Clear Sky Science · he
עיבוד אותות גרפי אדפטיבי למיזוג מולטי-ממודלי עמיד עם יישור סמנטי דינמי
למה חשוב לשלב ראייה, קול ומילים
רוב העולם הדיגיטלי של היום מורכב מתערובות עשירות של וידאו, אודיו וטקסט — מתזרימי טריילרים עם כתוביות ועד קטעים ברשתות החברתיות עם תגובות. ללמד מחשבים לפענח את התערובת המסובכת הזו הוא קריטי למשימות כגון זיהוי רגשות בשיחות, גילוי אירועים בסרטונים או המלצת סרטים. אבל נתונים אמיתיים מטושטשים: לפעמים האודיו חסר, התמונות רועשות או הטקסט עמום. מאמר זה מציג שיטה חדשה שמאפשרת למחשבים לשלב בצורה גמישה סוגי מידע שונים כדי שהם יוכלו עדיין להבין מה קורה גם כאשר חלק מהחלקים אינם מהימנים או חסרים.
להפוך מולטימדיה לנקודות מחוברות
המחברים מציעים מסגרת שנקראת עיבוד אותות גרפי אדפטיבי עם יישור סמנטי דינמי, או AGSP-DSA, המטפלת בכל חלקי הנתונים כחלק מרשת. ראשית, כלים חזקים קיימים מפיקים תכונות מכל מודליות: רשתות תמונה מעכלות חזות, רשתות אודיו מסכמות צלילים ומודלים לשוניים מעבדים טקסט. במקום פשוט לערום את התכונות האלה זו על גבי זו, AGSP-DSA