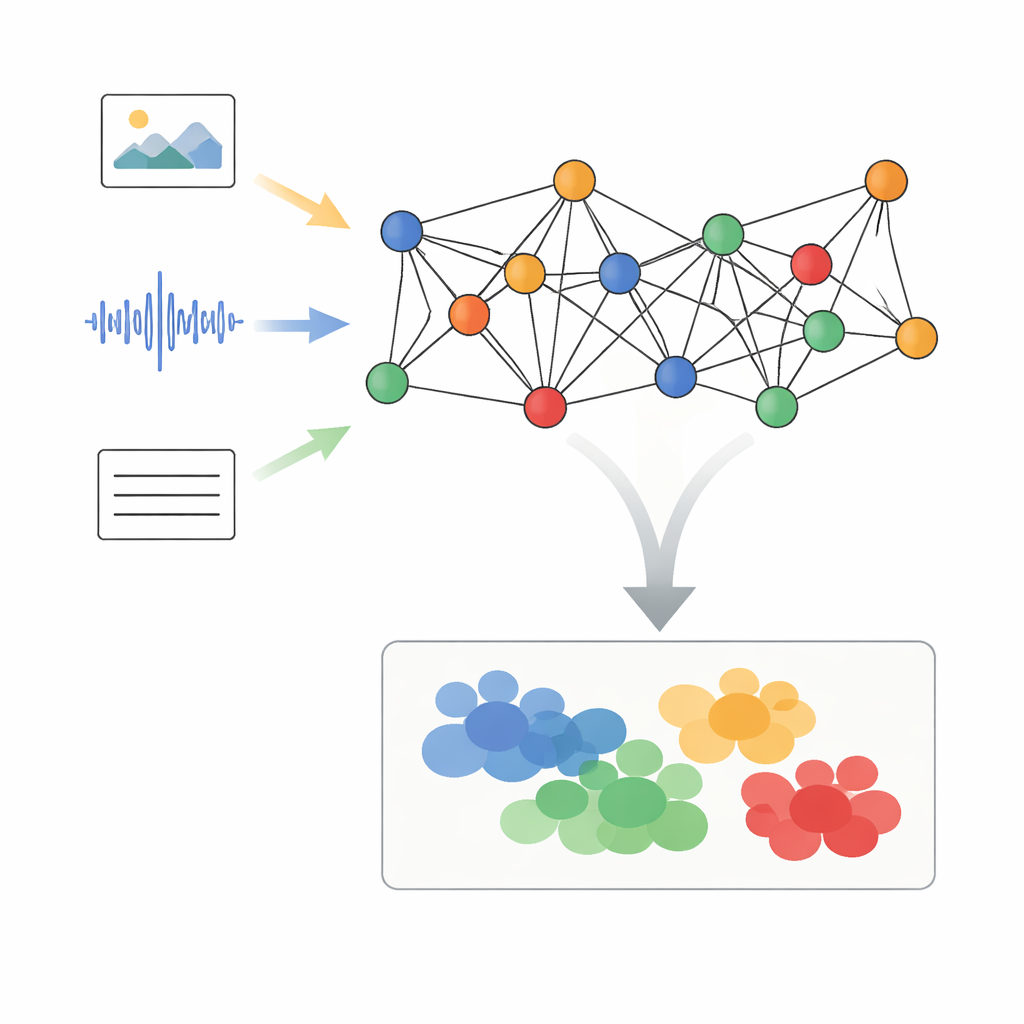
Karma medyayı bağlantılı noktalara dönüştürmek
Yazarlar, her veri parçasını bir ağın parçası olarak ele alan Uyarlanabilir Grafik Sinyal İşleme ile Dinamik Anlamsal Hizalama (AGSP-DSA) adlı bir çerçeve öneriyor. Önce, güçlü mevcut araçlar her modaliteden özellikler çıkarıyor: görselleri görüntü ağları sindiriyor, sesleri ses ağları özetliyor ve dil modelleri metni işliyor. Bu özellikleri basitçe üst üste koymak yerine, AGSP-DSA bunları iki ilişkili grafikte düğümler olarak düzenliyor. Bir grafik aynı modalite içinde benzer olan örnekleri birbirine bağlıyor—örneğin birbirine benzeyen video klipler. Diğer grafik ise anlam paylaşan modaliteler arası örnekleri bağlıyor; örneğin üzgün tonda bir ses ile kasvetli bir yüz ifadesi eşleştirilebilir. Bu çift grafik bakışı, sistemin her veri türü içindeki yapıyı ve bunları aşan ilişkileri aynı anda takip etmesini sağlıyor.
