Clear Sky Science · sv
Adaptiv grafsignalsbehandling för robust multimodal fusion med dynamisk semantisk justering
Varför det spelar roll att kombinera bilder, ljud och ord
Mycket av dagens digitala värld består av rika blandningar av video, ljud och text — från filmaffischer med undertexter till korta sociala medier-klipp med kommentarer. Att lära datorer att tolka denna sammanflätade mix är avgörande för uppgifter som att känna igen känslor i samtal, upptäcka händelser i videor eller rekommendera filmer. Men verkliga data är röriga: ibland saknas ljud, bilder är brusiga eller texten är vag. Den här artikeln presenterar ett nytt sätt att låta datorer flexibelt kombinera olika typer av information så att de ändå kan förstå vad som händer även när vissa delar är opålitliga eller saknas.
Att omvandla blandade medier till sammanlänkade punkter
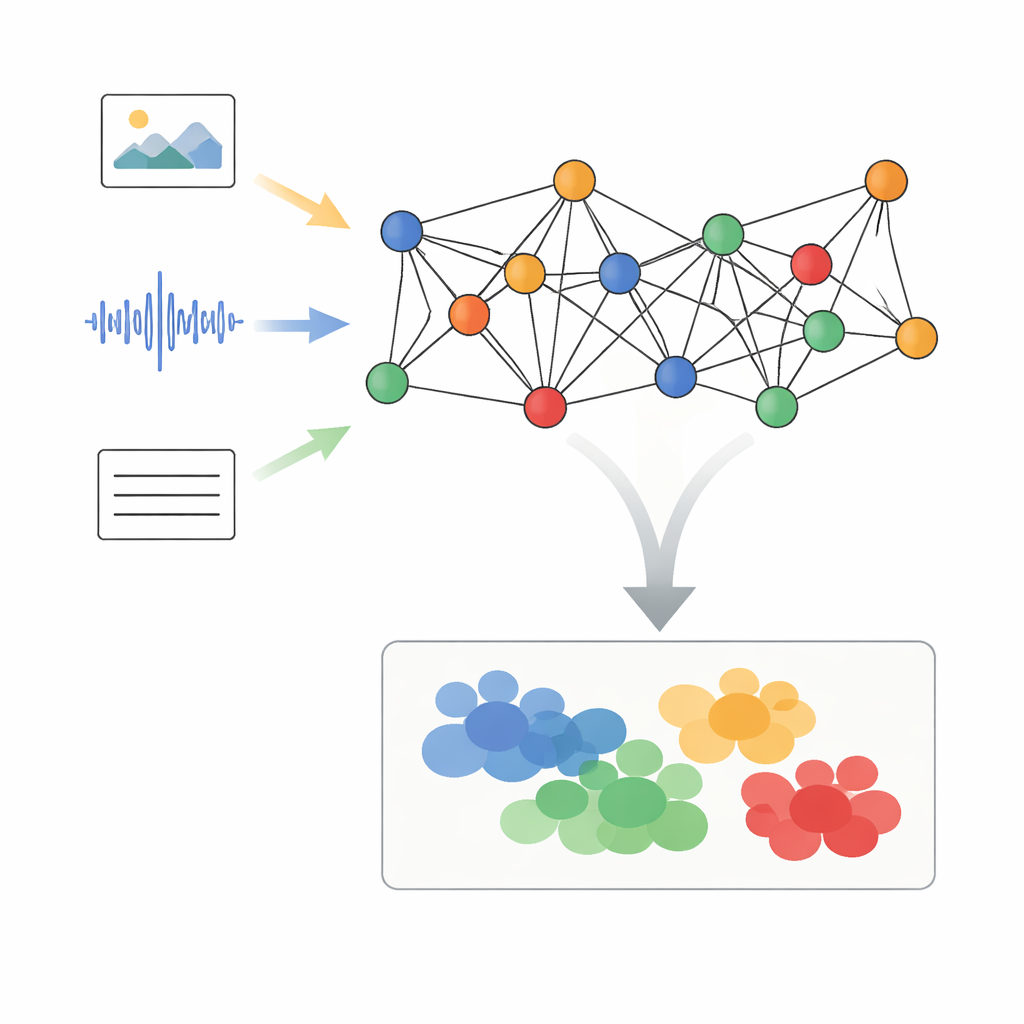
Författarna föreslår ett ramverk kallat Adaptive Graph Signal Processing with Dynamic Semantic Alignment, eller AGSP-DSA, som behandlar varje datapunkt som en del av ett nätverk. Först extraherar kraftfulla befintliga verktyg funktioner från varje modalitet: bildnätverk bearbetar visuellt innehåll, ljudnätverk summerar ljud och språkliga modeller hanterar text. Istället för att bara stapla dessa funktioner arrangerar AGSP-DSA dem som noder i två relaterade grafer. Den ena grafen kopplar samman prover som är lika inom samma modalitet — till exempel videoklipp som ser likadana ut. Den andra grafen länkar prover över modaliteter som delar betydelse, såsom en sorgsen röst i kombination med ett dämpat ansiktsuttryck. Denna dubbelgraf-syn tillåter systemet att hålla reda både på strukturen inom varje datatyp och på relationerna som spänner över dem.