מסדרת אותן כצמתים בשני גרפים קשורים. גרף אחד מחבר דגימות של דומה בתוך אותה מודליות — למשל קליפים וידאו שנראים דומים. הגרף השני מקשר דגימות בין מודליות שמשתפות משמעות, כמו קול שמישמע עצוב יחד עם הבעה פנים קודרת. המבנה הדו-גרפי הזה מאפשר למערכת לעקוב הן אחרי המבנה בתוך כל סוג נתונים והן אחרי הקשרים החוצים ביניהם.
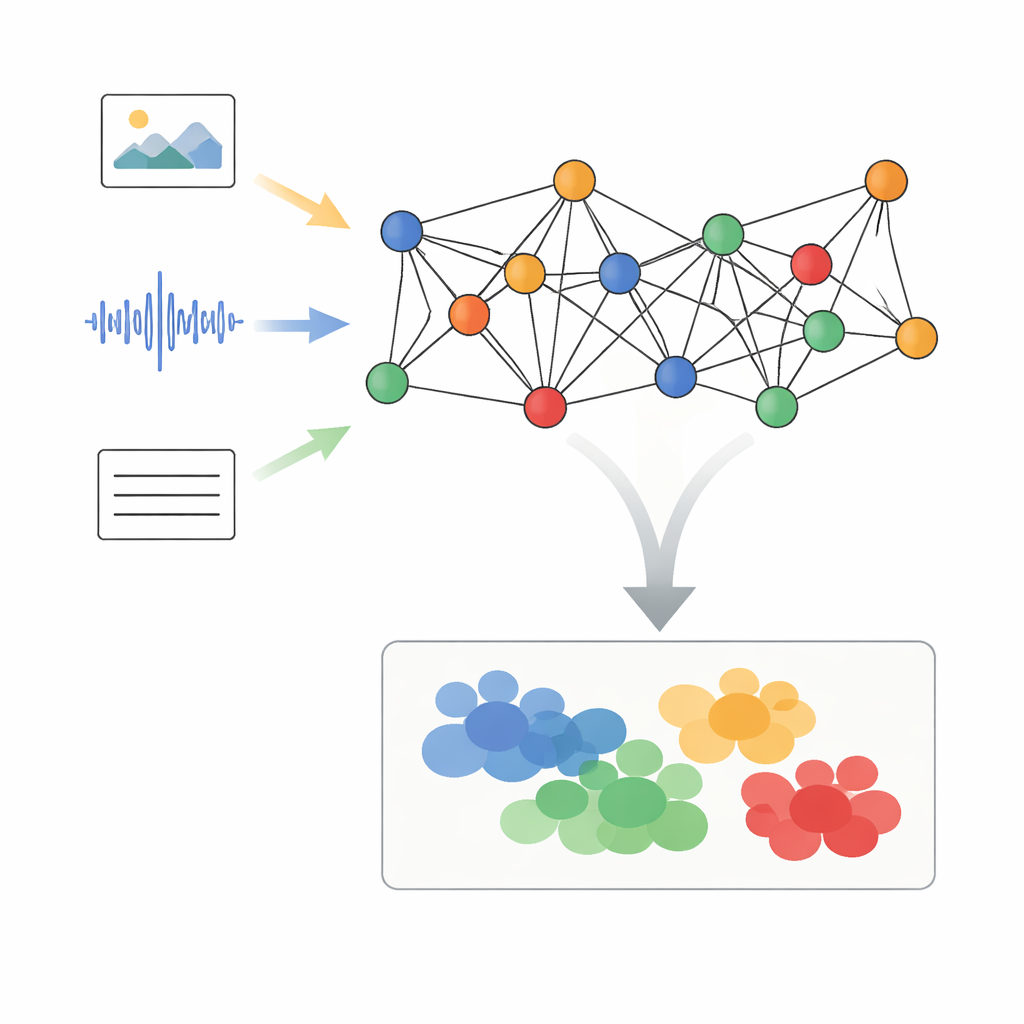
לנקות אותות על הגרף
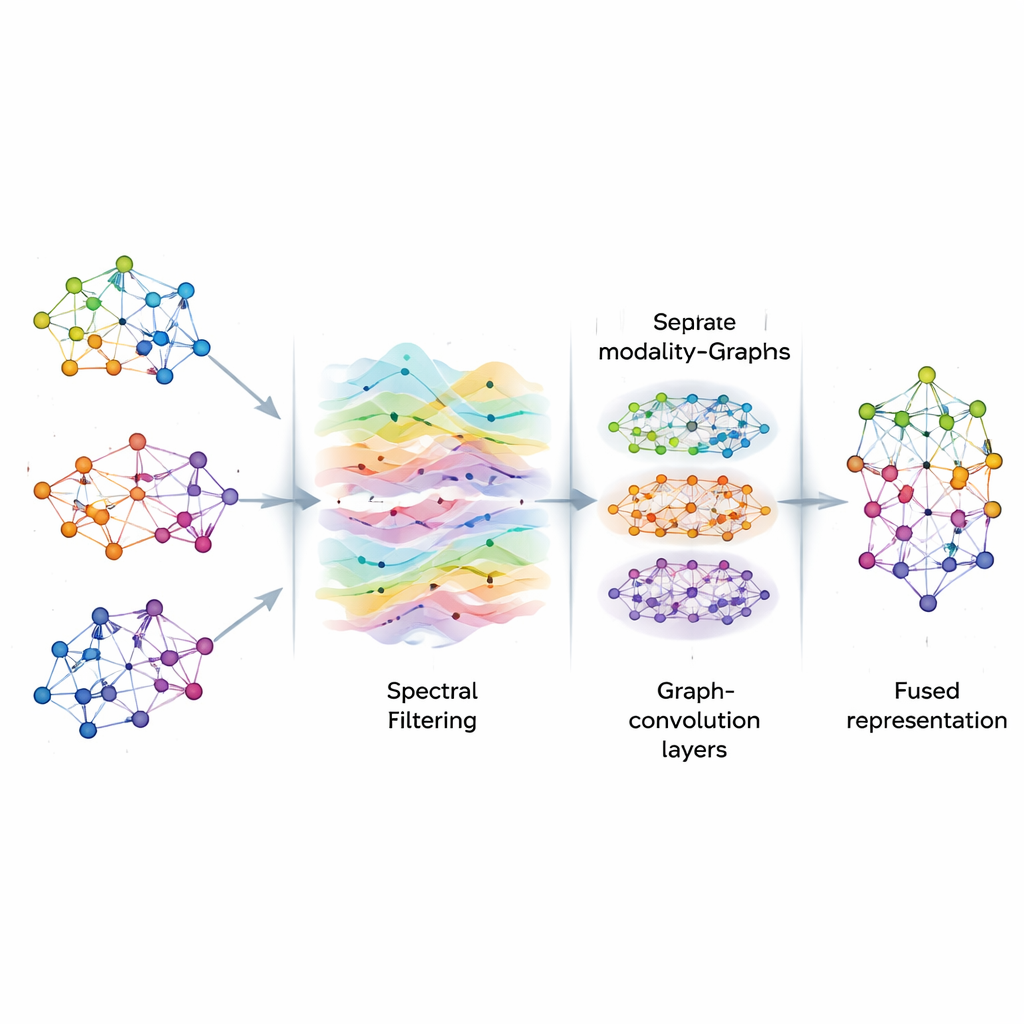
לאחר שהגרפים נבנים, AGSP-DSA מטפלת במידע עליהם כאילו הם אותות שזורמים דרך רשת, בדומה לאופן שבו גל קול נע באוויר. באמצעות כלים מעיבוד אותות גרפי, היא מבצעת סוג של סינון חכם, המדגיש דפוסים שימושיים ומקטין את הרעש. במקום לחשב ישירות פעולות מטריצתיות יקרות, השיטה משתמשת וקירובים מתמטיים המבוססים על פולינומי שבטשבישב (Chebyshev) כדי לאמוד כיצד האותות צריכים להתחלף ולהחלש על הגרף. התהליך הזה עוזר לדגם להתמקד בקשרים עקביים ומשמעותיים בין דגימות — כגון רמזים רגשיים חוזרים בקליפים שונים — מבלי להיסחף על ידי תהומות אקראיות או נתונים חסרים.