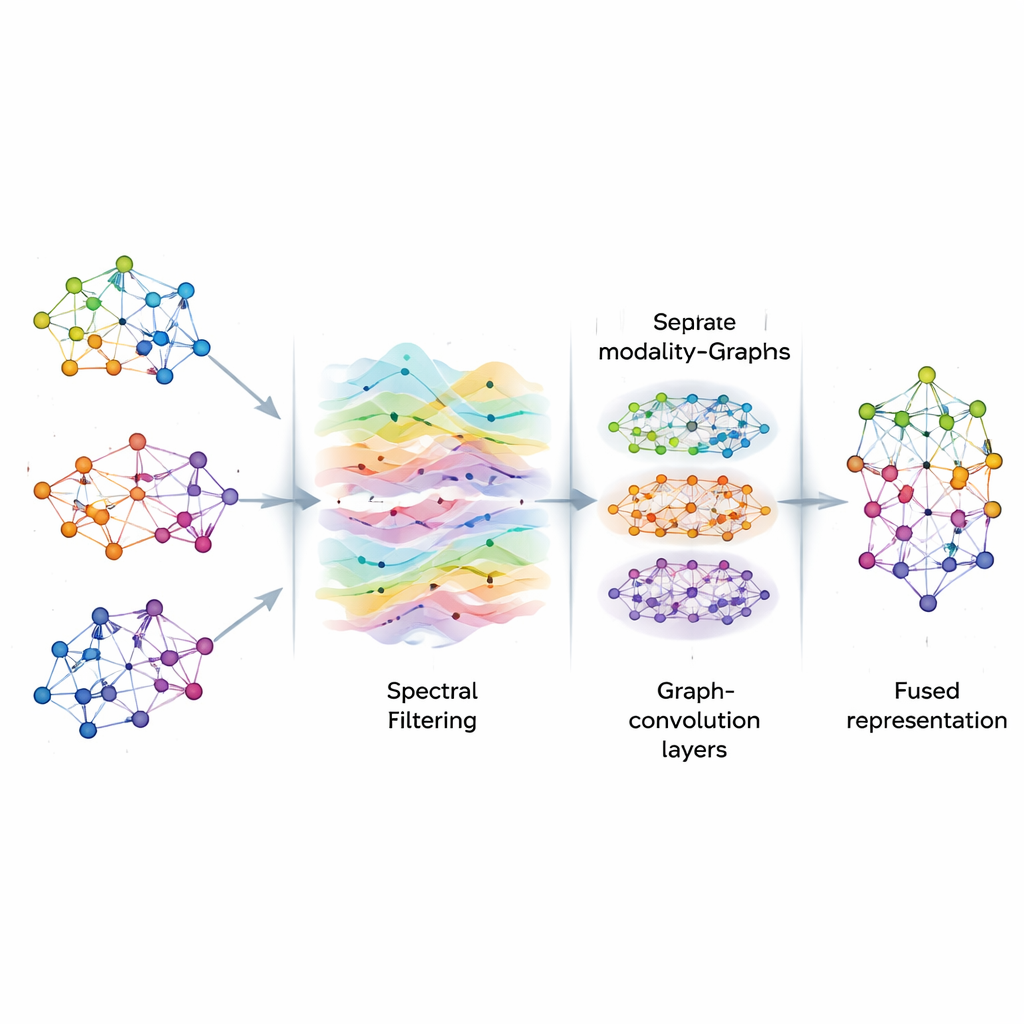
Grafikteki sinyalleri temizlemek
Grafikler kurulduktan sonra, AGSP-DSA üzerlerindeki bilgileri ağda akan sinyaller gibi ele alıyor; bu, ses dalgalarının havada hareket etmesine benzetilebilir. Grafik sinyal işleme araçlarını kullanarak yararlı desenleri vurgulayan ve gürültüyü azaltan akıllı bir filtreleme gerçekleştiriyor. Doğrudan pahalı matris işlemleri hesaplamak yerine, yöntem sinyallerin grafikte nasıl düzgünleştirileceğini yaklaşık olarak belirlemek için Chebyshev polinomlarına dayanan matematiksel kestirmeler kullanıyor. Bu süreç, modelin farklı kliplerdeki tekrar eden duygusal ipuçları gibi tutarlı, anlamlı bağlantılara odaklanmasına yardımcı oluyor ve rastgele dalgalanmalardan veya eksik verilerden etkilenmesini azaltıyor.
