Clear Sky Science · en
Temporally consistent low-light face video enhancement via video-to-video conditional diffusion
Bringing Faces Out of the Dark
Anyone who has tried to film a person at night knows the result can be a murky, grainy mess: faces disappear into the shadows, colors look wrong, and details flicker from frame to frame. This paper introduces DL-Diff, a new artificial intelligence method that turns such dark, noisy face videos into bright, natural-looking clips that play smoothly, without the distracting shimmer and flicker that often plague earlier techniques. The work matters for everyday photography, home security cameras, and even driver-assistance systems that must recognize people in poor light.
Why Nighttime Videos Are So Hard
Low-light face videos pose a double challenge. On the one hand, each frame is damaged by heavy noise, color shifts, and lost details because very few photons reach the camera sensor. On the other hand, a video is not just a stack of pictures: our eyes are highly sensitive to jumps in brightness or shape from one frame to the next. Many existing methods treat each frame separately or rely on rough motion estimates between frames. That can help a bit, but it often leaves behind flickering or warped faces, especially when the scene is extremely dark and the motion is complex.
A New Dark-to-Light Pipeline
DL-Diff tackles the problem by treating low-light enhancement as a full video-to-video transformation instead of a frame-by-frame touch-up. It builds on powerful "diffusion" generators originally trained to create images and short videos from text prompts. These generators work by starting from random noise and gradually refining it into a clean picture. DL-Diff repurposes such a model so that, instead of following a text description, the generator is guided by the actual dark input video. By operating in a compact internal representation rather than directly on pixels, the system can carve away noise and hallucinate missing details while still respecting the overall content of the original footage.
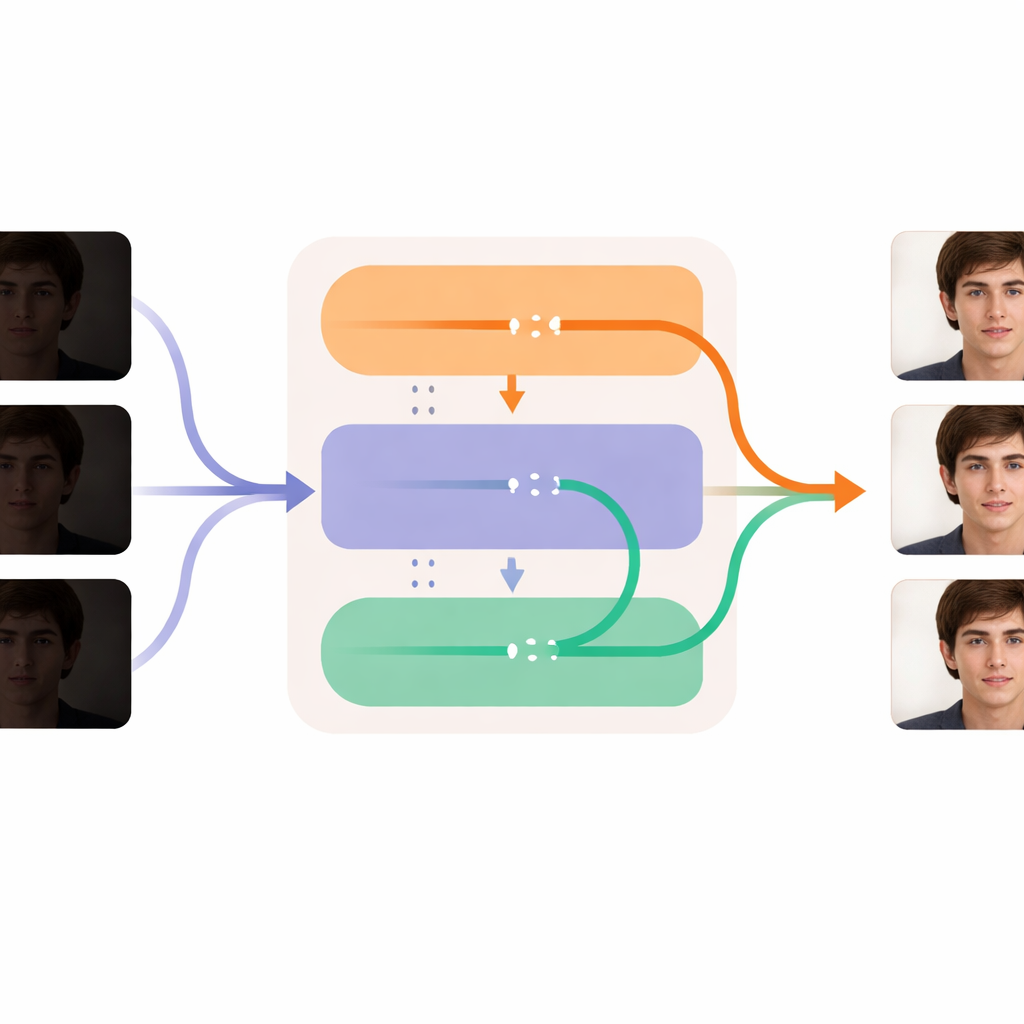
Sharpening Each Frame While Keeping Time Smooth
The heart of DL-Diff is split into two cooperating modules that mirror how we experience video. The "restoration" part focuses on space: it looks at each frame and injects extra detail, texture, and more realistic colors into the generator’s internal layers, compensating for what was lost in the dark. This module is trained first on individual image pairs, learning how a dim face should look once properly lit. The "temporal" part focuses on time: it reshapes the model so that, at key stages in the processing, it can compare information across frames and gently pull them into alignment. This helps expressions, head movements, and lighting changes evolve smoothly from frame to frame instead of jittering or popping. Together, these modules allow the system to brighten and clean each frame while keeping the person’s identity and motion stable across the whole video.
Teaching the Model in Stages
To make the most of the large pre-trained generator without disturbing what it has already learned, the authors train DL-Diff in three steps. First, they teach the restoration module to fix single dark images while the rest of the network stays frozen. Next, they train the temporal module on clean, normally lit videos so it can learn how natural motion behaves without being confused by low-light artifacts. Finally, they fine-tune both modules together on paired dark and bright videos. This curriculum-like process narrows the gap between still images and moving footage and helps the system remain stable even when the input is extremely noisy or nearly black.

Sharper, More Natural Faces in the Dark
On two public datasets of real low-light videos, DL-Diff produces clearer faces with more natural colors than several leading methods, and it does so with less visible flicker over time. Human-aligned measures of visual quality favor DL-Diff, even though some older techniques score slightly better on strict pixel-by-pixel accuracy. The trade-off reflects a design choice: the new method emphasizes what looks right to a viewer rather than matching every pixel exactly. The main drawback is speed—because diffusion models refine each frame through many steps, processing is slower than simpler approaches—but the authors note that newer, faster variants could ease this in the future. Overall, DL-Diff shows that modern generative models, when carefully adapted, can turn almost unusable dark face videos into bright, stable footage suitable for surveillance, photography, and other real-world applications.
Citation: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Keywords: low-light video, face enhancement, diffusion models, video restoration, temporal consistency