Clear Sky Science · sv
Tidsmässigt konsekvent förbättring av mörka ansiktsvideor via video-till-video villkorad diffusion
Lyfter fram ansikten ur mörkret
Alla som försökt filma en person på natten vet att resultatet ofta blir grumligt och kornigt: ansikten försvinner i skuggorna, färgerna blir felaktiga och detaljer fladdrar mellan bildrutorna. Denna artikel presenterar DL-Diff, en ny AI-metod som förvandlar sådana mörka, brusiga ansiktsvideor till ljusare, mer naturliga klipp som spelas upp jämnt, utan det störande skimret och flimmer som ofta plågar tidigare tekniker. Arbetet är viktigt för vardagsfotografering, övervakningskameror hemma och även för förarassistanssystem som måste känna igen människor i svagt ljus.
Varför nattvideor är så svåra
Videor med svagt ljus innebär en dubbel utmaning. Å ena sidan är varje bildruta skadad av kraftigt brus, färgskiftningar och förlorade detaljer eftersom mycket få fotoner når kamerasensorn. Å andra sidan är en video inte bara en stapel bilder: våra ögon är mycket känsliga för hopp i ljusstyrka eller form från en bildruta till nästa. Många befintliga metoder behandlar varje bildruta separat eller förlitar sig på grova rörelseuppskattningar mellan rutor. Det kan hjälpa lite, men lämnar ofta kvar flimmer eller förvrängda ansikten, särskilt när scenen är extremt mörk och rörelserna komplexa.
En ny pipeline från mörkt till ljust
DL-Diff angriper problemet genom att behandla förbättring av svagt ljus som en fullständig video-till-video-transformation i stället för en efterbearbetning bildruta för bildruta. Den bygger på kraftfulla «diffusions»generatorer som ursprungligen tränats för att skapa bilder och korta videor från textbeskrivningar. Dessa generatorer fungerar genom att börja från slumpmässigt brus och gradvis förfina detta till en ren bild. DL-Diff återanvänder en sådan modell så att generatorn, i stället för att följa en textbeskrivning, styrs av den faktiska mörka inmatningsvideon. Genom att arbeta i en kompakt intern representation i stället för direkt på pixlar kan systemet avlägsna brus och hallucinera saknade detaljer samtidigt som det fortfarande respekterar det övergripande innehållet i originalfilmen.
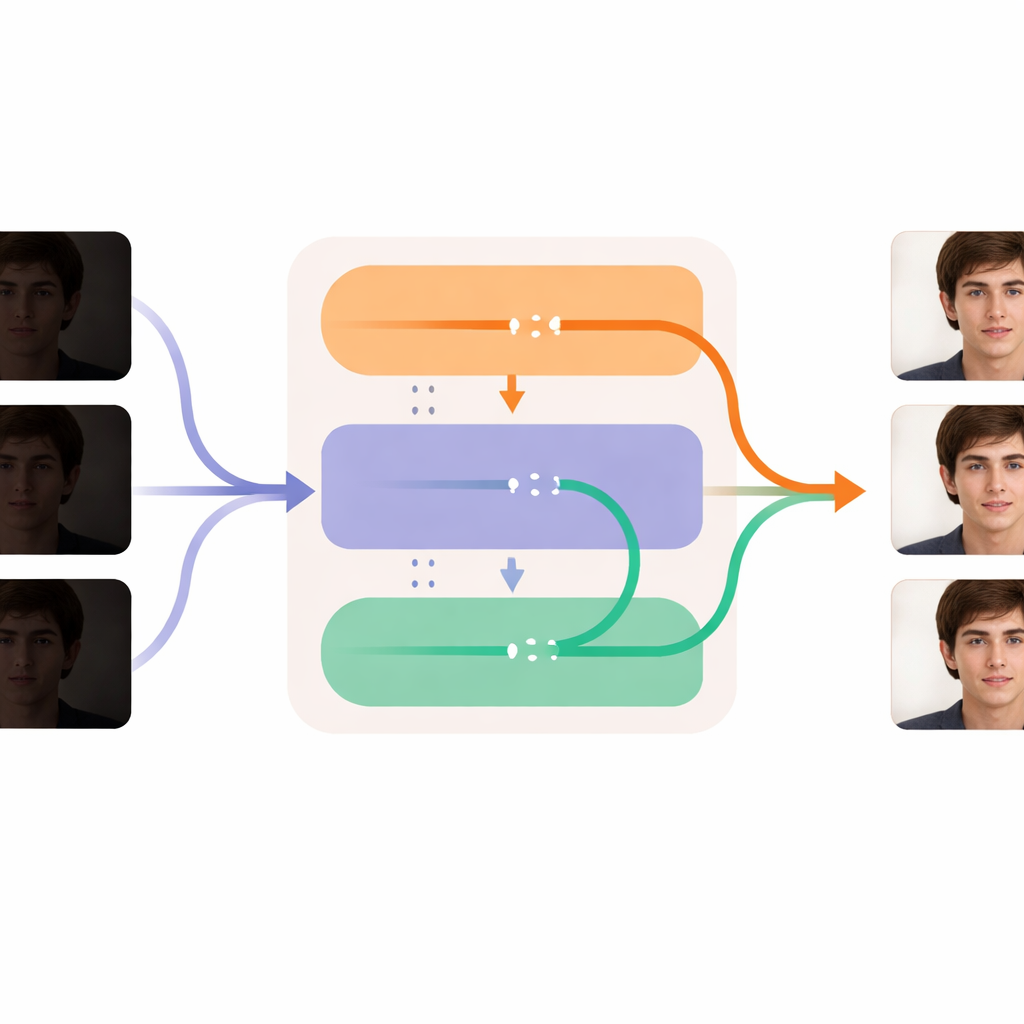
Skärper varje bildruta samtidigt som tiden hålls jämn