Rensa upp signaler i grafen
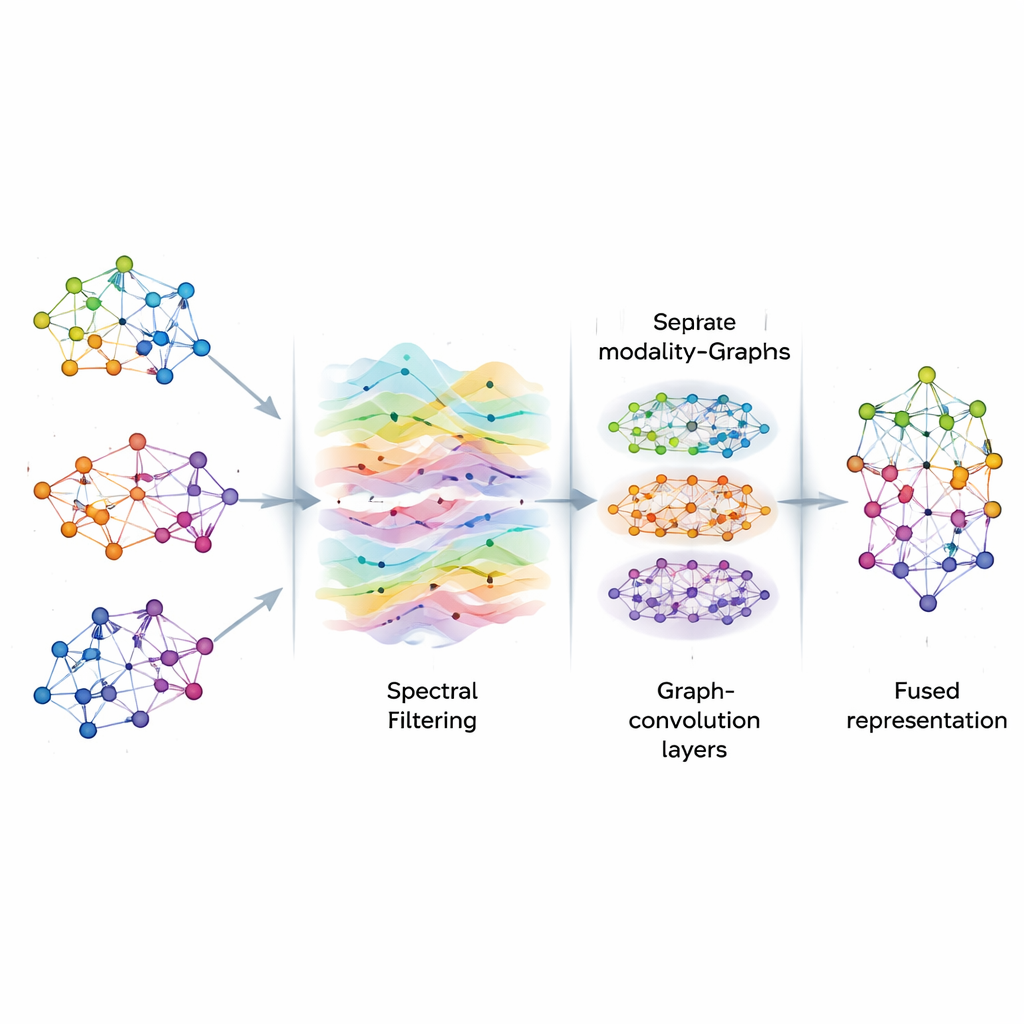
När graferna är byggda behandlar AGSP-DSA informationen på dem som signaler som flödar genom ett nätverk, liknande hur ljudvågor rör sig i luften. Med verktyg från grafsignalsbehandling utförs en sorts smart filtrering som framhäver användbara mönster samtidigt som brus reduceras. Istället för att direkt beräkna kostsamma matrisoperationer använder metoden matematiska genvägar baserade på Chebyshev-polynom för att approximera hur signaler bör jämnas ut på grafen. Denna process hjälper modellen att fokusera på konsekventa, meningsfulla kopplingar mellan prover — till exempel upprepade känslomässiga signaler över olika klipp — utan att distraheras av slumpmässiga variationer eller saknade data.