Çok ölçekli desenleri öğrenmek
Filtrelemeden sonra AGSP-DSA, grafik sinyallerini grafik şeklindeki veriler için tasarlanmış uzmanlaşmış sinir ağları olan Grafik Konvolüsyon Ağları katmanlarına besliyor. Her katman bir düğümün temsilini, önce yakın noktalar daha sonra giderek daha uzak olan komşularından gelen bilgileri harmanlayarak güncellemesine izin veriyor. Birkaç katman üst üste konulduğunda sistem hem yakın ayrıntılar (örneğin tonlamadaki ince değişimler) hem de birçok örneği kapsayan daha geniş eğilimler gibi çok ölçekli desenleri öğreniyor. Her modalite içinde yaşayan grafik ile modaliteleri birbirine bağlayan grafikten çıkan çıktılar birleştirilerek görüntüler, sesler ve kelimeler arasındaki hem ayrıntılı hem de küresel ilişkileri kodlayan zengin temsiller üretiliyor.
Hangi modalitenin daha önemli olduğuna verinin karar vermesine izin vermek
Çok modlu öğrenmedeki temel zorluklardan biri her kaynağın her zaman aynı derecede yararlı olmamasıdır. Bazen yüz ifadeleri mesajı taşır; diğer zamanlarda sesin tonu veya metin ön plana çıkar. AGSP-DSA bunu anlamsal farkındalıklı bir dikkat mekanizması ile ele alıyor. Her örnek için, her modaliteden gelen özellikleri hedef etiket veya anlamın bir özeti gibi bir anlamsal çapa karşı karşılaştırıyor ve o bağlamda o modalitenin ne kadar bilgilendirici olduğunu yansıtan bir ağırlık atıyor. Ardından bir kapılama aşaması bu katkıları daha da ayarlayarak sistemin güvenilmez veya eksik sinyalleri küçümsemesine izin veriyor. Birleştirilmiş ve dikkat-ağırlıklı temsil, duygu sınıflandırma, olay tanıma veya film türü etiketleme gibi görevleri yerine getirebilen son bir tahmin katmanına besleniyor.
Gerçek dünyadaki performans
Çerçeve üç zorlu kıyas veri kümesinde test ediliyor: duygu ve his analizi için büyük bir görüş videoları koleksiyonu (CMU-MOSEI), bir ses-görüntü olay veri kümesi (AVE) ve afişlerle özetleri birleştiren bir film koleksiyonu (MM-IMDb). Hepsinde AGSP-DSA hem geleneksel füzyon yöntemlerini hem de modern dönüşümcü (transformer) ve grafik tabanlı rakipleri geride bırakıyor. Duygu sınıflandırmasında %95’in üzerinde doğruluk ve olay tespiti ile film türü tahmininde benzer güçlü kazanımlar elde ediyor. Önemli olarak, yöntem bazı modaliteler kısmen eksik veya gürültülü olduğunda bile sağlam kalıyor ve bunu aşırı hesaplama maliyeti olmadan başarıyor. Tekrarlanan deneyler performansının istikrarlı olduğunu ve eğitim sırasında rastgele şansa bağlı olmadığını gösteriyor.
Günlük AI sistemleri için bunun anlamı
Günlük terimlerle, AGSP-DSA’ya aynı anda dinlemesi, izlemesi ve okuması için AI sistemlerine daha akıllı bir yol sunuyor; bir kanaldan biri başarısız olduğunda bile dayanıklı kalıyor. Çok modlu verileri birbirine bağlı grafikler olarak temsil ederek, bu grafiklerde akan sinyalleri temizleyerek ve modelin hangi modaliteye güveneceğine dinamik olarak karar vermesine izin vererek yaklaşım daha doğru ve güvenilir kararlar sağlıyor. Bu, duygu farkında sanal asistanlar, sağlam video gözetimi, daha zengin içerik önerileri ve karmaşık, kusurlu multimedya akışlarını anlaması gereken diğer sistemler gibi gelecekteki uygulamalar için umut verici bir yapı taşı yapıyor.
Atıf: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Anahtar kelimeler: çok modlu füzyon, graf sinir ağları, duygu analizi, ses-görüntü olayları, multimedya sınıflandırma