Kärnan i DL-Diff är uppdelad i två samverkande moduler som speglar hur vi upplever video. "Restaureringsdelen" fokuserar på rummet: den tittar på varje bildruta och injicerar extra detalj, textur och mer realistiska färger i generatorns interna lager, för att kompensera för det som förlorats i mörkret. Denna modul tränas först på individuella bildpar och lär sig hur ett svagt belyst ansikte bör se ut när det är korrekt upplyst. "Temporala" delen fokuserar på tiden: den omformar modellen så att den i nyckelstadier i bearbetningen kan jämföra information över rutor och varsamt föra dem i linje med varandra. Detta hjälper till att få uttryck, huvudrörelser och ljusförändringar att utvecklas jämnt från bildruta till bildruta i stället för att rycka eller poppa. Tillsammans gör dessa moduler att systemet kan ljusa upp och rengöra varje bildruta samtidigt som personens identitet och rörelse förblir stabil över hela videon.
Lär modellen i etapper
För att få ut det mesta av den stora förtränade generatorn utan att rubba det den redan lärt sig, tränar författarna DL-Diff i tre steg. Först lär de restaureringsmodulen att korrigera enskilda mörka bilder medan resten av nätverket hålls fryst. Därefter tränar de den temporala modulen på rena, normalt belysta videor så att den kan lära sig hur naturlig rörelse beter sig utan att förvirras av låg-ljusartefakter. Slutligen finjusterar de båda modulerna tillsammans på parade mörka och ljusa videor. Denna liknande en läroplan smala process minskar klyftan mellan stillbilder och rörligt material och hjälper systemet att förbli stabilt även när ingången är extremt brusig eller nästan svart.

Skarpare, mer naturliga ansikten i mörkret
På två offentliga dataset med verkliga svagt ljusa videor producerar DL-Diff tydligare ansikten med mer naturliga färger än flera ledande metoder, och gör det med mindre synligt flimmer över tid. Mänskligt anpassade mått för visuell kvalitet föredrar DL-Diff, även om vissa äldre tekniker presterar något bättre på strikt pixel-för-pixel-precision. Denna avvägning speglar ett designval: den nya metoden betonar vad som ser rätt ut för en betraktare snarare än att exakt matcha varje pixel. Huvudnackdelen är hastigheten—eftersom diffusionsmodeller förfinar varje bildruta genom många steg är bearbetningen långsammare än enklare angreppssätt—men författarna noterar att nyare, snabbare varianter kan lindra detta i framtiden. Sammanfattningsvis visar DL-Diff att moderna generativa modeller, när de anpassas omsorgsfullt, kan förvandla nästan oanvändbara mörka ansiktsvideor till ljusa, stabila filmer lämpliga för övervakning, fotografering och andra verkliga tillämpningar.
Citering: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Nyckelord: mörk video, ansiktsförbättring, diffusionsmodeller, videorestaurering, temporal konsistens