Clear Sky Science · zh
通过视频到视频条件扩散实现的时序一致低光人脸视频增强
将面孔从黑暗中呈现出来
任何尝试在夜间拍摄人物的人都知道,结果可能是一团模糊、颗粒感很强的画面:面孔隐没在阴影中,颜色失真,细节在帧与帧之间闪烁不定。本文提出了 DL-Diff,一种新的人工智能方法,可以将这种昏暗、嘈杂的人脸视频转换为明亮、自然的片段,播放时平滑连贯,不会出现早期技术常见的闪烁和颤动。这项工作对日常摄影、家庭安防摄像头,甚至必须在弱光下识别行人的驾驶辅助系统都具有实际意义。
为何夜间视频如此棘手
低光人脸视频提出了双重挑战。一方面,由于到达相机传感器的光子很少,每帧都遭受严重噪声、颜色偏移和细节丢失。另一方面,视频不仅仅是一叠图片:我们对帧与帧之间亮度或形状的突变非常敏感。许多现有方法将每帧单独处理或依赖粗糙的帧间运动估计。那样做或许有些帮助,但往往会留下闪烁或变形的面孔,尤其是在场景极其昏暗且运动复杂时。
一种新的暗到亮流水线
DL-Diff 将低光增强视为完整的视频到视频转换,而不是逐帧修补。它基于最初用于从文本提示生成图像和短视频的强大“扩散”生成器。这些生成器通过从随机噪声开始,逐步将其精炼为清晰图像来工作。DL-Diff 将这样的模型重新用于以实际的暗输入视频作为引导,而非文本描述。通过在紧凑的内部表示空间中操作而不是直接在像素上进行,系统能够去除噪声并填补缺失细节,同时仍尊重原始素材的整体内容。
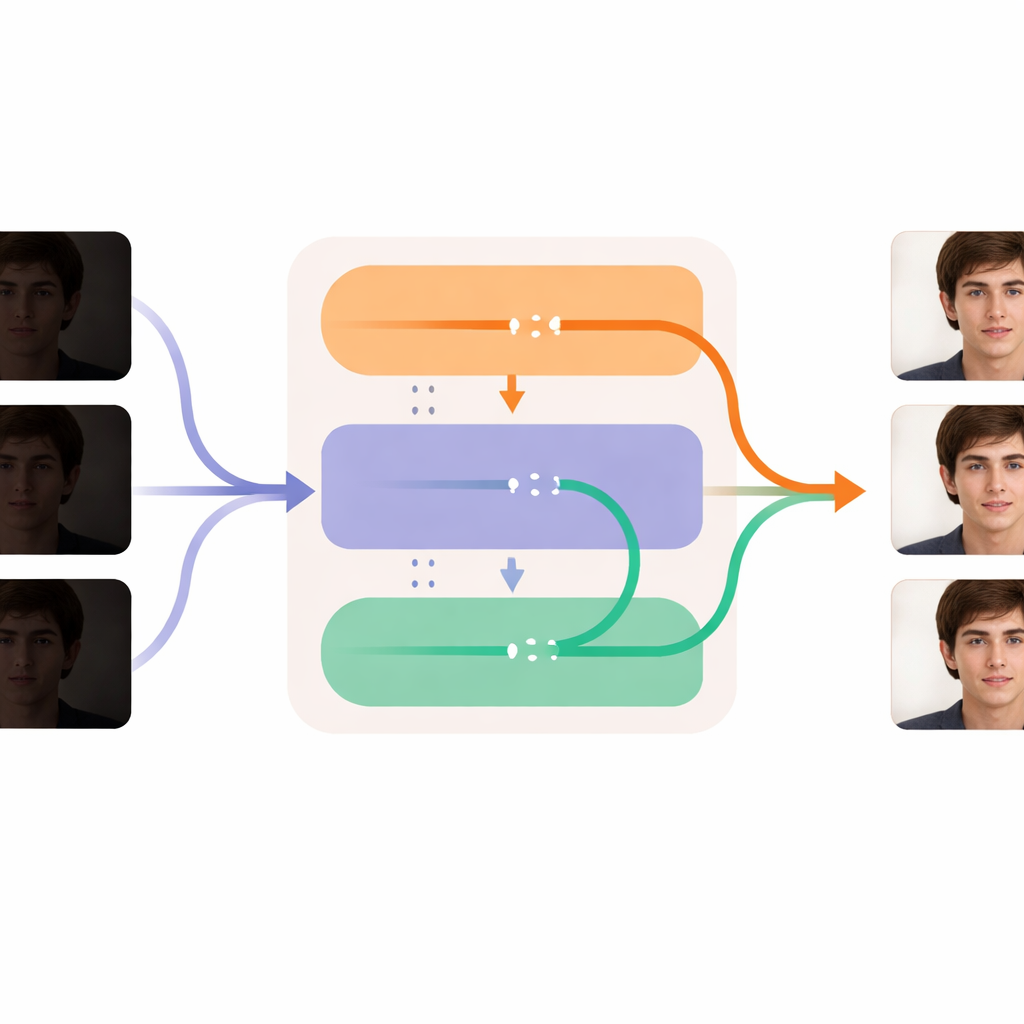
锐化每一帧并保持时间平滑
DL-Diff 的核心分为两个协同模块,反映了我们观看视频的体验方式。“修复”部分关注空间:它查看每一帧并在生成器的内部层注入额外细节、纹理和更真实的颜色,以补偿黑暗中丢失的信息。该模块首先在单张图像对上训练,学习暗淡人脸在适当照明下应有的样子。“时序”部分关注时间:它在模型中重塑,在处理的关键阶段比较跨帧信息并将它们轻柔地对齐。这有助于使表情、头部运动和光照变化在帧与帧之间平稳演变,而不是颤动或突变。两个模块协同工作,使系统能够在提亮并清理每一帧的同时,保持人物身份和动作在整个视频中的稳定性。
阶段性训练模型
为了在不破坏预训练生成器已学知识的情况下充分利用其能力,作者将 DL-Diff 的训练分为三步。首先,在保持网络其余部分冻结的情况下,训练修复模块以修复单张暗图像。接着,在干净、正常光照的视频上训练时序模块,使其在不受低光伪影干扰的情况下学习自然运动的行为。最后,在成对的暗视频和亮视频上对两个模块进行联合微调。这种类课程化的流程缩小了静态图像与动态影像之间的差距,并帮助系统在输入极其嘈杂或几乎全黑时仍保持稳定。

在黑暗中呈现更清晰、更自然的人脸
在两个公开的真实低光视频数据集上,DL-Diff 比几种领先方法产生了更清晰的人脸和更自然的颜色,并且在时间维度上可见的闪烁更少。与人类感知对齐的视觉质量度量偏好 DL-Diff,尽管一些较旧的技术在严格的像素级准确度上得分略好。这一权衡反映了设计取向:新方法更强调观众感觉正确的视觉效果,而非精确匹配每个像素。主要缺点是速度——由于扩散模型通过多步迭代精炼每一帧,处理速度比简单方法慢——但作者指出,更新更快的变体在未来可能缓解这一点。总体而言,DL-Diff 表明,经过谨慎调整的现代生成模型能够将几乎不可用的暗色视频转变为明亮、稳定的画面,适用于监控、摄影和其他现实应用。
引用: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
关键词: 低光视频, 人脸增强, 扩散模型, 视频修复, 时序一致性