ללמוד דפוסים בקנה מידה מרובה
אחרי הסינון, AGSP-DSA מזינה את אותות הגרף לערמת רשתות קונבולוציה גרפיות (GCN), שהן רשתות נוירונים מיוחדות לנתונים בצורת גרף. כל שכבה מאפשרת לצמתים לעדכן את הייצוג שלהם על ידי ערבוב מידע מהשכנים שלהם, תחילה מנקודות קרובות ולאט לאט מנקודות מרוחקות יותר. על ידי ערימת מספר שכבות, המערכת לומדת דפוסים ברמות שונות: פרטים מקומיים כמו שינויים עדינים בטון, וכן מגמות רחבות החורגות על פני דגימות רבות. התוצאות מהגרף הפנימי של כל מודליות ומהגרף שקושר בין המודליות משולבות ליצירת ייצוגים עשירים שמקודדים הן קשרים דקים והן קשרים גלובליים בין תמונות, צלילים ומילים.
להניח לנתונים להכריע איזו מודליות חשובה יותר
אתגר מרכזי בלמידה מולטי-ממודלית הוא שלא כל מקור מידע שימושי בכל רגע נתון. לפעמים הבעות הפנים נושאות את המסר; פעמים אחרות הטון או הטקסט דומיננטיים. AGSP-DSA מטפלת בכך באמצעות מנגנון תשומת לב מודע-לסמנטיקה. עבור כל דגימה היא משווה את התכונות מכל מודליות לעוגן סמנטי, כגון תג יעד או סיכום משמעות, ומקצה משקל המשקף עד כמה אותה מודליות אינפורמטיבית בהקשר. שלב שער (gating) נוסף מכוונן עוד את התרומות הללו, ומאפשר למערכת להמעיט בחשיבות אותות בלתי מהימנים או חסרים. הייצוג הממוזג המשוקלל בתשומת לב מוזן לשכבת חיזוי סופית שיכולה לטפל במשימות כמו סיווג סנטימנט, זיהוי אירועים או תיוג ז'אנר סרטים.
ביצועים במציאות
המסגרת נבחנת בשלושה מערכי מבחן תובעניים: אוסף גדול של סרטוני דעה לניתוח סנטימנט ורגש (CMU-MOSEI), מאגר אירועים אודיו-ויזואליים (AVE) ואוסף סרטים המשלב פוסטרים וסיכומי עלילות (MM-IMDb). בכל המבחנים AGSP-DSA עולה על שיטות מיזוג מסורתיות ומתחרות מודרניות מבוססות טרנספורמרים וגרפים. היא מגיעה ליותר מ-95% דיוק בסיווג סנטימנט, וכן להשגים חזקים דומים בזיהוי אירועים ובחיזוי ז'אנר סרטים. חשוב מכך, השיטה נשארת עמידה כאשר חלק מהמודליות חסרים או רעשים חלקיים, ולעשות זאת בלי לגרור עלות חישובית אסטרונומית. ניסויים חוזרים מראים שביצועיה יציבים ואינם תלוים במזל של בחירות אקראיות במהלך האימון.
מה זה אומר למערכות בינה מלאכותית יום-יומיות
במונחים יומיומיים, AGSP-DSA מציעה דרך חכמה יותר למערכות בינה מלאכותית להקשיב, לצפות ולקרוא בו-זמנית, תוך שמירה על רזיליינס כאשר אחד הערוצים נכשל. על ידי ייצוג נתונים מולטי-ממודליים כגרפים מקושרים, ניקוי האותות שזורמים בהם ולאפשר למודל להכריע באופן דינמי באיזו מודליות לסמוך, הגישה מספקת החלטות מדויקות ואמינות יותר. זה הופך אותה לאבן בניין מבטיחה ליישומים עתידיים כגון עוזרים וירטואליים רגישי רגש, תצפית וידאו עמידה, המלצות תוכן עשירות ומערכות אחרות שחייבות לפענח זרמי מולטימדיה מורכבים וחסרי-מושלמות.
ציטוט: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
מילות מפתח: מיזוג מולטי-ממודלי, רשתות עצביות גרפיות, ניתוח סנטימנט, אירועים אודיו-ויזואליים, סיווג מולטימדיה