Lära mönster i flera skalor
Efter filtreringen matar AGSP-DSA grafsignalerna in i en stapel av Graph Convolutional Networks, som är specialiserade neurala nätverk utformade för grafformade data. Varje lager låter en nod uppdatera sin representation genom att blanda information från sina grannar, först från närliggande punkter och sedan successivt från mer avlägsna. Genom att stapla flera lager lär sig systemet mönster på flera skalor: lokala detaljer som subtila tonförändringar, samt bredare trender som spänner över många prover. Utdata från grafen som finns inom varje modalitet och grafen som knyter modaliteterna samman kombineras och producerar rika representationer som kodar både finmaskiga och globala relationer mellan bilder, ljud och ord.
Låta datan avgöra vilken modalitet som är viktigast
En central utmaning i multimodal inlärning är att inte alla källor är lika användbara hela tiden. Ibland bär ansiktsuttryck budskapet; andra gånger dominerar röstens ton eller texten. AGSP-DSA hanterar detta med en semantiskt medveten uppmärksamhetsmekanism. För varje prov jämförs funktionerna från varje modalitet mot ett semantiskt ankare, såsom måletiketten eller en sammanfattning av betydelsen, och tilldelas en vikt som speglar hur informativ modaliteten är i det aktuella sammanhanget. Ett grindsteg justerar sedan dessa bidrag ytterligare, så att systemet kan tona ner opålitliga eller saknade signaler. Den fusionerade, uppmärksamhetsviktade representationen matas till ett slutligt prediktionslager som kan hantera uppgifter som sentimentsklassificering, händelsedetektion eller filmgenresklassificering.
Prestanda i verkliga världen
Ramverket testas på tre krävande referensdataset: en stor samling åsiktsvideor för sentiment- och emotionanalys (CMU-MOSEI), ett audio-visuellt händelsedataset (AVE) och en filmsamling som kombinerar affischer och synopsis (MM-IMDb). I samtliga fall överträffar AGSP-DSA både traditionella fusionsmetoder och moderna transformator- och grafbaserade konkurrenter. Det når över 95 % noggrannhet på sentimentsklassificering och visar liknande starka förbättringar för händelsedetektion och filmgenresprediktion. Viktigt är att metoden förblir robust när vissa modaliteter delvis saknas eller är brusiga, och gör det utan att orsaka för stora beräkningskostnader. Upprepade experiment visar att dess prestanda är stabil och inte beror på lyckosamma slumpval under träning.
Vad detta innebär för vardagliga AI-system
I vardagliga termer erbjuder AGSP-DSA ett smartare sätt för AI-system att samtidigt lyssna, titta och läsa, samtidigt som de är motståndskraftiga när en av dessa kanaler sviktar. Genom att representera multimodala data som sammankopplade grafer, rensa signalerna som flödar genom dem och låta modellen dynamiskt avgöra vilken modalitet som är att lita på, levererar metoden mer exakta och pålitliga beslut. Det gör den till en lovande byggsten för framtida tillämpningar såsom känslo-känsliga virtuella assistenter, robust videoövervakning, rikare innehållsrekommendationer och andra system som måste tolka komplexa, ofullkomliga multimediaströmmar.
Citering: Karthikeya, K.V., Rajasekaran, A.S., Das, A.K. et al. Adaptive graph signal processing for robust multimodal fusion with dynamic semantic alignment. Sci Rep 16, 12206 (2026). https://doi.org/10.1038/s41598-026-44641-y
Nyckelord: multimodal fusion, graph neural networks, sentiment analysis, audio-visual events, multimedia classification